结合CUDA范例精解以及CUDA并行编程。由于正在学习CUDA,CUDA用的比较多,因此翻译一些个人认为重点的章节和句子,作为学习,程序将通过NVIDIA K40服务器得出结果。如果想通过本书进行CUDA编程,又不太懂CUDA和GPU的架构,可以将这个博客作为入门博客(但是希望你能有些基础,因为我介绍的并不是特别全面,只是捡了一些我困惑很久后来明白的知识点,如果完全不懂GPU的话,建议通读本书和介绍GPU的架构的书),我尽量在一个月更新完这本书的中文内容(部分)并补充一些自己的认识。欢迎大家评论和提问,转载请注明出处。
吐槽:书本有些地方英文过于书面化,真的不太容易让初学者理解。

正文
重点背景介绍:
Unlike previous generations that partitioned computing resources into vertex and pixel shaders, the CUDA Architecture included a unified shader pipeline, allowing each and every arithmetic logic unit (ALU) on the chip to be marshaled by a program intending to perform general-purpose computations. Because NVIDIA intended this new family of graphics processors to be used for general purpose computing, these ALUs were built to comply with IEEE requirements for single-precision floating-point arithmetic and were designed to use an instruction set tailored for general computation rather than specifically for graphics.
不同于之前将计算资源分配到顶点和像素着色器上(的架构),如今,CUDA架构包含了统一渲染总线,试图让每一个在芯片上的ALU算术逻辑单元都执行通用计算。因为NVIDIA公司(表示)这一新系列的图形处理器可用于通用计算,并且这些部件建立了符合IEEE单精度浮点运算的要求,因此为通用计算设计了一个指令集,且不是专门为了图形而设计的。
Furthermore, the execution units on the GPU were allowed arbitrary read and write access to memory as well as access to a software-managed cache known as shared memory. All of these features of the CUDA Architecture were added in order to create a GPU that would excel at computation in addition to performing well at traditional graphics tasks.
此外,在GPU上,执行单元可以任意读写访问的内存以及访问管理软件的缓存被称为共享内存。所有的这些CUDA架构的(设计)特点就是为了创造一个能擅长除了传统的图形计算的GPU(即,在通用计算等领域上也能够发挥更大的作用)。
第一章中,分别介绍了并行计算等背景、并行计算的重要性、GPU计算的产生崛起、早期的GPU计算以及CUDA在医学成像、计算流体动力学和环境科学领域的一些背景介绍,感兴趣可细读,不过个人感觉没什么用。关于安装CUDA网上教程多的是,不想重复赘述。不过提一点注意:你的电脑显卡必须是英伟达。
第二章主要是介绍安装的一些组件、需要的编译器gcc、g++等等,如果已经装好了,个人觉得也不需要看了。
第三章第一个例子
#include "../common/book.h"
int main()
{
printf("hello world!
");
return 0;
}
上面这个例子和你所写的所有的C代码一样,但是它却是一个CUDA程序,原因是,他是在host端执行的程序代码。这里我们引出了一个概念:host端和device端。device执行的CUDA的核函数,host端执行的是CPU上的执行代码。下图中可以看出如何写一个设备端的代码。
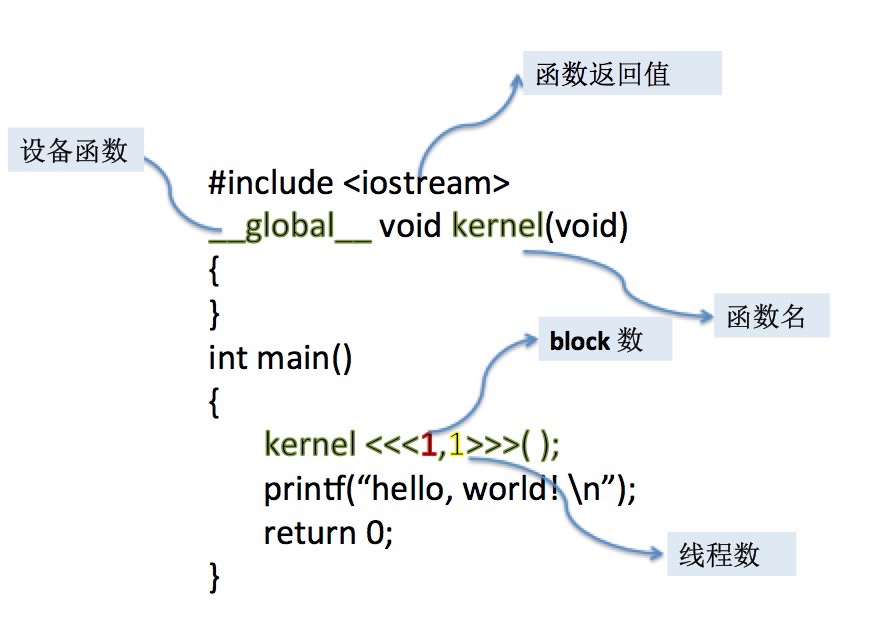
This program makes two notable additions to the original “Hello, World!”
example:
• An empty function named kernel() qualified with __global__
• A call to the empty function, embellished with <<<1,1>>>
上面那段程序和一开始的那个"hello world"相比主要有2个额外值得注意的地方。
• 一个不带参数的空 kernel()函数 和它的前缀 __global__ 关键字
• 通过<<<1,1>>> 和kernel函数建立联系
As we saw in the previous section, code is compiled by your system’s standard C compiler by default. For example, GNU gcc might compile your host code on Linux operating systems, while Microsoft Visual C compiles it on Windows systems. The NVIDIA tools simply feed this host compiler your code, and everything behaves as it would in a world without CUDA.
正如我们在前一节所看到的,代码是由您系统标准的编译器默认的。例如,GNU GCC可能在Linux操作系统下编译你的主机代码,而微软的Visual C是基于Windows系统下编译的。NVIDIA的工具只是提供(feed)你的代码给主机编译者(编译器),接下来的行为是没有任何CUDA的。
Now we see that CUDA C adds the __global__ qualifier to standard C. This mechanism alerts the compiler that a function should be compiled to run on a device instead of the host. In this simple example, nvcc gives the function kernel() to the compiler that handles device code, and it feeds main() to the host compiler as it did in the previous example. So, what is the mysterious call to kernel(), and why must we vandalize our standard C with angle brackets and a numeric tuple? Brace yourself, because this is where the magic happens.
现在我们看到,CUDA C加__global__关键字来限定标准C函数(类似于一种改写了该方法的意思)。该机制通知编译器函数应该编译运行在设备上而不是主机。在这个简单的例子中,NVCC给出了kernel()功能函数来处理设备代码,它提供main()函数到host端就像前面的例子中写的一样(大概意思就是kernel执行在设备端,其它代码执行在CPU上,原文是不是很拗口?!!)。所以,kernel()神秘的召唤是什么,以及我们为什么要破坏我们的标准C角括号和数字元组?振作起来,因为这是魔法发生的地方。
补充知识
GPU建立了一组SMX,多流处理器;每个SMX中,有许多的sp组成(流处理器),一个SMX的配置如下:
192 cores(都是SIMT cores(Single Instruction Multiple Threads) and 64k registers GPU中的SIMT对应于CPU中的SIMD(Single Instruction Multiple Data) 64KB of shared memory / L1 cache 8KB cache for constants 48KB texture cache for read-only arrays up to 2K threads per SMX
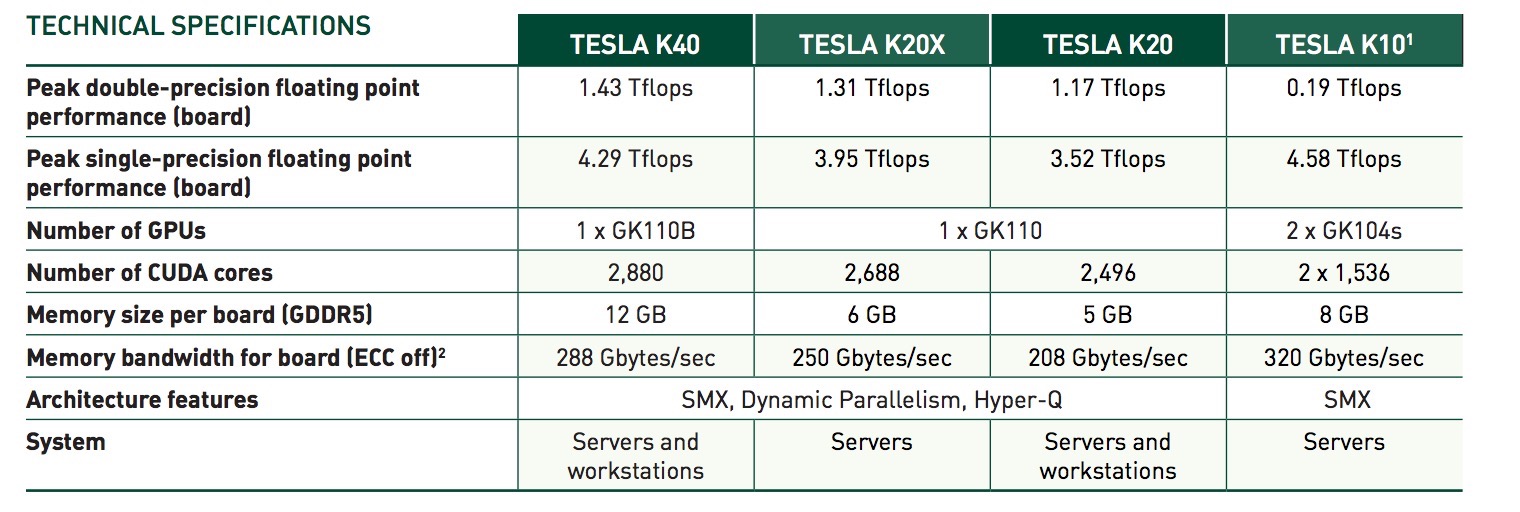
Tesla K40服务器架构基于 NVIDIA Kepler™ 架构的,如图下所示(官网Kepler架构说明,点击下载)

图中L2 Cache为2级缓存。K40一共15个SMX,每个SMX中之前已经说明,其中每个SMX核心数为192,得CUDA核心数为2880枚(15*192),内存大小12G。图下为各个参数:
SMX内的结构图如下。Warp是CUDA线程执行的最小单元,一个单元32个线程并行执行。寄存器文件大小:65536*32bit。 32个特殊功能单元 (SFU), 32个负载/存储单元(LD/ST),48k 只读数据一级数据缓存。64K共享内存或者128K,平台不同数据不同。Tex为纹理存储单元。

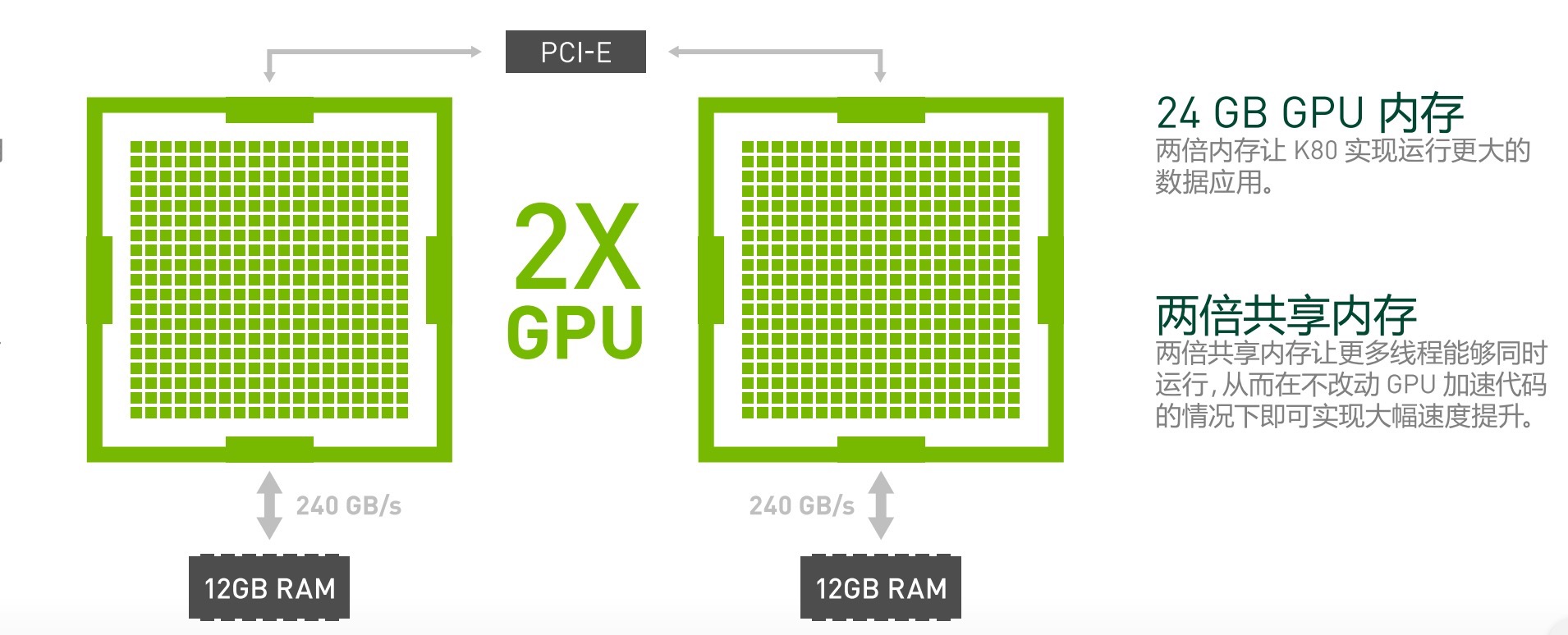
如今最新的K80服务器设置了双GPU,内存容量都翻倍了。感兴趣可以去了解。
1、程序写完后,以.cu结尾,切勿.cpp什么的。执行方式 $: nvcc test.cu -o test
2、如果理解了GPU底层架构将会更加清楚线程的执行方式(我不会对GPU的架构做过多的赘述,只介绍K40服务器的架构特点)如果感觉很迷糊说不清楚请参考这篇:显卡帝教你读懂GPU架构图 轻松做达人 以及下面官方的PDF
参考:
nv-ds-tesla-kcompute-arch-may-2012-cn
NVIDIA-Kepler-GK110-GK210-Architecture-Whitepaper