内容目录:
- Gevent协程
- SelectPollEpoll异步IO与事件驱动
- Python连接Mysql数据库操作
- RabbitMQ队列
- RedisMemcached缓存
- Paramiko SSH
- Twsited网络框架
网络并发编程的2个套路, 多进程,多线程
协程
协程,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程。
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此:
协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置。
协程的好处:
- 无需线程上下文切换的开销
- 无需原子操作锁定及同步的开销方便切换控制流,简化编程模型
- "原子操作(atomic operation)是不需要synchronized",所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程)。
- 原子操作可以是一个步骤,也可以是多个操作步骤,但是其顺序是不可以被打乱,或者切割掉只执行部分。视作整体是原子性的核心。
- 高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
缺点:
- 无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上.当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用。
- 进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序
使用yield实现协程操作例子:


import time import queue def consumer(name): print("--->starting eating baozi...") while True: new_baozi = yield print("[%s] is eating baozi %s" % (name,new_baozi)) #time.sleep(1) def producer(): r = con.__next__() r = con2.__next__() n = 0 while n < 5: n +=1 con.send(n) con2.send(n) print("�33[32;1m[producer]�33[0m is making baozi %s" %n ) if __name__ == '__main__': con = consumer("c1") con2 = consumer("c2") p = producer()
协程标准定义,即符合什么条件就能称之为协程:
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
- 一个协程遇到IO操作自动切换到其它协程
Greenlet
greenlet是一个用C实现的协程模块,相比与python自带的yield,它可以使你在任意函数之间随意切换,而不需把这个函数先声明为generator
import time
'''
greenlet是封装好的协程,手动切换
协程遇到IO操作就切换!
'''
from greenlet import greenlet
def test1():
print(12)
gr2.switch()
print(34)
gr2.switch()
def test2():
print(56)
gr1.switch()
print(78)
gr1 = greenlet(test1)#启动一个协程
gr2 = greenlet(test2)
gr1.switch()
比generator还简单了呢,但没有解决一个问题,就是遇到IO操作,自动切换?
Gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。
Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
#Author:Yun import gevent def foo(): print('Runing in foo') gevent.sleep(2) print('haha') def bar(): print('Running in bar') gevent.sleep(1) print('hehe') def func3(): print('runing func3') gevent.sleep(0) print('fun3 ...again') gevent.joinall( [ gevent.spawn(foo), gevent.spawn(bar), gevent.spawn(func3), ] )
输出:
Runing in foo
Running in bar
runing func3
fun3 ...again
hehe
haha
同步与异步的性能区别 :
import gevent def task(pid): """ Some non-deterministic task """ gevent.sleep(0.5) print('Task %s done' % pid) def synchronous(): for i in range(1, 10): task(i) def asynchronous(): threads = [gevent.spawn(task, i) for i in range(10)] gevent.joinall(threads) print('Synchronous:')#同步 synchronous() print('Asynchronous:')#异步 asynchronous(
上面程序的重要部分是将task函数封装到Greenlet内部线程的gevent.spawn。
初始化的greenlet列表存放在数组threads中,此数组被传给gevent.joinall 函数,
后者阻塞当前流程,并执行所有给定的greenlet。执行流程只会在 所有greenlet执行完后才会继续向下走。
遇到IO阻塞时会自动切换任务:
import gevent,time from urllib import request from gevent import monkey gevent.monkey.patch_all()#把当前程序的所有得IO操作给我单独的做上标记 def f(url): print('GET:%s' % url) resp = request.urlopen(url) data = resp.read() print('%d bytes received from %s'%(len(data),url)) async_time_start = time.time() gevent.joinall([ gevent.spawn(f,'https://www.python.org/'), gevent.spawn(f,'https://www.yahoo.com/'), gevent.spawn(f,'https://github.com/') ]) print("异步cost",time.time()-async_time_start)
通过gevent实现单线程下的多socket并发:
#Author:Yun #通过gevent实现单线程下的多socket并发 import sys import socket import time import gevent from gevent import socket, monkey monkey.patch_all() def server(port): s = socket.socket() s.bind(('0.0.0.0', port)) s.listen(500) while True: conn, addr = s.accept() gevent.spawn(handle_request, conn)#生成一个协程 def handle_request(conn): try: while True: data = conn.recv(1024) print("recv:", data) conn.send(data) if not data: conn.shutdown(socket.SHUT_WR) except Exception as ex: print(ex) finally: conn.close() if __name__ == '__main__': server(8989)
#Author:Yun import socket HOST = 'localhost' # The remote host PORT = 8989 # The same port as used by the server s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((HOST, PORT)) while True: msg = bytes(input(">>:"), encoding="utf8") s.sendall(msg) data = s.recv(1024) # print(data) print('Received', repr(data)) s.close()
并发100个sock连接
#Author:Yun #通过gevent实现单线程下的多socket并发 import sys import socket import time import gevent from gevent import socket, monkey monkey.patch_all() def server(port): s = socket.socket() s.bind(('0.0.0.0', port)) s.listen(500) while True: conn, addr = s.accept() gevent.spawn(handle_request, conn)#生成一个协程 def handle_request(conn): try: while True: data = conn.recv(1024) print("recv:", data) conn.send(data) if not data: conn.shutdown(socket.SHUT_WR) except Exception as ex: print(ex) finally: conn.close() if __name__ == '__main__': server(8989)
论事件驱动与异步IO
看图说话事件驱动模型
在UI编程中,常常要对鼠标点击进行相应,首先如何获得鼠标点击呢?
方式一:创建一个线程,该线程一直循环检测是否有鼠标点击,那么这个方式有以下几个缺点:
1. CPU资源浪费,可能鼠标点击的频率非常小,但是扫描线程还是会一直循环检测,这会造成很多的CPU资源浪费;如果扫描鼠标点击的接口是阻塞的呢?
2. 如果是堵塞的,又会出现下面这样的问题,如果我们不但要扫描鼠标点击,还要扫描键盘是否按下,由于扫描鼠标时被堵塞了,那么可能永远不会去扫描键盘;
3. 如果一个循环需要扫描的设备非常多,这又会引来响应时间的问题;
所以,该方式是非常不好的。
方式二:就是事件驱动模型
目前大部分的UI编程都是事件驱动模型,如很多UI平台都会提供onClick()事件,这个事件就代表鼠标按下事件。事件驱动模型大体思路如下:
1. 有一个事件(消息)队列;
2. 鼠标按下时,往这个队列中增加一个点击事件(消息);
3. 有个循环,不断从队列取出事件,根据不同的事件,调用不同的函数,如onClick()、onKeyDown()等;
4. 事件(消息)一般都各自保存各自的处理函数指针,这样,每个消息都有独立的处理函数;
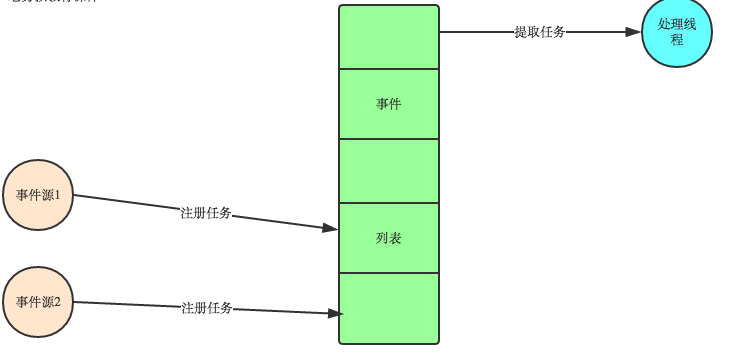
事件驱动编程是一种编程范式,这里程序的执行流由外部事件来决定。它的特点是包含一个事件循环,当外部事件发生时使用回调机制来触发相应的处理。
另外两种常见的编程范式是(单线程)同步以及多线程编程。
让我们用例子来比较和对比一下单线程、多线程以及事件驱动编程模型。下图展示了随着时间的推移,这三种模式下程序所做的工作。
这个程序有3个任务需要完成,每个任务都在等待I/O操作时阻塞自身。阻塞在I/O操作上所花费的时间已经用灰色框标示出来了。
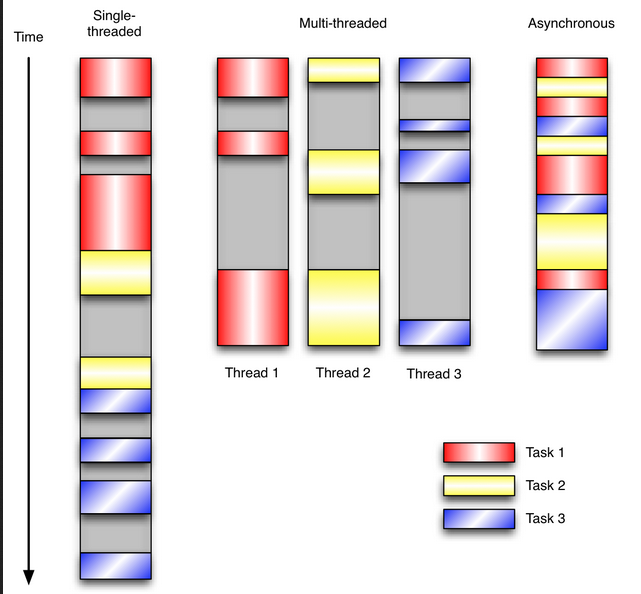
在单线程同步模型中,任务按照顺序执行。如果某个任务因为I/O而阻塞,其他所有的任务都必须等待,直到它完成之后它们才能依次执行。
这种明确的执行顺序和串行化处理的行为是很容易推断得出的。如果任务之间并没有互相依赖的关系,但仍然需要互相等待的话这就使得程序不必要的降低了运行速度。
在多线程版本中,这3个任务分别在独立的线程中执行。这些线程由操作系统来管理,在多处理器系统上可以并行处理,或者在单处理器系统上交错执行。这使得当某个线程阻塞在某个资源的同时其他线程得以继续执行。与完成类似功能的同步程序相比,这种方式更有效率,但程序员必须写代码来保护共享资源,防止其被多个线程同时访问。多线程程序更加难以推断,因为这类程序不得不通过线程同步机制如锁、可重入函数、线程局部存储或者其他机制来处理线程安全问题,如果实现不当就会导致出现微妙且令人痛不欲生的bug。
在事件驱动版本的程序中,3个任务交错执行,但仍然在一个单独的线程控制中。当处理I/O或者其他昂贵的操作时,注册一个回调到事件循环中,然后当I/O操作完成时继续执行。回调描述了该如何处理某个事件。事件循环轮询所有的事件,当事件到来时将它们分配给等待处理事件的回调函数。这种方式让程序尽可能的得以执行而不需要用到额外的线程。事件驱动型程序比多线程程序更容易推断出行为,因为程序员不需要关心线程安全问题。
当我们面对如下的环境时,事件驱动模型通常是一个好的选择:
- 程序中有许多任务
- 任务之间高度独立(因此它们不需要互相通信,或者等待彼此)
- 在等待事件到来时,某些任务会阻塞。
当应用程序需要在任务间共享可变的数据时,这也是一个不错的选择,因为这里不需要采用同步处理。
网络应用程序通常都有上述这些特点,这使得它们能够很好的契合事件驱动编程模型。
SelectPollEpoll异步IO
首先列一下,sellect、poll、epoll三者的区别
select
select最早于1983年出现在4.2BSD中,它通过一个select()系统调用来监视多个文件描述符的数组,当select()返回后,该数组中就绪的文件描述符便会被内核修改标志位,使得进程可以获得这些文件描述符从而进行后续的读写操作。
select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点,事实上从现在看来,这也是它所剩不多的优点之一。
select的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,不过可以通过修改宏定义甚至重新编译内核的方式提升这一限制。
另外,select()所维护的存储大量文件描述符的数据结构,随着文件描述符数量的增大,其复制的开销也线性增长。同时,由于网络响应时间的延迟使得大量TCP连接处于非活跃状态,但调用select()会对所有socket进行一次线性扫描,
所以这也浪费了一定的开销。
poll
poll在1986年诞生于System V Release 3,它和select在本质上没有多大差别,但是poll没有最大文件描述符数量的限制。
poll和select同样存在一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。
另外,select()和poll()将就绪的文件描述符告诉进程后,如果进程没有对其进行IO操作,那么下次调用select()和poll()的时候将再次报告这些文件描述符,所以它们一般不会丢失就绪的消息,这种方式称为水平触发(Level Triggered)。
epoll
直到Linux2.6才出现了由内核直接支持的实现方法,那就是epoll,它几乎具备了之前所说的一切优点,被公认为Linux2.6下性能最好的多路I/O就绪通知方法。
epoll可以同时支持水平触发和边缘触发(Edge Triggered,只告诉进程哪些文件描述符刚刚变为就绪状态,它只说一遍,如果我们没有采取行动,那么它将不会再次告知,这种方式称为边缘触发),理论上边缘触发的性能要更高一些,但是代码实现相当复杂。
epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射(mmap)技术,这样便彻底省掉了这些文件描述符在系统调用时复制的开销。
另一个本质的改进在于epoll采用基于事件的就绪通知方式。在select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。
Python select
Python的select()方法直接调用操作系统的IO接口,它监控sockets,open files, and pipes(所有带fileno()方法的文件句柄)同时变成readable 和writeable, 或者通信错误,select()使得同时监控多个连接变的简单,
并且这比写一个长循环来等待和监控多客户端连接要高效,因为select直接通过操作系统提供的C的网络接口进行操作,而不是通过Python的解释器。
注意:使用带有select()的Python文件对象适用于Unix,但在Windows下不受支持。
接下来通过echo server例子要以了解select 是如何通过单进程实现同时处理多个非阻塞的socket连接的
import select
import socket
import sys
import Queue
# Create a TCP/IP socket
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.setblocking(0)
# Bind the socket to the port
server_address = ('localhost', 10000)
print(sys.stderr, 'starting up on %s port %s' % server_address)
server.bind(server_address)
# Listen for incoming connections
server.listen(5)
select()方法接收并监控3个通信列表, 第一个是所有的输入的data,就是指外部发过来的数据,第2个是监控和接收所有要发出去的data(outgoing data),
第3个监控错误信息,接下来我们需要创建2个列表来包含输入和输出信息来传给select().
# Sockets from which we expect to read inputs = [ server ] # Sockets to which we expect to write outputs = [ ]
所有客户端的进来的连接和数据将会被server的主循环程序放在上面的list中处理,我们现在的server端需要等待连接可写(writable)之后才能过来,
然后接收数据并返回(因此不是在接收到数据之后就立刻返回),因为每个连接要把输入或输出的数据先缓存到queue里,然后再由select取出来再发出去。
服务器主循环将连接添加到这些列表中或从这些列表中删除。 由于此版本的服务器将在发送任何数据之前等待套接字变为可写(而不是立即发送回复),
因此每个输出连接都需要一个队列作为通过它发送数据的缓冲区。
# Outgoing message queues (socket:Queue)
message_queues = {}
下面是此程序的主循环,调用select()时会阻塞和等待直到新的连接和数据进来
while inputs:
# Wait for at least one of the sockets to be ready for processing
print(sys.stderr, '
waiting for the next event')
readable, writable, exceptional = select.select(inputs, outputs, inputs)
当你把inputs,outputs,exceptional(这里跟inputs共用)传给select()后,它返回3个新的list,
我们上面将他们分别赋值为readable,writable,exceptional,
所有在readable list中的socket连接代表有数据可接收(recv),所有在writable list中的
存放着你可以对其进行发送(send)操作的socket连接,当连接通信出现error时会把error写到exceptional列表中。
Readable list 中的socket 可以有3种可能状态,第一种是如果这个socket是main "server" socket,它负责监听客户端的连接,
如果这个main server socket出现在readable里,那代表这是server端已经ready来接收一个新的连接进来了,
为了让这个main server能同时处理多个连接,在下面的代码里,我们把这个main server的socket设置为非阻塞模式。
for s in readable:
if s is server:
# A "readable" server socket is ready to accept a connection
connection, client_address = s.accept()
print(sys.stderr, 'new connection from', client_address)
connection.setblocking(0)#非阻塞模式,为了让这个main server能同时处理多个连接
inputs.append(connection)
# Give the connection a queue for data we want to send
message_queues[connection] = Queue.Queue()
第二种情况是这个socket是已经建立了的连接,它把数据发了过来,这个时候你就可以通过recv()来接收它发过来的数据,
然后把接收到的数据放到queue里,这样你就可以把接收到的数据再传回给客户端了
else:
data = s.recv(1024)
if data:
# A readable client socket has data
print(sys.stderr, 'received "%s" from %s' % (data, s.getpeername()))
message_queues[s].put(data)
# Add output channel for response
if s not in outputs:
outputs.append(s)
第三种情况就是这个客户端已经断开了,所以你再通过recv()接收到的数据就为空了,所以这个时候你就可以把这个跟客户端的连接关闭了。
else:
# Interpret empty result as closed connection
print(sys.stderr, 'closing', client_address, 'after reading no data')
# Stop listening for input on the connection
if s in outputs:
outputs.remove(s) #既然客户端都断开了,我就不用再给它返回数据了,所以这时候如果这个客户端的连接对象还在outputs列表中,就把它删掉
inputs.remove(s) #inputs中也删除掉
s.close() #把这个连接关闭掉
# Remove message queue
del message_queues[s]
对于writable list中的socket,也有几种状态,如果这个客户端连接在跟它对应的queue里有数据,就把这个数据取出来再发回给这个客户端,
否则就把这个连接从output list中移除,
这样下一次循环select()调用时检测到outputs list中没有这个连接,那就会认为这个连接还处于非活动状态
for s in writable:
try:
next_msg = message_queues[s].get_nowait()
except Queue.Empty:
# No messages waiting so stop checking for writability.
print(sys.stderr, 'output queue for', s.getpeername(), 'is empty')
outputs.remove(s)
else:
print(sys.stderr, 'sending "%s" to %s' % (next_msg, s.getpeername()))
s.send(next_msg)
最后,如果在跟某个socket连接通信过程中出了错误,就把这个连接对象在inputsoutputsmessage_queue中都删除,再把连接关闭掉
for s in exceptional:
print(sys.stderr, 'handling exceptional condition for', s.getpeername())
# Stop listening for input on the connection
inputs.remove(s)
if s in outputs:
outputs.remove(s)
s.close()
# Remove message queue
del message_queues[s]
最后服务器端的完整代码如下:
import select import socket import sys import queue # Create a TCP/IP socket server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.setblocking(False) # Bind the socket to the port server_address = ('localhost', 10000) print(sys.stderr, 'starting up on %s port %s' % server_address) server.bind(server_address) # Listen for incoming connections server.listen(5) # Sockets from which we expect to read inputs = [ server ] # Sockets to which we expect to write outputs = [ ] message_queues = {} while inputs: # Wait for at least one of the sockets to be ready for processing print( ' waiting for the next event') readable, writable, exceptional = select.select(inputs, outputs, inputs) # Handle inputs for s in readable: if s is server: # A "readable" server socket is ready to accept a connection connection, client_address = s.accept() print('new connection from', client_address) connection.setblocking(False) inputs.append(connection) # Give the connection a queue for data we want to send message_queues[connection] = queue.Queue() else: data = s.recv(1024) if data: # A readable client socket has data print(sys.stderr, 'received "%s" from %s' % (data, s.getpeername()) ) message_queues[s].put(data) # Add output channel for response if s not in outputs: outputs.append(s) else: # Interpret empty result as closed connection print('closing', client_address, 'after reading no data') # Stop listening for input on the connection if s in outputs: outputs.remove(s) #既然客户端都断开了,我就不用再给它返回数据了,所以这时候如果这个客户端的连接对象还在outputs列表中,就把它删掉 inputs.remove(s) #inputs中也删除掉 s.close() #把这个连接关闭掉 # Remove message queue del message_queues[s] # Handle outputs for s in writable: try: next_msg = message_queues[s].get_nowait() except queue.Empty: # No messages waiting so stop checking for writability. print('output queue for', s.getpeername(), 'is empty') outputs.remove(s) else: print( 'sending "%s" to %s' % (next_msg, s.getpeername())) s.send(next_msg) # Handle "exceptional conditions" for s in exceptional: print('handling exceptional condition for', s.getpeername() ) # Stop listening for input on the connection inputs.remove(s) if s in outputs: outputs.remove(s) s.close() # Remove message queue del message_queues[s]
import socket import sys messages = [ 'This is the message. ', 'It will be sent ', 'in parts.', ] server_address = ('localhost', 9898) # Create a TCP/IP socket socks = [ socket.socket(socket.AF_INET, socket.SOCK_STREAM), socket.socket(socket.AF_INET, socket.SOCK_STREAM), ] # Connect the socket to the port where the server is listening print >>sys.stderr, 'connecting to %s port %s' % server_address for s in socks: s.connect(server_address) for message in messages: # Send messages on both sockets for s in socks: print >>sys.stderr, '%s: sending "%s"' % (s.getsockname(), message) s.send(message) # Read responses on both sockets for s in socks: data = s.recv(1024) print >>sys.stderr, '%s: received "%s"' % (s.getsockname(), data) if not data: print >>sys.stderr, 'closing socket', s.getsockname() s.close()
RabbitMQ队列
为什么会有RabbitMQ队列?

安装python rabbitMQ module
pip install pika
or
easy_install pika
or
源码
https://pypi.python.org/pypi/pika
实现最简单的队列通信

send端:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()#声明一个管道
#声明queue
channel.queue_declare(queue='hello')
#RabbitMQ消息永远不能直接发送到队列,它总是需要通过交换.
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()
receive端:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()#声明一个管道
'''
您可能会问为什么我们再次声明队列 - 我们已经在之前的代码中声明了它。
如果我们确定队列已经存在,我们可以避免这种情况。 例如,如果是receive端的程序
先运行,程序就会报错,因为找不到queue。 但我们还不确定首先运行哪个程序。在这种情况下,在两个程序中都声明队列,
就可以避免receive端程序先运行而出错的情况。
'''
channel.queue_declare(queue='hello')#声明queue
def callback(ch, method, properties, body):#callback回调函数
#ch是channel的内存对象
print(" [x] Received %r" % body)
# 处理完消息手动去跟服务器端确认,如果不确认服务器端是不会删除消息
ch.basic_ack(delivery_tag=method.delivery_tag)
#处理完消息手动去跟服务器端确认,服务器端就会删除消息
channel.basic_consume(callback,#消费消息
queue='hello',
no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
Work Queues
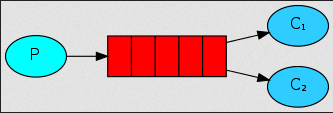
在这种模式下,RabbitMQ会默认把p发的消息依次分发给各个消费者(c),跟负载均衡差不多。
消息提供者代码:
import pika
import time
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()#声明管道
# 声明queue
channel.queue_declare(queue='task_queue')
# RabbitMQ消息永远不能直接发送到队列,它总是需要通过交换.
message = ' '.join(sys.argv[1:]) or "Hello World! %s" % time.time()
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
)
)
print(" [x] Sent %r" % message)
connection.close()
消费者代码:
import pika, time
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel()
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(20)
print(" [x] Done")
print("method.delivery_tag",method.delivery_tag)
# 处理完消息手动去跟服务器端确认,如果不确认服务器端是不会删除消息
ch.basic_ack(delivery_tag=method.delivery_tag)
#处理完消息手动去跟服务器端确认,服务器端就会删除消息
channel.basic_consume(callback,
queue='task_queue',
no_ack=True
)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
执行任务可能需要几秒钟。您可能想知道如果其中一个消费者开始执行长任务并且仅在部分完成时死亡会发生什么。使用我们当前的代码,一旦RabbitMQ向客户发送消息,它立即将其从内存中删除。
在这种情况下,如果你杀死一个工人,我们将丢失它刚刚处理的消息。我们还将丢失分发给这个特定工作者但尚未处理的所有消息。
但我们不想失去任何任务。如果工人死亡,我们希望将任务交付给另一名工人。
为了确保消息永不丢失,RabbitMQ支持消息确认。从消费者发回ack(nowledgement)以告知RabbitMQ已收到,处理了特定消息,并且RabbitMQ可以自由删除它。
如果消费者死亡(其通道关闭,连接关闭或TCP连接丢失)而不发送确认,RabbitMQ将理解消息未完全处理并将重新排队。如果其他消费者同时在线,则会迅速将其重新发送给其他消费者。
这样你就可以确保没有消息丢失,即使工人偶尔会死亡。没有任何消息超时;当消费者死亡时,RabbitMQ将重新发送消息。即使处理消息需要非常长的时间,也没关系。
默认情况下,消息确认已打开。在前面的示例中,我们通过no_ack = True标志明确地将它们关闭。一旦我们完成任务,就应该删除此标志并从工作人员发送适当的确认。
def callback(ch, method, properties, body):
print " [x] Received %r" % (body,)
time.sleep( body.count('.') )
print " [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello')
使用此代码,我们可以确定即使您在处理消息时使用CTRL + C杀死一名工作人员,也不会丢失任何内容。 工人死后不久,所有未经确认的消息将被重新传递
消息持久化
我们已经学会了如何确保即使消费者死亡,任务也不会丢失(默认情况下,如果要禁用使用no_ack = True)。 但是如果RabbitMQ服务器停止,我们的任务仍然会丢失。
当RabbitMQ退出或崩溃时,它将忘记队列和消息,除非你告诉它不要。 确保消息不会丢失需要做两件事:我们需要将队列和消息都标记为持久。
首先,我们需要确保RabbitMQ永远不会丢失我们的队列。 为此,我们需要声明它是持久的:
channel.queue_declare(queue='hello', durable=True)
虽然此命令本身是正确的,但它在我们的设置中不起作用。 那是因为我们已经定义了一个名为hello的队列,这个队列不耐用。 RabbitMQ不允许您使用不同的参数重新定义现有队列,
并将向尝试执行此操作的任何程序返回错误。 但是有一个快速的解决方法 - 让我们声明一个具有不同名称的队列,例如:task_queue:
channel.queue_declare(queue='task_queue', durable=True)
此queue_declare更改需要应用于生产者和消费者代码。
此时我们确信即使RabbitMQ重新启动,task_queue队列也不会丢失。 现在我们需要将消息标记为持久性 - 通过提供值为2的delivery_mode属性。
channel.basic_publish(exchange='',
routing_key="task_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # 使消息持久化
))
消息公平分发
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,
同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。
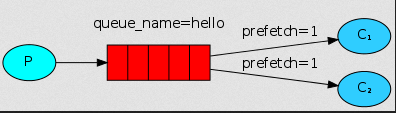
channel.basic_qos(prefetch_count=1)
带消息持久化+公平分发的完整代码:
生产者端:
#Author:Yun import pika connection = pika.BlockingConnection(pika.ConnectionParameters( 'localhost')) channel = connection.channel()#声明一个管道 # 声明queue channel.queue_declare(queue='hello2',durable=True)#durable=True只是把队列持久化 # n RabbitMQ a message can never be sent directly to the queue, it always needs to go through an exchange. channel.basic_publish(exchange='', routing_key='hello2', body='Hello World!', properties=pika.BasicProperties( delivery_mode= 2,#使消息持久化 ) ) print(" [x] Sent 'Hello World!'") connection.close()
消费消息端:
#Author:Yun import pika connection = pika.BlockingConnection(pika.ConnectionParameters( 'localhost')) channel = connection.channel()#声明一个管道 '''您可能会问为什么我们再次声明队列 - 我们已经在之前的代码中声明了它。 如果我们确定队列已经存在,我们可以避免这种情况。 例如,如果是consumer.py程序 先运行程序会因为找不到queue而报错。 但我们还不确定首先运行哪个程序。在这种情况下,在两个程序中都声明队列, 就可以避免consumer.py先运行而出错的情况。 ''' channel.queue_declare(queue='hello2',durable=True) def callback(ch, method, properties, body):#callback回调函数 #ch是channel的内存对象 print(" [x] Received %r" % body) ch.basic_ack(delivery_tag=method.delivery_tag) channel.basic_qos(prefetch_count=1)#告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。 channel.basic_consume(#消费消息 callback, queue='hello2', no_ack=True) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming()
PublishSubscribe(消息发布订阅)
之前的例子都基本都是1对1的消息发送和接收,即消息只能发送到指定的queue里,但有些时候你想让你的消息被所有的Queue收到,类似广播的效果,这时候就要用到exchange了。
交换是一件非常简单的事情。 一方面,它接收来自生产者的消息,另一方面将它们推送到队列。 交易所必须确切知道如何处理收到的消息。 它应该附加到特定队列吗?
它应该附加到许多队列吗? 或者它应该被丢弃。 其规则由交换类型定义。
Exchange在定义的时候是有类型的,以决定到底是哪些Queue符合条件,可以接收消息
fanout: 所有bind到此exchange的queue都可以接收消息
direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
表达式符号说明:#代表一个或多个字符,*代表任何字符
例:#.a会匹配a.a,aa.a,aaa.a等
*.a会匹配a.a,b.a,c.a等
注:使用RoutingKey为#,Exchange Type为topic的时候相当于使用fanout
headers: 通过headers 来决定把消息发给哪些queue
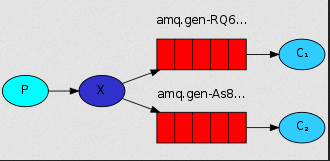
消息publisher:
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='logs', type='fanout') message = ' '.join(sys.argv[1:]) or "info: Hello World!" channel.basic_publish(exchange='logs', routing_key='', body=message) print(" [x] Sent %r" % message) connection.close()
消息subscriber:
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='logs', type='fanout') result = channel.queue_declare(exclusive=True) #exclusive唯一的,不指定queue名字,rabbit会随机分配一个名字,exclusive=True #会在使用此queue的消费者断开后,自动将queue删除 queue_name = result.method.queue channel.queue_bind(exchange='logs', queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
有选择的接收消息(exchange type=direct)
RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
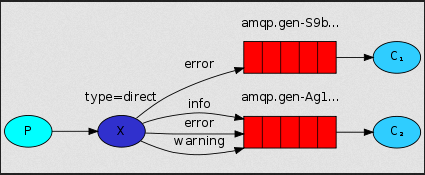
消息publisher:
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', type='direct') severity = sys.argv[1] if len(sys.argv) > 1 else 'info' message = ' '.join(sys.argv[2:]) or 'Hello World!' channel.basic_publish(exchange='direct_logs', routing_key=severity, body=message) print(" [x] Sent %r:%r" % (severity, message)) connection.close()
消息subscriber:
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', type='direct') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue severities = sys.argv[1:] if not severities: sys.stderr.write("Usage: %s [info] [warning] [error] " % sys.argv[0]) sys.exit(1) for severity in severities: channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key=severity) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
测试程序步骤:
1、先通过命令行,启动sub端的程序(声明接收消息的关键字),如,python consumer.py info
[*] Waiting for logs. To exit press CTRL+C
2、再通过命令行,启动pub端程序(声明发送消息的关键字),如,python producer.py info hehe
[x] Sent 'info':'hehe'
3、结果:
H:Python3_studyjichuday10RabbitMQdirect_broadcast>python consumer.py info
[*] Waiting for logs. To exit press CTRL+C
[x] 'info':b'hehe'
更细致的消息过滤
虽然使用直接交换改进了我们的系统,但它仍然有局限性 - 它不能基于多个标准进行路由。
在我们的日志系统中,我们可能不仅要根据严重性订阅日志,还要根据发出日志的源来订阅日志。 您可能从syslog unix工具中了解这个概念,
该工具根据严重性(info / warn / crit ...)和facility(auth / cron / kern ...)来路由日志。
这会给我们带来很大的灵活性 - 我们可能想听听来自'cron'的关键错误以及来自'kern'的所有日志。
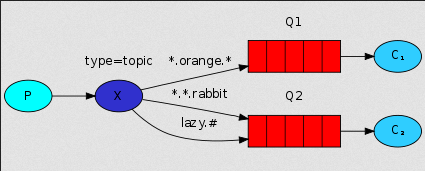
publisher:
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic')
routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()
subscriber:
#Author:Yun
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
exchange_type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...
" % sys.argv[0])
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
要从发布端接收所有运行的日志:
python receive_logs_topic.py "#"
要从发布端接收所有以kern.开头的日志:
python receive_logs_topic.py "kern.*"
要从发布端接收所有以.critical结尾的日志:
python receive_logs_topic.py "*.critical"
您可以创建多个绑定:
python receive_logs_topic.py "kern.*" "*.critical"
并使用路由键“kern.critical”类型发出日志:
python emit_log_topic.py "kern.critical" "A critical kernel error"
Remote procedure call (RPC)
为什么需要RPC(remote procedure call)?远程过程调用
当你有这样一个需求,从客户端发一条命令让远程服务器执行完后,返回一个数据。
前面的rabbitMQ 操作消息传递只是单向的,无法满足这种需求。因此RPC就横空出世。
什么是RPC?
从客户端发一条命令让远程服务器执行完后,返回一个数据这样的模式称为RPC。如,典型的RPC--简单网络管理协议(SNMP)
为了说明如何使用RPC服务,我们将创建一个简单的客户端类。 它将公开一个名为call的方法,
该方法发送一个RPC请求并阻塞,直到收到答案为止:
fibonacci_rpc = FibonacciRpcClient()
result = fibonacci_rpc.call(4)
print("fib(4) is %r" % result)
官方版:
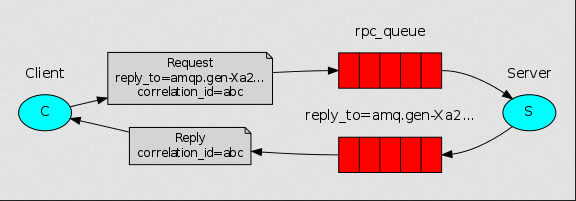
个人版:


RPC server:
#Author:Yun #'remote procedure call' import pika import time connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost')) channel = connection.channel() channel.queue_declare(queue='rpc_queue') def fib(n):#斐波那契数列 1 1 2 3 5 8 13 21 if n == 0: return 0 elif n == 1: return 1 else: return fib(n - 1) + fib(n - 2) def on_request(ch, method, props, body): n = int(body) print(" [.] fib(%s)" % n) response = fib(n)#获取结果 ch.basic_publish(exchange='', routing_key=props.reply_to,#拿到客户端随机生成的queue properties=pika.BasicProperties(correlation_id= props.correlation_id),#拿到客户端的correlation_id,并把它返回给客户端 body=str(response)) ch.basic_ack(delivery_tag=method.delivery_tag)#确保消息被消费,代表任务完成 channel.basic_qos(prefetch_count=1) channel.basic_consume(on_request, queue='rpc_queue') print(" [x] Awaiting RPC requests") channel.start_consuming()
RPC client:
#Author:Yun import pika import uuid import time class FibonacciRpcClient(object): def __init__(self): self.connection = pika.BlockingConnection(pika.ConnectionParameters( host='localhost'))#连接远程 self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True)# exclusive唯一的,不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除 self.callback_queue = result.method.queue#生成随机queue为callback_queue #声明接收消息 self.channel.basic_consume(self.on_response,#只要收到消息就调用on_response方法 no_ack=True, queue=self.callback_queue#声明从哪个queue接收消息 ) def on_response(self, ch, method, props, body): if self.corr_id == props.correlation_id:#此处判断服务器发回来的corrid是不是和本机相等,如果相等就说明服务器返回的是客户端发送指令所产生的结果 self.response = body ''' if self.corr_id == props.correlation_id: self.response = body 为什么要有这一步,因为客户端可以给服务器连续发两个指令,而返回顺序不一定是先发的先返回; 为了确保服务器返回的是客户端发送指令所产生的结果,所以必须有此步骤。 ''' def call(self, n): self.response = None self.corr_id = str(uuid.uuid4()) #发消息 self.channel.basic_publish(exchange='', routing_key='rpc_queue',#声明消息发到rpc_queue properties=pika.BasicProperties( reply_to=self.callback_queue,#让服务器执行完命令,把结果返回到callback_queue correlation_id=self.corr_id,#给服务器发送本机生成的correlation_id ), body=str(n))#消息内容 #当收到信息后,会触发on_response方法,这个方法使self.response不再为None #所以收到信息后,就会跳出循环 while self.response is None: self.connection.process_data_events()#非阻塞版的start_consumiting()每过一段时间就检查一次 #有消息就收消息没消息不阻塞就继续往下走 print('no msg...')#没有消息就会打印'no msg...' time.sleep(0.5) return int(self.response) fibonacci_rpc = FibonacciRpcClient()#实例化 print(" [x] Requesting fib(30)") response = fibonacci_rpc.call(8)#调用类中的call()方法 print(" [.] Got %r" % response)
Memcached & Redis使用
memcached
http://www.cnblogs.com/wupeiqi/articles/5132791.html
redis 使用
http://www.cnblogs.com/alex3714/articles/6217453.html