NLP算法在搜索链路中的应用
这是一个完整的从查询词到搜索结果的链路,其中自然语言处理(NLP)算法发挥作用的地方主要在第二阶段的查询分析,该阶段包含多个NLP算法模块,如分词、纠错、实体识别、词权重、同义词以及语义向量等。开放搜索结合了文本和语义向量实现多路召回,从而满足不同业务场景的搜索效果需求。

查询分析
NLP算法可以在这几个子模块发挥作用:
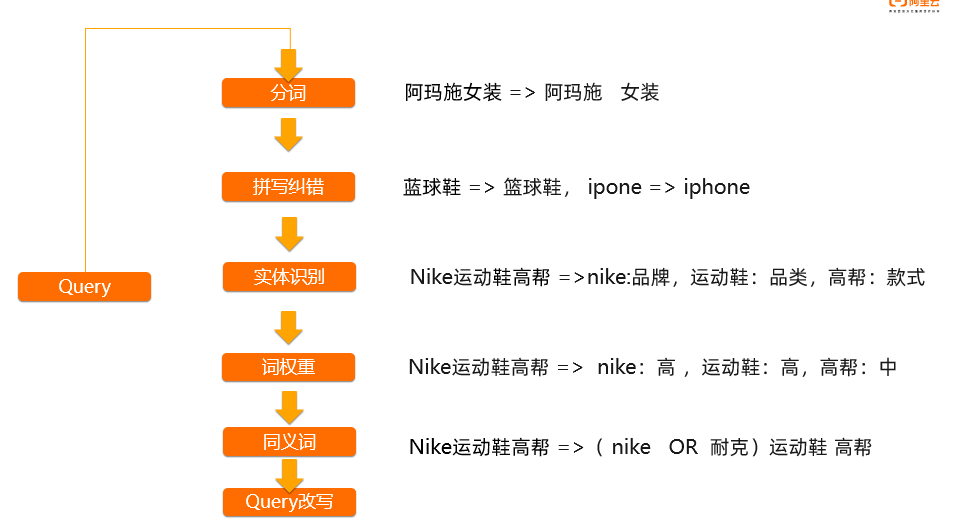
- 分词,精准的分词能提高检索效率,让召回结果更加精准。
- 拼写纠错,对用户输入query中出现的拼写错误进行自动纠错,提升用户搜索体验。
- 实体识别,为query 中的每个词打上对应的实体标签,从而为后续的query改写和排序提供关键特征。
- 词权重,会对每个词划分不同的权重,在查询结果时去做丢词的重查,提升搜索准确率并降低无结果率。
- 同义词,扩展出相同、相近意思的词来扩大召回范围。
- 最后,经过完整的查询分析模块之后,进行整体的query改写,将用户输入query转换成向量和查询串,到相应搜索引擎中进行查询。
自研NLP模型难点
自建模型领域适配难
- 自研搜索在具体场景业务中效果差强人意;
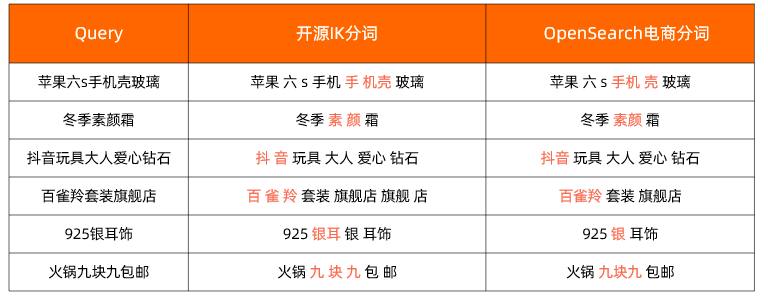
例如:开源IK分词VS电商行业增强版
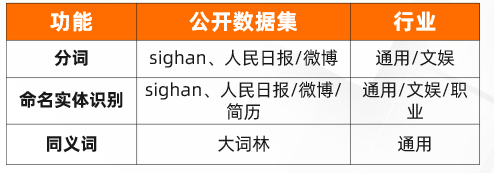
公开行业模型少
- 云服务产商基本只提供通用模型,公开行业数据集也主要覆盖通用领域;
![]()
自主参与领域模型优化难度大
- 构建一个行业搜索NLP模型主要包含一下流程:
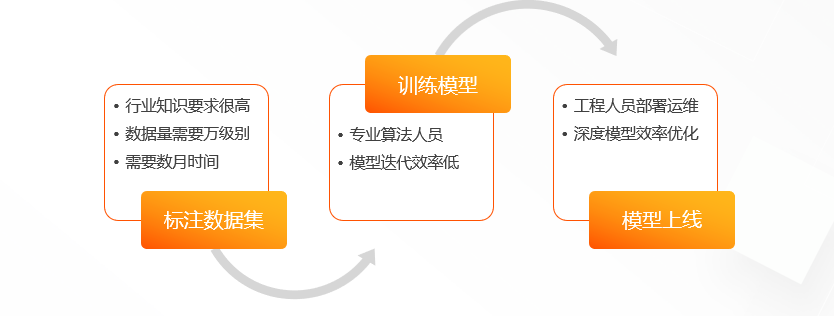
- 首先是标注数据集,这一步对于行业知识的要求非常高,同时数据量也至少需要达到万级别,标注这些数据的耗时可能长达数月。
- 接着是模型训练,这一步需要专业的算法从业人员进行开发调试,如果对算法不熟悉,将大幅降低模型效果与迭代效率。
- 最后是模型上线,这一步需要工程、算法人员共同部署运维,如果涉及到深度模型,还需进行工程性能相关的效率优化。
从零开始自主开发行业模型困难重重,在数据集标注阶段其实就已经存在了很多的挑战:
- 标注难点
- 分词标注领域知识要求高,交叉歧义判断难;
例如:药物的名称:利多卡因氯己定气雾剂 | 利多卡因 氯己定 气雾剂
地址:南召县四棵树乡王营村 | 南召 县 四棵树 乡 王营 村
洗衣服粉 | 洗衣 服 粉b
- 实体识别标注领域知识要求高;
例如:澳洲爱他美(母婴品牌)金装一段、科比(球鞋系列)
pytorch实现GAN(算法模型)
针对分词、查询分析模型影响搜索效果,行业模型训练开发难度大等问题,开放搜索提供了轻量化客户定制解决方案:
开放搜索轻量化客户定制解决方案
方案效果介绍及选型
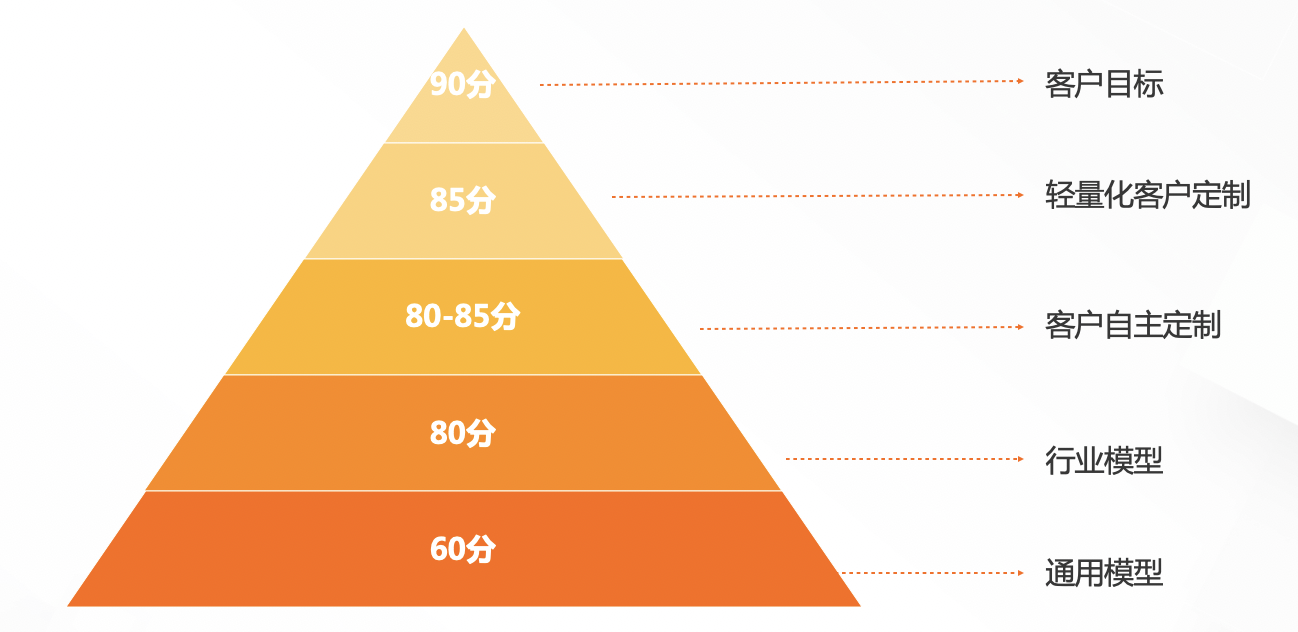
- 直接使用通用模型大概能达到60分的效果;
- 开放搜索产品结合阿里经济体内数据资源积累,提供开箱即用的行业模型(电商、内容、教育、游戏、互娱等)对客户场景具备不错的适用性,可以达到80分的效果;
- 当客户有针对性优化,团队资源充足情况下,可以自主定制,进行领域模型优化,但NLP任务的标注门槛相对较高,标注质量不可控,模型训练难度大、周期长,很难突破85分;
- 轻量化客户定制可以减少客户标注量级,实现完全无标注或少量简单标注。同时基于行业、垂类、业务的特殊数据,结合原有成熟的NLP模型,让定制与扩展更简单,从而直接达到85分效果;
轻量化客户定制召回模型-定制分词器
分词是搜索引擎的重要基础组件,分词效果会直接影响搜索召回和最终结果。由于业务场景的多样性,不同行业、垂类、业务都有各自的特殊性,通用、开源的分词器很难满足具体到每个客户的分词要求。
阿里云智能开放搜索(OpenSearch)提供了丰富的行业分析器,基于对应的行业分析器,经过简单的配置、训练,得到业务专属的定制分析器。整个定制过程无需进行额外的数据对接工作,召回定制模型训练会自动抽取已有数据进行适配。
通过定制召回模型-业务定制分析器功能,客户可以基于预训练行业NLP模型和自身业务数据,定制专属分析器,减小特殊行业、垂类、业务分词场景下的bad case,无需进行数据标注,实现一站式搜索引擎开发与NLP模型定制,智能化提升搜索效果。
适用客户
- 搜索为核心业务重要场景,对搜索有更高效果要求的客户
- 行业、垂类、业务特殊,有较多专属名词的客户
- 搜索投入人力有限,算法同学相对较少的客户
开放搜索后续还会上线更多定制召回模型,例如:定制拼写纠错、定制同义词等,敬请期待~
效果对比
- 电商社区场景
智能开放搜索(OpenSearch)提供的电商行业模型虽然已经能正确处理大部分的case,但仍存在一些切错的情况。结合客户数据,基于电商行业模型训练定制分词模型后,badcase基本都被修复。

- 地址场景
产品目前虽然还未开放地址行业模型,通用模型对于一些语义歧义多的case处理不好,但是结合客户数据,基于通用模型训练定制分词模型后,也可以修复大部分badcase。

小结:
- 如果您的业务目前正在或准备使用开放搜索(OpenSearch)的行业版,可以在行业模型的基础上进行定制分词模型的训练;
- 如果开放搜索还没有提供与您业务接近的行业版,建议选择在通用版模型的基础上进行定制,这种情况需要数据尽量多,分布尽量全面均衡,有助于提升定制分词模型的效果。
模型接入流程
- 创建并训练模型;
- 创建模型,训练模型
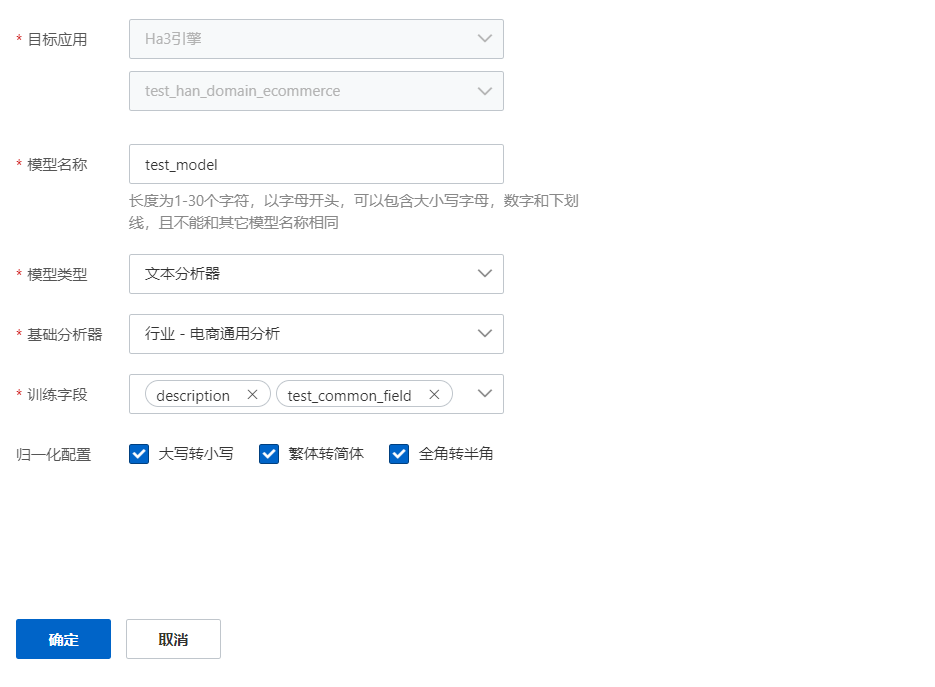
- 创建自定义分析器(可选)
- 在搜索算法中心>分析器管理页面,选择文本分析器创建,选择分析器类型为定制模型分析
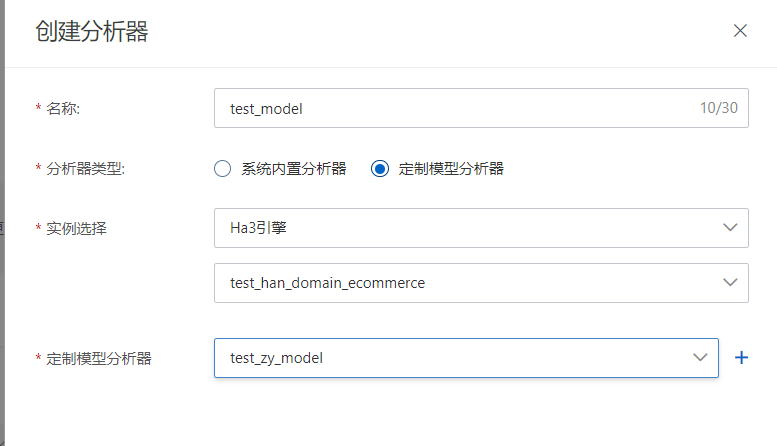
- 创建完成后,可使用定制自定义分析器进行分词测试,以及

- 配置定制分析器模型
- 定制分析器创建完成后,即可通过
- 在配置索引结构页面,找到对应的索引,替换成已配置定制召回模型的定制化分析器,并选择需要生效的模型版本;
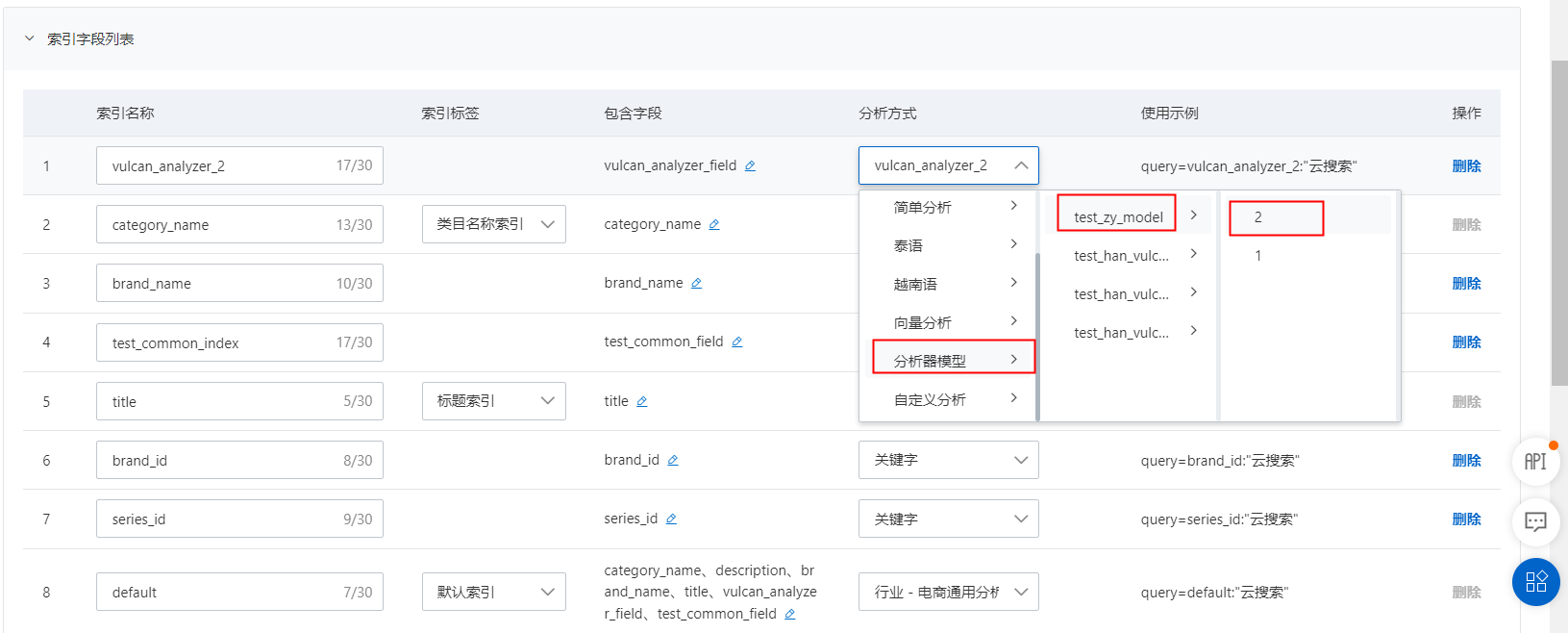
- 索引重建结束,即可在搜索测试界面测试效果;
本文为阿里云原创内容,未经允许不得转载。