使用前需要确保安装以下第三方库:
jieba, wordcloud, imageio, sklearn,csv
imageio、csv和sklearn在安装anaconda时默认是安装的,另外两个库需要手动安装,安装方式如下:
打开Anaconda Prompt使用pip安装即可:
pip install jieba
pip install wordcloud
我们选一篇自己喜欢的文章,然后保存为txt,放到工作目录下。我选取的文章为知乎上秋叶大叔的一篇文章:如何实现财富自由?
我将其内容保存为"caifu.txt",放在工作目录下,以下是获得这篇文章词云图的过程。
获得词云图
from wordcloud import WordCloud, STOPWORDS from imageio import imread from sklearn.feature_extraction.text import CountVectorizer import jieba import csv # 获取文章内容 with open("caifu.txt") as f: contents = f.read() print("contents变量的类型:", type(contents)) # 使用jieba分词,获取词的列表 contents_cut = jieba.cut(contents) print("contents_cut变量的类型:", type(contents_cut)) contents_list = " ".join(contents_cut) print("contents_list变量的类型:", type(contents_list)) # 制作词云图,collocations避免词云图中词的重复,mask定义词云图的形状,图片要有背景色 wc = WordCloud(stopwords=STOPWORDS.add("一个"), collocations=False, background_color="white", font_path=r"C:WindowsFontssimhei.ttf", width=400, height=300, random_state=42, mask=imread('axis.png',pilmode="RGB")) wc.generate(contents_list) wc.to_file("ciyun.png") # 使用CountVectorizer统计词频 cv = CountVectorizer() contents_count = cv.fit_transform([contents_list]) # 词有哪些 list1 = cv.get_feature_names() # 词的频率 list2 = contents_count.toarray().tolist()[0] # 将词与频率一一对应 contents_dict = dict(zip(list1, list2)) # 输出csv文件,newline="",解决输出的csv隔行问题 with open("caifu_output.csv", 'w', newline="") as f: writer = csv.writer(f) for key, value in contents_dict.items(): writer.writerow([key, value])
上述代码中,变量的类型如下:
contents变量的类型: <class 'str'> contents_cut变量的类型: <class 'generator'> contents_list变量的类型: <class 'str'>
词云图的形状我尝试了两种,一种是cat.png,另一种是在PPT中直接画一个箭头,保存为图片格式,如下图:


两种背景图产生的词云图结果如下:


我们可以把背景图的设置为任意形状和图片,如果没有合适的照片,我们可以用PPT自己画一个合适的形状。
获得词频列表,保存为csv文件
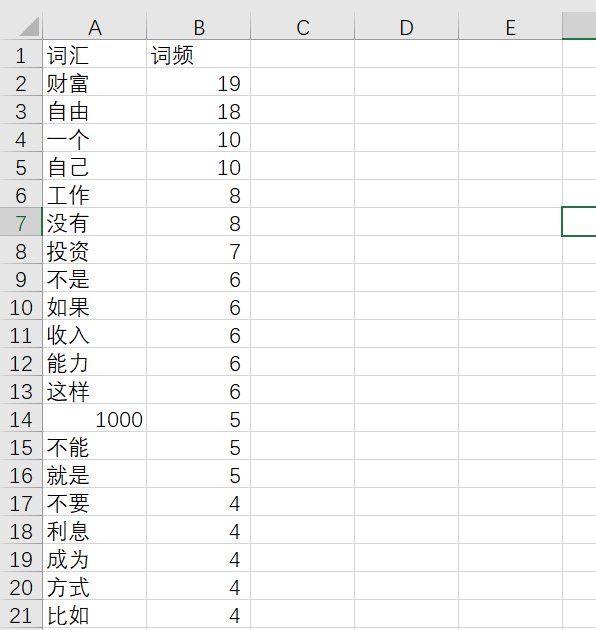
如果还想要获得词频列表,可以使用sklearn中的CountVectorizer统计词频,当然也可以自己写函数实现。上述代码输出了词频的csv文件,如下图:
参考链接: