时隔几个月我才更新002篇,不是因为别的,没错是因为我太懒了!
之前我们说到了关于测试用例的设计或者测试的基本要素以及基本的职业素养,接下来我们说说关于一些常用工具的使用
Charls
之前说到过charls能够帮助我们抓包分析接口参数,那么他的具体原理是怎么实现的呢?下面我给大家讲解一下
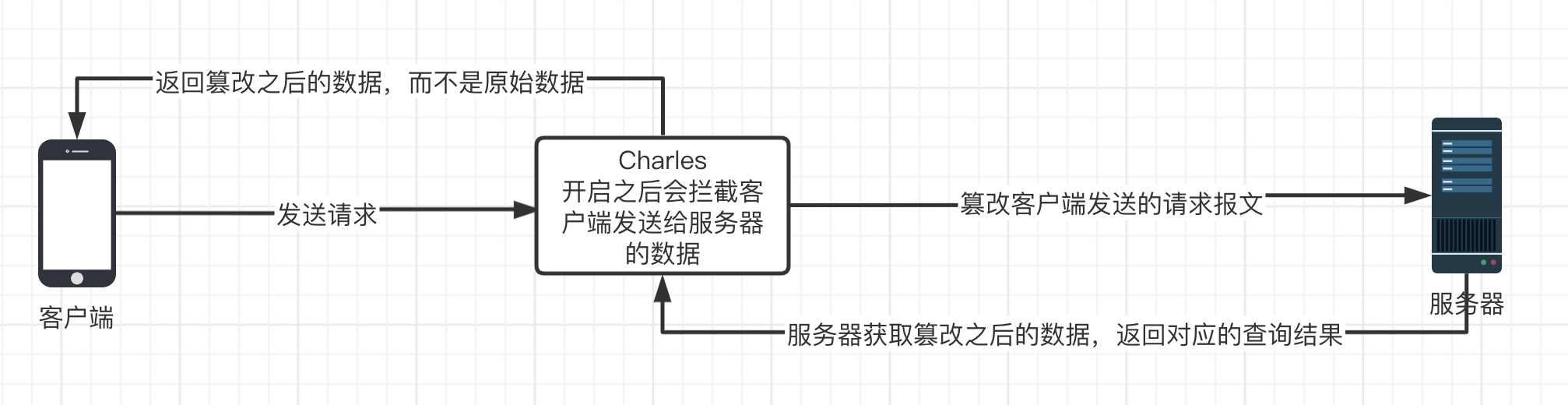
当客户端向服务器发起请求的时候,先到 charles 进行过滤,然后 charles 在把最终的数据发送给服务器;
注意:此时 charles 发给服务器的数据,不一定是客户端请求的数据;charles 在接到客户端的请求时可以自由的修改数据,甚至可以直接 Block 客户端发的请求;
服务器接收请求后的返回数据,也会先到 charles,经过 charles 过滤后再发给客户端;
同理:客户端接收的数据,不一定就是服务器返回的数据,而是 charles 给的数据;
那我们一般是用来做什么呢?
1 抓取 Http 和 Https 的请求和响应,抓包是最常用的了。 2 重发网络请求,方便后端调试,复杂和特殊情况下的一件重发还是非常爽的(捕获的记录,直接 repeat 就可以了,如果想修改还可以修改)。 3 修改网络请求参数(客户端向服务器发送的时候,可以修改后再转发出去)。 4 网络请求的截获和动态修改。 5 支持模拟慢速网络,主要是模仿手机上的 2G/3G/4G 的访问流程。 6 支持本地映射和远程映射,比如你可以把线上资源映射到本地某个文件夹下,这样可以方面的处理一些特殊情况下的 bug 和线上调试(网络的 css,js 等资源用的是本地代码,这些你可以本地随便修改,数据之类的都是线上的环境,方面在线调试); 7 可以抓手机端访问的资源(如果是配置 HOST 的环境,手机可以借用 host 配置进入测试环境)
那一般面试的时候会问什么?
1.你一般用charles干什么?
答:一般用来抓取接口,因为之前的测试的内容前后端都会涉及,charles也能够同时抓取,比较方便。主要是验证前端传递的参数是否有问题,以及后端返回参数,来判断是前端问题还是后端问题,再一个就是配合后
端服务器,查看报错日志。然后把数据发送给开发让他进行定位。
2.你觉得charles跟fiddler的区别在哪儿?
答:Fiddler只能运行在Windows平台,而Charles是基于Java实现的,基本上可以运行在所有主流的桌面系统,还有一个区别就是Fiddler开源免费、Charles是收费的。Charles树状结构呈现于屏幕,清晰易区
分,Fiddler默认按时间倒叙呈现所有接口数据,不易区分。其他的功能都大差不大,主要看个人爱好,那个方便就用那个
3.有没有使用过mock数据的情况?
答:一般需要造比较复杂的数据类型时候会用到mock,时间关系就可以直接mock一个想要的消息体然后模拟请求并发送。
3.1 选择你想Mock的请求,然后右键,点击“Save Responce”, 到某个目录,并以.json 后缀命名,然后保存。
3.2 选择接口右键,点击“Map Local...”,然后 choose 刚才保存的 json文件或者指定的 json文件,就可以把文件里的内容 Mock 返回给客户端了。注意(Query 里的内容可以清空,要不然只能mock特定参数的接口了)
4.我电脑上可以抓包,手机上为什么不行?
答:可能是手机上的证书安装的行,重新安装一下证书,如果还是不行,就查看是否配置的http/https的请求抓取,查看手机上的证书是否安装,安装完成之后需要去信任证书,不然也不能抓取到数据
5.有没有用过charles的断点,你是怎么做的?
答:选择你想要的接口并右键点击,点击BreakPoints,当你再次请求break的接口会出现一个界面,点击Edit Request,这个时候你就可以去修改请求参数或者请求头,然后点击Execute,然后就可以了,配合前端
页面查看修改之后的数据
Mysql
前面也是简单的提到了mysql。现在我们就来整合一下mysql会问道的问题,提供给大家食用
基本上大家对mysql应该也是有一知半解的,那么我们直接上!
增:insert into 表名(列名) values (数据); 如:在stu表中插入id为001,姓名为张三的学生,(insert into Stu(stu_id,stu_name) values (001,‘张三’);) 删:delete from 表名 where 指定数据; 如:在stu表中删除id为001,姓名为张三的学生:(detele from Stu where stu_id=‘001’ and stu_name = ‘张三’;)
改:update 表名 set 改变项 where 指定数据; 如:在stu表中修改id为001的学生姓名为“张三”:(update Stu set stu_name = ‘张三’ where stu_id=‘001’ ;) 查:select (查询项) from 表名 where 指定条件; 如:在stu表中查询id为001,姓名为“张三”的学生信息:(select * from Stu where stu_name = ‘张三’ and stu_id=‘001’ ;)
学生表(学生id,姓名,性别,分数))student(s_id, name, sex, score) 班级表(班级id,班级名称) class(c_id, c_name) 学生班级表(班级id,学生id) student_class(s_id,c_id) 1.查询一班得分在80分以上或者等于60,61,62的学生 2.査询所有班级的名称,和所有版中女生人数和女生的平均分。 答案: (1)SELECT s.s_id,s.name,s.score,sc.c_id,c.c_name from student s LEFT JOIN student_class sc on s.s_id = sc.s_id LEFT JOIN class c on sc.c_id=c.c_id where (s.score>80 or s.score in(60,61,62)) and c.c_name='一班'; (2)SELECT sc.s_id,c.c_name,COUNT(s.sex),AVG(s.score) from student_class sc LEFT JOIN class c on sc.c_id=c.c_id LEFT JOIN student s on sc.s_id = s.s_id where s.sex='女' group BY c.c_name ORDER BY c.c_id asc;
sql语句应该考虑哪些安全性? 答案: (1)防止sql注入,对特殊字符进行转义,过滤或者使用预编译的sql语句绑定变量。 (2)最小权限原则,特别是不要用root账户,为不同的类型的动作或者组建使用不同的账户。 (3)当sql运行出错时,不要把数据库返回的错误信息全部显示给用户,以防止泄漏服务器和数据库相关信息。
MySQL外连接、内连接的区别?
答案:
内连接 连接的数据表相对应的匹配字段完全相等的连接。连接关键字是 inner join
外连接 分为左外连接与右外连接、全连接。
左连接的结果集包括指定的左表全部数据与匹配的右表数据,右表中没匹配的全为空值.关键字 left join
右连接的结果集包含指定的右表全部数据与匹配的左边数据,左边中没匹配的全为空值.关键字 right join
全连接返回左右数据表的所有行.关键字 full join
什么是数据库事务? 答案: 单个逻辑单元执行的一系列操作,这些操作要么全做要么全不做,是不可分割的.事务的开始和结束用户是可以控制的,如果没控制则由数据库默认的划分事务.事务具有以下性质: (1)原子性 指一个事务要么全执行,要么全不执行.也就是说一个事务不可能执行到一半就停止了.比如:你去买东西,钱付掉了,东西没拿.这两步必须同时执行 ,要么都不执行. (2)一致性 指事务的运行并不改变数据库中的一致性.比如 a+b=10;a改变了,b也应该随之改变. (3)独立性 两个以上的事务不会出现交替运行的状态,因为这样可能导致数据的不一致 (4)持久性 事务运行成功之后数据库的更新是永久的
如果公司用的不止是mysql还设计到mongdb和其他类型的数据库怎么办?
Mongodb和Mysql的区别?
Mongodb是非关系型数据库(nosql ),属于文档型数据库。文档是mongoDB中数据的基本单元,类似关系数据库的行,多个键值对有序地放置在一起便是文档,语法有点类似javascript面向对象的查询语言,它是一个面向集合的,模式自由的文档型数据库。
优点:快速!在适量级的内存的Mongodb的性能是非常迅速的,它将热数据存储在物理内存中,使得热数据的读写变得十分快。高扩展性,存储的数据格式是json格式!
缺点:mongodb不支持事务操作 mongodb占用空间过大 开发文档不是很完全,完善
mysql:
优点:在不同的引擎上有不同 的存储方式。查询语句是使用传统的sql语句,拥有较为成熟的体系,成熟度很高。开源数据库的份额在不断增加,mysql的份额页在持续增长。
缺点:在海量数据处理的时候效率会显著变慢。
Mysql跟Redis的区别
mysql和redis的区别?
----------------------------------------------------------------------------------------
mysql是关系型数据库,主要用于存放持久化数据,将数据存储在硬盘中,读取速度较慢。
redis是NOSQL,即非关系型数据库,也是缓存数据库,即将数据存储在缓存中,缓存的读取速度快,能够大大的提高运行效率,但是保存时间有限
----------------------------------------------------------------------------------------
mysql用于持久化的存储数据到硬盘,功能强大,但是速度较慢
redis用于存储使用较为频繁的数据到缓存中,读取速度快
----------------------------------------------------------------------------------------
弱网测试
大家都比较关注的弱网测试,那我们为什么要去做弱网测试呢?
弱网测试,属于健壮性测试的内容,为什么要做呢?尤其是现在的人们更习惯在地铁里,公交上,甚至是电梯,车库等等的场景里去关注一些新闻,看看小说,直播,玩游戏等等。在这个时候,我们就需要针对这些场景,去关注一下应用的运行状态,以及弱网环境下,出现丢包、延时软件的处理机制,避免造成用户的流失。
首先,只要搭建出来弱网环境,模拟一个弱网环境即可。可以通过软硬件方式两种。软件方式利用模拟网络参数来配置弱网环境,就可以达到目的。你也可以选择第三方,比如,Charles , Network link Conditioner 。 在各类网络软件中,主要就是对带宽、丢包、延时等进行模拟弱网环境。但是方式是由一定的弊端的,不是非常接近弱网络环境,想要更接近弱网环境,例如大多数专项测试,会更倾向于通过硬件方式来协助测试,但这种方式又会变得很麻烦,都是通过「树莓派」网维协助搭建!如果出现有些无法模拟的情况,只能靠人工移动到电梯、地铁等信号比较弱的地方。补充一点,软件方式的成本低且实施起来容易操作。
弱网测试的思路
弱网功能测试:2G/3G/4G、高延时、高丢包
无网状态测试:断网功能测试、本地数据存储
用户体验关注:响应时间、页面呈现&超时文案&超时重连、安全及大流量风险
网络切换测试:Wifi----4G/3G/2G-----无网多状态切换
测试点:
1 这部分主要是进行几个不同网络场景的切换。 2 包括wifi-2G/3G/4G、wifi-无网、2G/3G/4G-wifi、2G/3G/4G-无网、无网-2G/3G/4G、无网-wifi等。 3 主要关注页面的显示与交互,尤其是弱网到wifi,wifi到弱网的情况,是否会有页面的crash以及显示的错乱、session是否一致、请求堆积处理等。
用户体验:
弱网测试的目的就是尽可能保证用户体验,关注的关键点包括:
1)页面响应时间是否可以接受,关注包括热启动、冷启动时间、页面切换、前后台切换、首字时间,首屏时间等。 2)页面呈现是否完成一致。 3)超时文案是否符合定义,异常信息是否显示正常。 4)是否有超时重连。 5)安全角度:是否会发生dns劫持、登陆ip更换频繁、单点登陆异常等。 6)大流量事件风险:是否会在弱网下进行更新apk包、下载文件等大流量动作。
弱网测试对数据结果造成的影响
1、 现象:用户登录应用时下载初始化数据,下载过程中因网速太慢点击取消并重新登录,数据初始化完成后出现重复,造成数据不一致。
原因:数据下载过程中、下载失败后,未进行数据回滚,中止后重新下载,出现数据重复
解决方案:通过事务处理数据下载逻辑,下载失败后,应用本地数据库进行数据回滚。
2、 现象:用户点击数据上传,数据上传过程中网络弱且不稳定,基于联网状态自动触发数据上传,导致出现数据重复写入,形成脏数据
原因:数据上传过程中,由于失败重传机制,会出现连续两次写操作,并且未做唯一识别处理
解决方案:根据数据特性,对可能造成脏数据的地方,通过关键字段,例如创建时间,key-value值等生成hash键,标记记录唯一性,即数据写入时,检查hash键是否存在,如果已经存在,当前重复数据丢弃。
3、 现象:在弱网环境下,用户输入用户名和密码点击登录,应用链接超时返回用户名和密码错误提示。
原因:在弱网环境下的连接超时后,按照强网业务逻辑处理,导致返回超时异常。
解决方案: 弱网连接超时后,检查应用本地数据库是否有用户登录信息,若存在,获取应用本地用户信息进行登录。
4、 现象:在弱网环境下,用户输入用户名和密码后点击登录,登录过程中应用崩溃并且闪退。
原因:弱网环境下数据下载超时,加载数据严重依赖于后来的异步加载。数据还没来得及返回,应用跳转到下个activity,导致崩溃。
解决方案:健壮数据加载流程,通过标记后台数据下载状态加载界面,依赖数据下载完成后,再进行页面跳转。
5、 现象:弱网络环境下,用户请求页面响应时间较长,等待的过程中,页面上的部分控件仍然可以操作,当用户点击控件时,出现应用闪退现象;
原因:没有对数据加载流程进行判断,直接暴露控件可控,当出现依赖数据的控件操作时,没有在数据返回前做兼容处理。
解决方案:在数据加载过程中,设置页面对外暴露的控件为“不可操作”,当数据加载完再释放。
6、 现象:在弱网环境下,用户第一次输入搜索关键字没有得到响应后,再次输入全新关键字并发送请求,等待搜索结果返回后,当前结果页被之前的关键字搜索结果刷新覆盖
原因:中间的请求返回较慢,显示最终的结果后,之前请求返回的数据应不做处理。
解决方案:对异步请求未完成的任务进行cancel.
本文仅代表作者观点,系作者@罐装七喜 发表。欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
https://www.cnblogs.com/yushengaqingzhijiao/p/15014599.html
引用链接:
https://blog.csdn.net/zhusongziye/article/details/83720809
https://blog.csdn.net/qq_41625341/article/details/82941787
https://blog.csdn.net/qq284489030/article/details/105942230?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162640107516780261933568%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=162640107516780261933568&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-105942230.pc_search_result_before_js&utm_term=%E4%B8%BA%E4%BB%80%E4%B9%88%E8%A6%81%E8%BF%9B%E8%A1%8C%E5%BC%B1%E7%BD%91%E6%B5%8B%E8%AF%95&spm=1018.2226.3001.4187
https://blog.csdn.net/weixin_34025151/article/details/90219102?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162640107516780261933568%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=162640107516780261933568&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-90219102.pc_search_result_before_js&utm_term=%E4%B8%BA%E4%BB%80%E4%B9%88%E8%A6%81%E8%BF%9B%E8%A1%8C%E5%BC%B1%E7%BD%91%E6%B5%8B%E8%AF%95&spm=1018.2226.3001.4187