数据库: sqlserver2008r2
表: device_data
数据量:2000w行左右
表结构
CREATE TABLE [dbo].[device_data]( [Id] [int] IDENTITY(1,1) NOT NULL, [DeviceId] [char](12) NOT NULL, [SystemTick] [int] NOT NULL, [Sport] [int] NOT NULL, [Temperature] [int] NOT NULL, [Voltage] [int] NOT NULL, [UploadTime] [datetime] NOT NULL, [CollectorMac] [char](8) NOT NULL, CONSTRAINT [PK__device_d__3214EC0770FDBF69] PRIMARY KEY CLUSTERED ( [Id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY]
索引情况:分别有两个联合索引
idx_deviceid(DeviceId,UploadTime)
idx_collector(CollectorMac,UploadTime)
问题:这张表上传的数据都是随上传时间递增,批量有序插入进去。但是 最近几天日志经常出现插入数据超时,然后去分析了一下数据库,发现对外接口出现了慢 sql导致了死锁,
慢sql是where条件在某些情况下没有加上时间筛选过滤,2000万的表导致非常慢,于是进行了优化,优化的时候变出现了下面的两条sql语句
这两个索引对应着两个接口 查询语句分别是:
select top 100 Id,DeviceId,Sport,Temperature,CollectorMac,UploadTime from device_data where [DeviceId]='C9C810B18272' and UploadTime>'2020-12-01 15:16:55.000' order by UploadTime desc; 和 select top 100 Id,DeviceId,Sport,Temperature,CollectorMac,UploadTime from device_data where [CollectorMac]='95DE5F0B' and UploadTime>'2020-12-01 15:16:55.000' order by UploadTime desc;
现在遇到一个情况是 相同的where条件下 如果我Order by Id Desc 就会发现返回结果中会比order by UploadTime desc慢一点,我一开始不太理解为啥会出现这个情况。
于是想到了sqlserver的查询分析器来分析一下具体的sql执行计划
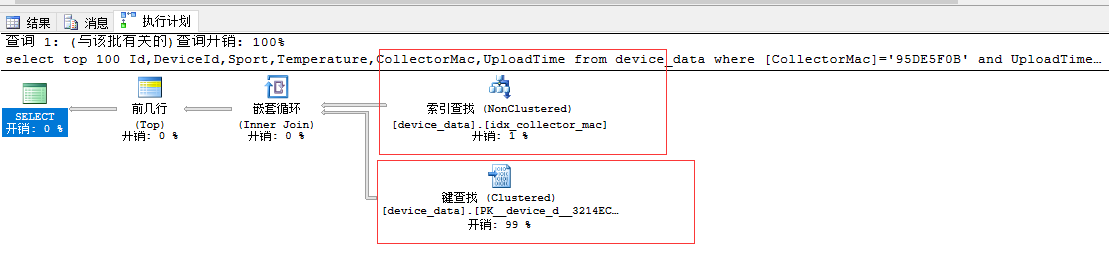
1,首先我来执行order by UploadTime desc的语句来看一下具体的执行计划
dbcc dropcleanbuffers set statistics io on select top 100 Id,DeviceId,Sport,Temperature,CollectorMac,UploadTime from device_data where [CollectorMac]='95DE5F0B' and UploadTime>'2020-12-01 15:16:55.000' order by UploadTime desc; set statistics io off
具体执行计划为:
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。 (100 行受影响) 表 'device_data'。扫描计数 1,逻辑读取 1899 次,物理读取 5 次,预读 24 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响)
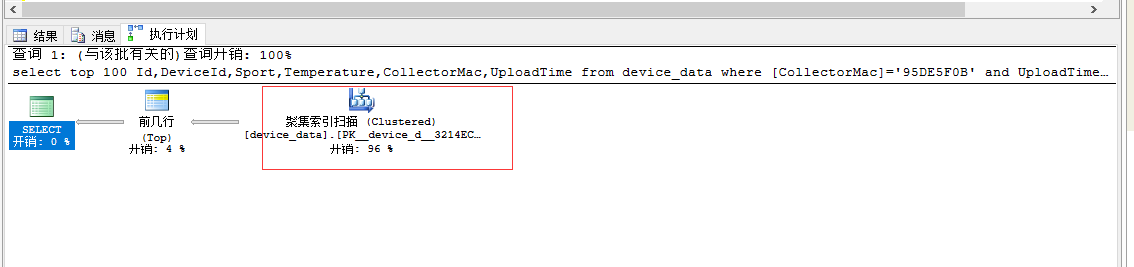
2,再来看一下order by Id desc的具体执行计划
dbcc dropcleanbuffers set statistics io on select top 100 Id,DeviceId,Sport,Temperature,CollectorMac,UploadTime from device_data where [CollectorMac]='95DE5F0B' and UploadTime>'2020-12-01 15:16:55.000' order by Id desc; set statistics io off
具体执行计划为:
DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。 (100 行受影响) 表 'device_data'。扫描计数 1,逻辑读取 40 次,物理读取 36 次,预读 4942 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。 (1 行受影响)
这里先说一下逻辑读取和物理读取等区别
那么,这几个词语代表什么意思呢?我们怎么根据这些来了解SQL语句或者存储过程的I/O过程呢?
预读:用于估计信息,去硬盘读取数据到缓存。
物理读:查询计划生成以后,如果发现缓存缺少所需要的数据,让缓存再次去读硬盘数据。如果内存里没有缓存数据或者执行计划(如果SQL语句发生了改变,
那么执行计划将不能重用,需要重新生成新的执行计划),那么SQLSERVER就要去硬盘读取这些数据,这个时候就是物理读取,我们大家都知道,硬盘速度
与内存速度根本不在一个数量级上,所以物理读是比较慢的。
逻辑读:SQLSERVER去内存里的缓存取数据或者执行计划,所以逻辑读是比较快的。
SQLSERVER存储的最小单位是页,每一页大小为8K,即8*1024=8192字节,SQLSERVER对页的读取是原子性的,即要么读完一页,要么完全不读。即使
仅仅要获得一条数据,也要读完该页,而页之间的数据组织结构为B树结构。所以SQLSERVER对于逻辑读,物理读,预读的单位是页。
可以看到bytime 走的是索引查找和键查找 并且大部分读取走的是逻辑读取
byid 走的是聚集索引扫描,并且大部分读取走的是预读取
看上面的介绍我们发现 逻辑读取走的是内存缓存,预读取是去硬盘读取数据到缓存然后再逻辑读取,在这一步我们基本确定了 byid慢的原因是读取了硬盘数据。
那么上图出现的索引查找和索引扫描这两者又有什么区别呢
查看了相关资料发现
Clustered Index Scan(聚集索引扫描)、Index Scan(非聚集索引扫描)

聚集索引扫描:聚集索引的数据体积实际是就是表本身,也就是说表有多少行多少列,聚集所有就有多少行多少列,那么聚集索引扫描就跟表扫描差不多,也要进行全表扫描,遍历所有表数据,查找出你想要的数据。
非聚集索引扫描:非聚集索引的体积是根据你的索引创建情况而定的,可以只包含你要查询的列。那么进行非聚集索引扫描,便是你非聚集中包含的列的所有行进行遍历,查找出你想要的数据。
Clustered Index Seek(聚集索引查找)、Index Seek(非聚集索引查找)

聚集索引查找和非聚集索引查找都是使用该图标。
聚集索引查找:聚集索引包含整个表的数据,也就是在聚集索引的数据上根据键值取数据。
非聚集索引查找:非聚集索引包含创建索引时所包含列的数据,在这些非聚集索引的数据上根据键值取数据。
Key Lookup(键值查找)

首先需要说的是查找,查找与扫描在性能上完全不是一个级别的,扫描需要遍历整张表,而查找只需要通过键值直接提取数据,返回结果,性能要好。
当你查找的列没有完全被非聚集索引包含,就需要使用键值查找在聚集索引上查找非聚集索引不包含的列。
我们发现byid引起全量扫描了 所以会慢很多
疑问:我的理解是既然我已经加了where条件去筛选数据了 order by Id还是 order by Uploadtime 是不是应该在我where筛选出来的数据中再去排序,为啥只是因为Orderby的不同,最终的执行计划差别这么大
我对理论方面不深入,只能从现象来解决问题,还请大佬们赐教
参考资料: