1、计算模块接口的设计与实现过程
流程图
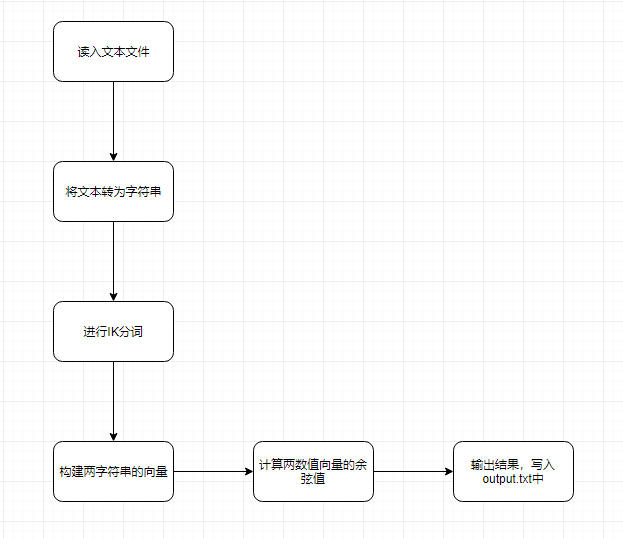
实现过程
采用相似度度量来计算两篇文本的相似程度,该值越小,说明文本的相似度越小,反之则说明相似度越大。
余弦相似度是相似度度量的其中一种。假定a和b是两个n维向量,a是(x1, x2, ..., xn),b是 (y1, y2, ..., yn),a与b的夹角的余弦值越接近1,说明夹角越接近0度,即两个向量越相似,称之为"余弦相似性"。余弦值越大,说明两文本越相似。
样例:
string str1 = "卢森堡商务部就此事件可能对印度大使馆造成的负面影响感到抱歉。",
string str2 = "此事件对印度大使馆造成了一定的负面影响,卢森堡外交部感到抱歉并公开道歉。"
1、首先进行IK分词
str1:卢森堡/商务部/就此/此事/事件/可能/能对/印度大使馆/造成/负面影响/感到/抱歉
str2:此事/事件/对/印度大使馆/造成了/一定的/负面影响/卢森堡/商务部/感到/抱歉/公开/开道/道歉
2、列出两个文本中所有不重复的词的个数为18个
3、得到str1,str2的向量。所有词18个,每个句子分出的词在这18个词中,则为1,不在则为0,如“卢森堡”,str1中有,为1,str2中有,为1。而“一定的”str1中没有,为0,str2中有,为1。所以分词后的句子转化为如下对应的数值向量X,Y。
X = (1,1,1,1,1,1,1,1,1,1,1,1,0,1,0,1,0,0)
Y = (0,1,1,0,1,1,1,0,1,1,0,1,1,1,1,1,1,1)
4、根据公式,计算两数值向量的余弦值为0.667135。该值即可以用来刻画这两篇文本的相似程度,约为66.7%。
2、计算模块接口部分的性能测试
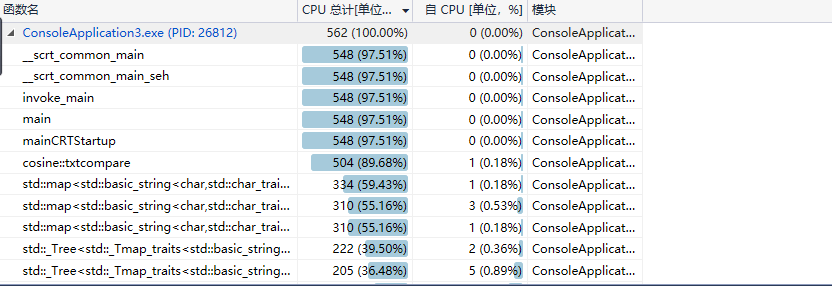
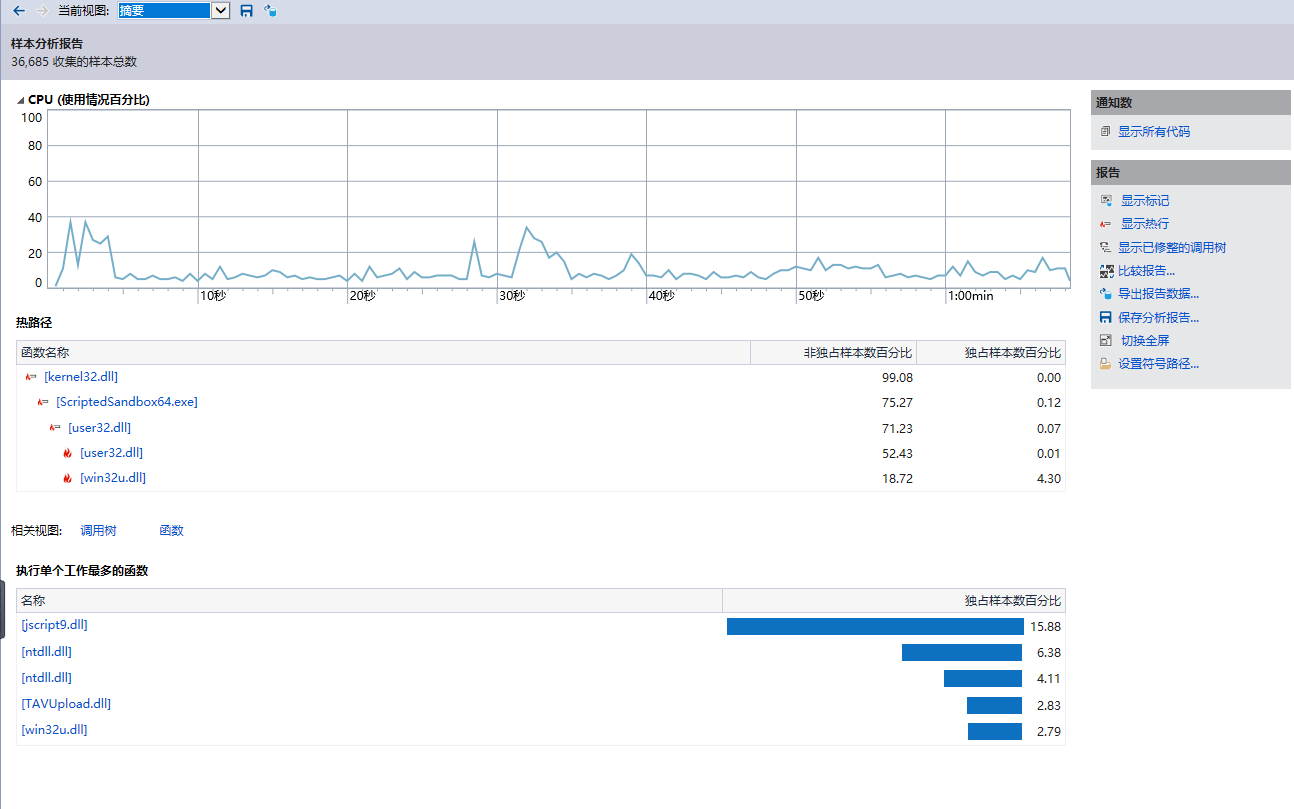
程序主要执行的部分在main函数中,这与我们的程序本身和预期相符。
3、计算模块部分单元测试展示
部分单元测试代码:
namespace UnitTest1
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(TestMethod1)
{
//文件名
char fn1[] = "orig.txt";
char * fn = fn1;
string str1;
str1 = file_string(fn);
char fn2[] = "orig_0.8_mix.txt";
char * fnn = fn2;
string str2;
str2 = file_string(fnn);
ofstream fout;
fout.open("output.txt");
fout << cosine::txtcompare(str1, str2);
fout.close();
}
};
}
4、计算模块部分异常处理说明
所给出的文件不存在或为空时:
int main()
{
//文件名
char fn1[] = "orig1.txt";//没有该文件
char * fn = fn1;
string str1;
str1 = file_string(fn);
char fn2[] = "orig_0.8_mix.txt";
char * fnn = fn2;
string str2;
str2 = file_string(fnn);
ofstream fout;
fout.open("output.txt");
fout << cosine::txtcompare(str1, str2);
fout.close();
system("pause");
}
输出结果如下:

5、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 40 |
| Estimate | 估计这个任务需要多少时间 | 35 | 30 |
| Development | 开发 | 300 | 420 |
| Analysis | 需求分析(包括学习新技术) | 600 | 540 |
| Design Spec | 生成设计文档 | 50 | 45 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 30 | 40 |
| Design | 具体设计 | 50 | 40 |
| Coding | 具体编码 | 70 | 100 |
| Coding Review | 代码复审 | 30 | 20 |
| Test | 测试(自我测试、修改代码、提交修改) | 180 | 200 |
| Reporting | 报告 | 50 | 50 |
| Test Repor | 测试报告 | 20 | 30 |
| Size Measurement | 计算工作量 | 20 | 30 |
| Postmortem&Process Improvement Plan | 事后总结,并提出过程改进计划 | 20 | 30 |
| 合计 | 1515 | 1645 |
6、总结
作为一个菜鸡,本次个人编程作为对我是一个巨大的挑战。看到作业的时候整个人是懵逼的。作业的要求中的各种内容都是第一次接触。我花了大量的时间去搜索相关的知识点和一些工具的使用,说来惭愧,VS2017我还是头一回使用,也有很多不熟悉的地方。关于github的操作还很生疏,之后还需要在不断的实践中加以巩固。另,自己掌握的编程语言和算法实在太有限,给我带来了很多阻碍,希望在以后的学习中能够不断深入学习和加强吧。