
作者 | 韦仁忠
来源 | 阿里开发者公众号
关于Serverless
看到如今Serverless在云计算行业喷薄欲出的态势,像极了《星星之火,可以燎原》中的描述:虽然不能预测未来的发展和变化,但对于云计算来说这是个相对确定的方向。
从Google Trends的Serverless关键字的趋势可以看到,对于Serverless的搜素一直居高不下,并且在未来的一段时间内也会保持相当的热度。从2015年开始,以AWS为代表的国外云计算大厂也在不断的布局Serverless相关的产品,AWS Lambda、Aliyun FAAS,数据库领域的Aurora Serverless、RedShift Serverless、Azure SQL Database等。

学术界对Serverless的研究热度也不亚于工业界对商业化方案的追求,文末列出了一些相关文章作为参考。对于云计算往Serverless演进的趋势,学术界也经历过一些质疑,2018年“Serverless Computing: One Step Forward, Two Steps Back”[3] 文章曾经对Serverless的发展给现在IT基础设施带来的冲击表示过担忧,但2019年同一拨人在这个方向上又表现出了支持和乐观的态度。从Serverless领域被引用次数较多的论文上看到,主流科研机构对Serverless的趋势和方向研究上趋于一致,研究重点也慢慢从“why”转变为“how”[6]。
何为Serverless?为什么Severless是个趋势?“Cloud Programming Simplified: A Berkeley View on Serverless Computing”[5] 这篇文章为代表做了一个比较全面的分析和预测。同样是Berkeley在2009年发表的另一篇文章“Above the Clouds: A Berkeley View of Cloud Computing”[7] 预测了云计算作为IAAS基础设施的观点。该篇文章延续了之前的风格,分析了现状和难点,预测了云计算2.0的形态Serverless作为下一代基础设施,也定义了Serverless的主要三个特征:
- 资源的解耦和服务化:弱化了存储和计算之间的联系。服务的储存和计算被分开部署和收费,存储不再是服务本身的一部分,而是演变成了独立的云服务。这使得计算变得无状态化,更容易调度和扩缩容,同时也降低了数据丢失的风险。
- 自动弹性伸缩:代码的执行不再需要手动分配资源。不需要为服务的运行指定需要的资源(比如使用几台机器、多大的带宽、多大的磁盘等),只需要提供一份代码,剩下的交由 Serverless 平台去处理就行了。当前阶段的实现平台分配资源时还需要用户方提供一些策略,例如单个实例的规格和最大并发数,单实例的最大 CPU 使用率。理想的情况是通过某些机器学习算法来进行完全自动的自适应分配。
- 按使用量计费:Serverless按照服务的使用量(调用次数、时长等)计费,而不是像传统的 Serverful 服务那样,按照使用的资源(ECS 实例、VM 的规格等)计费。
值得一提的是[5]这篇文章有众多云计算厂商的背书,包括AWS、Micorsoft、Google、Alibaba等,同时文章也直接以AWS Lambda服务作为样板去分析Serverless的问题。Serverless本身的技术难度,这篇文章罗列了多项内容,这里不做赘述,可以具体读一下文章。
关于Serverless的技术实现[3]给出了一个可行的系统实现方式,当然还是以FAAS为背景。其中提到Serverless关键技术路径包括:
- 统一的标准运行环境支持多语言的运行时统一管理
- 轻量级/蝇量级安全容器(在[4]中额外提到安全和隔离的重要性)
- 冷热容器池设计做极致的多租户复用能力
- 高效的函数调度能力
其中,函数计算的实现方式,却与数据库Serverless息息相关。
数据库的Serverless
数据库品类繁多,关系型数据库自1979年E. F. Codd对于关系模型的描述[7]开始,后来者大多只是模仿,而尚未在用户接受度和规模上有超越。
数据库不仅仅是一个“stateful”的应用,而且是一个“state-heavy”的应用。数据库是Serverless最不友好的应用之一,包括云原生基础设施kubernates对于stateful应用的支持,也是等到StatefulSet和operator之后才有一个比较好的解决方案。而在这之前数据库都是作为Serverless对状态做解耦和状态下沉的工具,也是全栈Serverless解决方案中最难攻坚的最后一个堡垒。
对于Serverless的定义,文章给出来一个公式:Serverless = FAAS+ BAAS。将FAAS(Functions as a Service)定义为事件、API、消息驱动的计算层;将BAAS(Backends as a Service )定义为类似数据库、消息队列等后端服务。
“State-heavy applications will remain as BaaS”是目前对于数据库的一个基本认知,但这与数据库本身是否具备一定程度的Serveless能力其实是两回事。前者强调的是在应用向Serverless做架构转型的过程当中,数据库的大量状态存储做不到FAAS这样即开即用的能力,只能作为“+”来对接Serverless生态;后者说的是在某种程度上也能够满足“资源解耦”、“自动弹性”、“按使用量付费”的特点,某种程度上也可以认为是Serverless。
数据库Serverless的难点究竟在哪里?
数据库做Serverless有若干难点[4],总结如下:
- Serverless没有内置的持久化存储,需要依赖远端存储,这就会导致在延时上较高;
- 客户端是基于连接的方式访问数据库,在客户端往往会维护连接池的方式供应用访问,而函数计算往往具备飘忽不定的网络地址,与数据库传统的IP+User+password鉴权的方式迥异;
- 很多高性能的数据库使用共享内存技术,而FAAS本身不具备共享内存的能力,会使得计算和数据库之前的资源动态扩展能力不一致
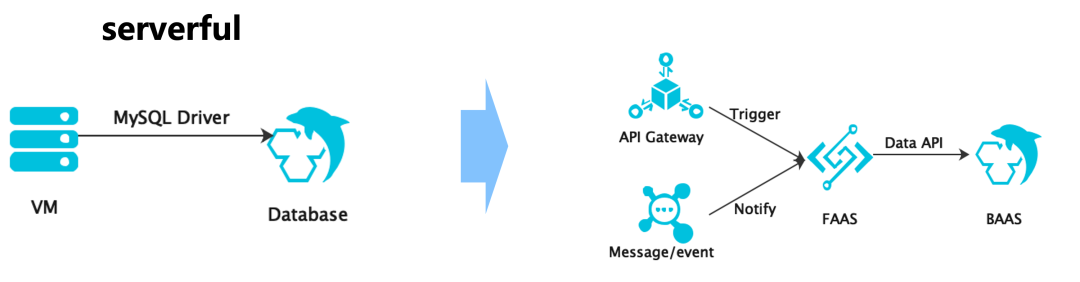
其中尤其要注意的是第2点,在应用进FAAS之后,当前的数据库访问方式已经不适用于Serverless生态:
- 服务器与DB做连接保持,这就意味着访问状态是由客户端和数据库共同维护,而FAAS无法做到连接持续保持的能力;
- 服务器通过driver和连接池的方式访问数据库,每次的连接初始化相对较重,FAAS上无法承受如此重的连接初始化工作;
- 服务器访问鉴权通过user/password/ip的方式访问数据库,而FAAS多租户场景所有用户共享IP地址池,user/password内置到FAAS当中也暴露了极大的安全风险;
数据库需要一种新的访问方式,直接影响到数据库能否作为Serverless生态当中的一部分,直接影响到当前Serverless应用做全栈Serverless改造。其重要程度甚至大于数据库Serverless(资源解耦、极致弹性、按使用量付费等)本身。
当然数据库本身要做的事情远远不止如此,数据库本身要实现高效的弹升弹降,涉及到更多的管控和内核紧密的联动。
他山之石
行业翘楚AWS在Serverless相关的布局从2015年推出Lambda开始,引领着这个方向的发展。这里更多的关注在数据库方面,结合AWS在Aurora Serverless上的取舍,洞察AWS对于数据库Serverless的理解。
从Aurora Serverless V1发表于2018年,在Serverless的理念上做了大胆的创新,做了几件事情:
- 以ACU的方式去统一底层的资源,不再对上层暴露底层具体的机型和代数。1ACU“相当于”2GiB的RAM,统一对底层资源做了标准化和规范化的处理。这与Serverless理念中资源的解耦、以及对底层资源的屏蔽一致;
- 支持自动启停,在无负载的情况下支持将计算节点降低至“0”。将Serverless中按资源使用量付费体现到极致,但也带来了另外的问题。自动启停在一般场景下首次拉起需要30s左右,牺牲了部分auto scale的能力;
- 数据库弹性过程中内核相关buffer pool等参数随着资源配合的变化而发生变化,这也是数据库这种特殊的应用场景需要做的一些特殊处理;
- 2019年推出Data API功能,补全了数据库作为BAAS接入FAAS的能力,解决了前面提到的生态兼容的问题。
2020年发布的Aurora Serverless V2的介绍视频并提供内测申请,而在前不久V2也正式GA。从Aurora Serverless V2的能力来看,在Serverless能力上做了增强和取舍:
- 将V1中弹性能力继续提升至秒级,做极致快速的弹性。将V1中跨机升级的能力优化为本地升级的能力,保证业务在弹性过程中不受损。从Aurora Serverless只在3.0.2这一个版本上支持可以看出,内核层针对Serverless场景也做了大量的优化;
- 去除了V1中关于自动启停的能力,用户可以手动启停实例;更加关注实例的auto scale能力,最小资源降低至0.5ACU而非0,牺牲了部分按使用量付费的能力,这也是一种取舍;
- 将弹性缩容的策略做得更加保守,以保证业务压力情况下对业务的影响尽可能小。
从V1到V2的变化,对比V2和V1的User Case可以看出,Aurora Serverless V2主要解决的是从“开发测试环境”到有限场景下的生产环境的转变,至于底层的实现原理,可以从一丝丝蛛丝马迹中去探究。结合其他云的做法,Serverless的能力目前还是看重这个理念,各个厂商也在以自己的产品形态去向贴近这个理念,至于说一统行业标准的产品化方案,还为时过早,这一领域大有可为。
未来可期
从2009年开始,云的能力不断增强,云的本质是资源的池化,而这些资源不仅仅包含硬件资源,更包含专业的技术人才、以及核心的技术专利标准等。经过了十来年在规模和成本上的激烈竞争,IAAS资源也在不断的向Serverless的方向演进,以阿里云本身为例,包括弹性的存储AutoPL、弹性的容器ECI、Serverless服务引擎SAE。底层能力的增强也意味着上层PAAS层和SAAS服务有了更快的向Serverless演进的路径,阿里云数据库就是其中受益的一方PAAS。
如果开源托管产品RDS可以看成是云数据库服务1.0,自研产品如PolarDB和Aurora可以看成是云数据库2.0,那么Serverless将会是云数据库服务的3.0。其中,客户应用跟数据库交互方式的改变(例如,从JDBC/ODBC向Restful API转变),将会具有重要意义。
从艾瑞2022年初对数据库云管平台的发展趋势预测[9]、以及结合云的趋势和Serverless本身,我们可以对Aurora Severless未来的发展方向做一些大胆的预测:
- 智能化加持:从re:Invent2021发布的Devops Guru产品上看到,AWS正在智能化场景下进行追赶。内置的智能化引擎对Serverless的场景可以做出更多的精准预测,让“响应式”扩容升级为“响应式兜底,智能化加持”的双引擎驱动;
- 资源解耦和极致的弹性:共享内存技术、Brust IO能力等会推着Serverless将更多的资源进行解耦,以及进行独立的升降配;
- 更多的Serverless手段:扩容是最有效直接应对数据库流量的方式,但是有了更多智能化的手段之后,单纯的“扩容”已经有更多选择,自动索引优化、智能调参会是很好的选项;
- 自动的横向扩展能力:scale out和scale up同样可以应对业务流量的变化,但scale out的复杂程度要远远高于scale out本身,也是个可能的选项;
- 低成本硬件大规模使用:ACU的单位定义屏蔽了底层资源属性,ARM、x86还是RISC-V已经不是那么重要,标准化归一化的算力能力让更多类型的硬件无缝无感的接入到Serverless当中。
阿里云 RDS MySQL 也在2022年4月份推出了Serverless版本,我们将在后续的文章中做重点的介绍,我们会以一个标准的网站应用(前端页面+API服务器+数据库)为样板,介绍如何在FAAS+BAAS的架构下一步步做全栈Serverless的改造,真正做到“0”服务器。
作者介绍:
韦仁忠,当前主要负责RDS MySQL管控产品建设,欢迎有志之士加盟RDS产品部,邮箱:renzhong.weirenzho@alibaba-inc.com
参考文献
2016: "Emerging Technology Analysis: Serverless Computing and Function Platform as a Service", Gartner, Tech.
2017: "Serverless Computing: Current Trends and Open Problems", IBM Research
2017: "Serverless Computing:Design, Implementation, and Performance",IEEE 2017 ICDCSW
2018: "Serverless Computing: One Step Forward, Two Steps Back ", CIDR 2019
2019: "Cloud Programming Simplified: A Berkeley View on Serverless Computing", EECS 2019
2020: "Serverless Applications: Why, When, and How?", IEEE Software
2009: "Above the Clouds: A Berkeley View of Cloud Computing", EECS 2009
1970: "A relational model of data for large shared data banks", Commun. ACM 1970
2022:
本文为阿里云原创内容,未经允许不得转载。