什么是回归?
假设现在有一些数据点,我们用 一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称作回归。
一、基于 Logistic 回归和 Sigmoid 函数的分类
我们想要的函数应该是,能接受所有的输入然后预测出类别。例如,在两个类的情况下,函数输出0或1。Sigmoid函数能在跳跃点上从0瞬间跳跃到1,。Sigmoid函数具体的计算公式如下:
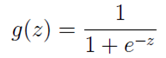
Sigmoid函数在不同坐标尺度下的两条曲线图。当x为0时,Sigmoid函数值为0.5。 随着x的增大,对应的Sigmoid值将逼近于1;而随着x的减小,Sigmoid值将逼近于0。如果横坐标 刻度足够大,Sigmoid函数看起来很像一个阶跃函数。
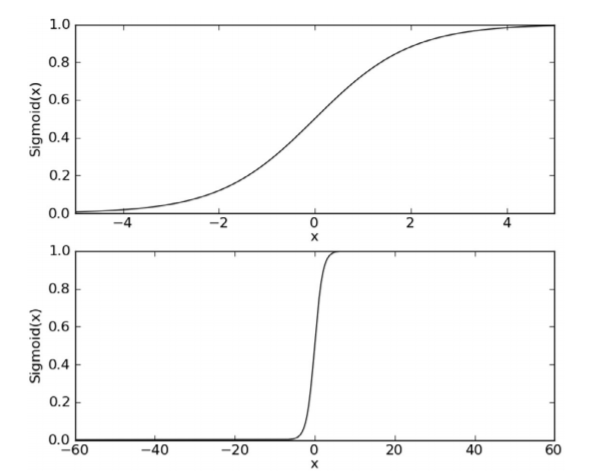
Sigmoid函数的输入记为z,由下面公式得出:
z = w0X0 + w1X1 +W2X2+...+WnXn
如果采用向量的写法,上述公式可以写成z = wT x,它表示将这两个数值向量对应元素相乘然后 全部加起来即得到z值。其中的向量x是分类器的输入数据,向量w也就是我们要找到的最佳参数。
下面首先介绍梯度上升的最优化方法,我们将学习到如何使用该方法求得数据集的最佳参数。
梯度上升法基于的思想是:要找到某函数的最大值,梯度算法的迭代公式如下:
w: = w + 梯度*步长*f(w)
二、代码实现算法的过程
1、程序清单一:Logistic 回归梯度上升优化算法
1 #加载数据集 2 def loadDataSet(): 3 #定义一个列表保存dataMat数据集 4 dataMat = [] 5 #定义一个列表labelMat保存数据集对应的标签 6 labelMat = [] 7 #根据文件绝对路径使用open函数得到文件操作对象fr 8 fr = open('E:dianzishumachinelearninginaction-master\Ch05\testSet.txt') 9 #fr.readlines():将文件内所有的数据内容都取出来 10 #使用for循环逐行地把所有的数据读取 11 for line in fr.readlines(): 12 #line.strip():去除当前行这条数据记录两端的空格 13 #.split():然后再按空格分割每行的元素 14 lineArr = line.strip().split() 15 #使用dataMat保存这条数据,并最前面增加一列,这一列的值全部都是1, 16 #用来表示公式:y=kx+b中的常数b 17 #另外两个分别是属性或数据集的特征 18 dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) 19 #保存当前这条数据集对应的标签 20 labelMat.append(int(lineArr[2])) 21 return dataMat,labelMat
1 def sigmoid(inX): #实现sigmoid公式的函数 2 return 1.0/(1+np.exp(-inX))
1 #这个函数是用来训练得到数据集特征的权重的 2 #dataMatIn:这个是训练数据集 3 #classLabels:这个是训练数据集记录对应的标签 4 def gradAscent(dataMatIn, classLabels): 5 #将dataMatIn数据集类型转变成矩阵类型 6 dataMatrix = np.mat(dataMatIn) 7 #将classLabels标签类型转变成矩阵类型,并通过调用transpose来把它转置(转置就是:行变列,列变行) 8 labelMat = np.mat(classLabels).transpose() 9 #获取训练数据集的行数和列数 10 m,n = np.shape(dataMatrix) 11 #定义一个步长,用来控制权重的变化速度 12 alpha = 0.001 13 #设置循环迭代训练的次数 14 maxCycles = 500 15 #定义各个属性的权重,开始每个属性的权重都默认为1 16 weights = np.ones((n,1)) 17 #开始迭代训练数据集 18 for k in range(maxCycles): 19 #dataMatrix*weights计算出一次函数的y值 20 #调用sigmoid概率分类函数,得到训练数据集的预测标签 21 h = sigmoid(dataMatrix*weights) 22 #计算真实标签与预测标签的偏差值 23 error = (labelMat - h) 24 #然后根据上面的预测偏差和迭代来不断地修正属性的各个权重 25 weights = weights + alpha * dataMatrix.transpose()* error 26 #最后函数返回训练得到的各个属性的权重 27 return weights
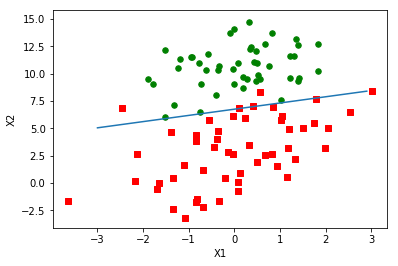
2、程序清单二、 画出数据集和Logistic回归最佳拟合直线的函数
1 #这个函数用来看训练得到的权重的用于分类的效果 2 #weights:训练得到的权重 3 def plotBestFit(weights): 4 #导入绘图的模块 5 import matplot 6 lib.pyplot as plt 7 #获取数据集 8 dataMat,labelMat=loadDataSet() 9 #将数据集变为数组数据类型 10 dataArr = np.array(dataMat) 11 #取得数据集的行数 12 n = np.shape(dataArr)[0] 13 #用来保存标签为一的数据集的第2列数据,当做坐标x值 14 xcord1 = [] 15 #用来保存标签为一的数据集的地3列数据,当做坐标y值 16 ycord1 = [] 17 #用来保存标签为0的数据集的地2列数据,当做坐标x值 18 xcord2 = [] 19 #用来保存标签为0的数据集的地3列数据,当做坐标y值 20 ycord2 = [] 21 #逐行地读取数据集 22 for i in range(n): 23 #判断这一行数据集的记录标签是不是1 24 if int(labelMat[i])== 1: 25 #获取标签为1的数据集第二列数据 26 xcord1.append(dataArr[i,1]) 27 #获取标签为1的数据集第三列数据 28 ycord1.append(dataArr[i,2]) 29 else: 30 #获取标签为0的数据集第二列数据 31 xcord2.append(dataArr[i,1]) 32 #获取标签为0的数据集第三列数据 33 ycord2.append(dataArr[i,2]) 34 #取得一个绘图操作对象 35 fig = plt.figure() 36 #获得一个子图对象 37 ax = fig.add_subplot(111) 38 #描绘标签为1的散点图,颜色是红色 39 ax.scatter(xcord1, ycord1, s=30, c='red', marker='s') 40 #描绘标签为0的散点图颜色是绿色 41 ax.scatter(xcord2, ycord2, s=30, c='green') 42 #定义一些x的取值 43 x = np.arange(-3.0, 3.0, 0.1) 44 #带入公式求得上面那些x值对应的y值,系数是训练得到的权重 45 y = (-weights[0]-weights[1]*x)/weights[2] 46 y = np.array(y) 47 #描绘x,y函数直线 48 ax.plot(x, y[0]) 49 #图X轴的标签 50 plt.xlabel('X1') 51 #图Y轴的标签 52 plt.ylabel('X2') 53 plt.show() 54 plotBestFit(weights)

3、程序清单三、 随机梯度上升算法
1 #这也是一个计算属性权值的函数 2 #dataMatrix:这个是训练数据集 3 #classLabels:这个是训练数据集记录对应的标签 4 def stocGradAscent0(dataMatrix, classLabels): 5 #获取数据集的行数和列数 6 m,n = np.shape(dataMatrix) 7 #定义一个常量用来控制weights的变化速度 8 alpha = 0.01 9 #定义每个属性的权重,开始默认值都是1 10 weights = np.ones(n) 11 #逐行地读取训练数据记录 12 for i in range(m): 13 #sum(dataMatrix[i]*weights):取得当前行各个特征值与它对应的权重相乘后再累加 14 #最后将上面的累加和传递到sigmoid函数处理,得到一个当前行的预测标签h 15 h = sigmoid(sum(dataMatrix[i]*weights)) 16 #求当前记录真实标签与预测标签的偏差 17 error = classLabels[i] - h 18 #然后根据上面的预测偏差和迭代来不断地修正属性的各个权重 19 weights = weights + alpha * error * dataMatrix[i] 20 #最后函数返回训练得到的各个属性的权重 21 return weights 22 23 weights = stocGradAscent0(np.array(dataMat),labelMat) 24 print('打印换一种函数求出权值:') 25 print(weights) 26 27 #这个函数用来看训练得到的权重的用于分类的效果 28 #weights:训练得到的权重 29 def plotBestFit(weights): 30 #导入绘图的模块 31 import matplotlib.pyplot as plt 32 #获取数据集 33 dataMat,labelMat=loadDataSet() 34 #将数据集变为数组数据类型 35 dataArr = np.array(dataMat) 36 #取得数据集的行数 37 n = np.shape(dataArr)[0] 38 #用来保存标签为一的数据集的地2列数据,当做坐标x值 39 xcord1 = [] 40 #用来保存标签为一的数据集的地3列数据,当做坐标y值 41 ycord1 = [] 42 #用来保存标签为0的数据集的地2列数据,当做坐标x值 43 xcord2 = [] 44 #用来保存标签为0的数据集的地3列数据,当做坐标y值 45 ycord2 = [] 46 #逐行地读取数据集 47 for i in range(n): 48 #判断这一行数据集的记录标签是不是1 49 if int(labelMat[i])== 1: 50 #获取标签为1的数据集第二列数据 51 xcord1.append(dataArr[i,1]) 52 #获取标签为1的数据集第三列数据 53 ycord1.append(dataArr[i,2]) 54 else: 55 #获取标签为0的数据集第二列数据 56 xcord2.append(dataArr[i,1]) 57 #获取标签为0的数据集第三列数据 58 ycord2.append(dataArr[i,2]) 59 #取得一个绘图操作对象 60 fig = plt.figure() 61 #获得一个子图对象 62 ax = fig.add_subplot(111) 63 #描绘标签为1的散点图,颜色是红色 64 ax.scatter(xcord1, ycord1, s=30, c='red', marker='s') 65 #描绘标签为0的散点图颜色是绿色 66 ax.scatter(xcord2, ycord2, s=30, c='green') 67 #定义一些x的取值 68 x = np.arange(-3.0, 3.0, 0.1) 69 #带入公式求得上面那些x值对应的y值,系数是训练得到的权重 70 y = (-weights[0]-weights[1]*x)/weights[2] 71 y = np.array(y) 72 #描绘x,y函数直线 73 ax.plot(x, y) 74 #图X轴的标签 75 plt.xlabel('X1') 76 #图Y轴的标签 77 plt.ylabel('X2') 78 plt.show() 79 80 #绘图观察这次处理得到权重的效果 81 plotBestFit(weights)
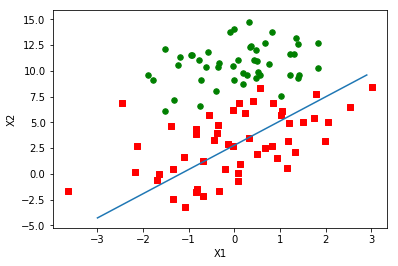
4、程序清单四、改进的随机梯度上升算法
1 import numpy as np 2 3 #这是又是另一种求得数据集特征属性权值的函数 4 #dataMatrix:这个是训练数据集 5 #classLabels:这个是训练数据集记录对应的标签 6 #numIter=150:循环迭代更新权重的次数,默认循环150次 7 def stocGradAscent1(dataMatrix, classLabels, numIter=150): 8 #获取数据集的行数和列数 9 m,n = np.shape(dataMatrix) 10 #定义每个属性的权重,开始默认值都是1 11 weights = np.ones(n) 12 #最外层循环是控制里面的for循环重复运行多少次 13 for j in range(numIter): 14 #数据集的行号 15 dataIndex = list(range(m)) 16 #每一行地读取数据集 17 for i in range(m): 18 #定义一个alpha用来控制属性权重的变化速度 19 alpha = 4/(1.0+j+i)+0.0001 20 #随机获取数据集一行的行号 21 randIndex = int(np.random.uniform(0,len(dataIndex))) 22 #dataMatrix[randIndex]:根据上面获取的行号,取得对应那一行的数据记录 23 #sum(dataMatrix[randIndex]*weights):取得当前行各个特征值与它对应的权重相乘后再累加 24 #最后将上面的累加和传递到sigmoid函数处理,得到一个当前行的预测标签h 25 h = sigmoid(sum(dataMatrix[randIndex]*weights)) 26 #求当前记录真实标签与预测标签的偏差 27 error = classLabels[randIndex] - h 28 #然后根据上面的预测偏差和迭代来不断地修正属性的各个权重 29 weights = weights + alpha * error * dataMatrix[randIndex] 30 #删除已经取到了的行号,避免下次重复取到重复行 31 del(dataIndex[randIndex]) 32 #最后函数返回训练得到的各个属性的权重 33 return weights 34 35 weights = stocGradAscent1(np.array(dataMat),labelMat) 36 print('打印stocGradAscent1函数求出权值:') 37 print(weights) 38 39 #这个函数用来看训练得到的权重的用于分类的效果 40 #weights:训练得到的权重 41 def plotBestFit(weights): 42 #导入绘图的模块 43 import matplotlib.pyplot as plt 44 #获取数据集 45 dataMat,labelMat=loadDataSet() 46 #将数据集变为数组数据类型 47 dataArr = np.array(dataMat) 48 #取得数据集的行数 49 n = np.shape(dataArr)[0] 50 #用来保存标签为一的数据集的地2列数据,当做坐标x值 51 xcord1 = [] 52 #用来保存标签为一的数据集的地3列数据,当做坐标y值 53 ycord1 = [] 54 #用来保存标签为0的数据集的地2列数据,当做坐标x值 55 xcord2 = [] 56 #用来保存标签为0的数据集的地3列数据,当做坐标y值 57 ycord2 = [] 58 #逐行地读取数据集 59 for i in range(n): 60 #判断这一行数据集的记录标签是不是1 61 if int(labelMat[i])== 1: 62 #获取标签为1的数据集第二列数据 63 xcord1.append(dataArr[i,1]) 64 #获取标签为1的数据集第三列数据 65 ycord1.append(dataArr[i,2]) 66 else: 67 #获取标签为0的数据集第二列数据 68 xcord2.append(dataArr[i,1]) 69 #获取标签为0的数据集第三列数据 70 ycord2.append(dataArr[i,2]) 71 #取得一个绘图操作对象 72 fig = plt.figure() 73 #获得一个子图对象 74 ax = fig.add_subplot(111) 75 #描绘标签为1的散点图,颜色是红色 76 ax.scatter(xcord1, ycord1, s=30, c='red', marker='s') 77 #描绘标签为0的散点图颜色是绿色 78 ax.scatter(xcord2, ycord2, s=30, c='green') 79 #定义一些x的取值 80 x = np.arange(-3.0, 3.0, 0.1) 81 #带入公式求得上面那些x值对应的y值,系数是训练得到的权重 82 y = (-weights[0]-weights[1]*x)/weights[2] 83 y = np.array(y) 84 #描绘x,y函数直线 85 ax.plot(x, y) 86 #图X轴的标签 87 plt.xlabel('X1') 88 #图Y轴的标签 89 plt.ylabel('X2') 90 plt.show() 91 92 #绘图观察这次处理得到权重的效果 93 plotBestFit(weights)