简介:在规划中,Quick BI制定了产品竞争力建设的三大方向,包括Quick(快)能力、移动端能力和集成能力。针对其中的产品“报表查看打开慢”“报表开发数据同步慢”等性问题开展专项战役——Quick战役,以实现展现快、计算快,为使用者提供顺滑体验为目标。
“Quick”是产品始终追求的目标
Quick BI数据可视化分析平台,在2021年二次入选了Gartner ABI魔力象限,这是对产品本身能力强有力的认证。在不断夯实B I的可视化体验和权限管控能力之外,推进Quick BI的全场景数据消费能力,让数据在企业内最大限度的流转起来。
在规划中,Quick BI制定了产品竞争力建设的三大方向,包括Quick(快)能力、移动端能力和集成能力。针对其中的产品“报表查看打开慢”“报表开发数据同步慢”等性问题开展专项战役——Quick战役,以实现展现快、计算快,为使用者提供顺滑体验为目标。
双引擎成就Quick全新体验
无论是开发者还是阅览者,若想要在使用Quick BI的过程中获得流畅快速的体验,可能在这两个方面进行优化:
在数据报表开发的过程中,大量级数据需要在一定范围的时间内响应,即计算要快;
面对报表的查看者,首屏打开和下拉加载的时间需要在一定范围内完成,即展现要快。
Quick BI推出计算引擎和渲染引擎,以双引擎的方式为产品全力加速。
1、计算引擎(Quick引擎)
包含原有直连模式,新增加速模式、抽取模式、智能缓存模式,用户按照不同场景的不同需求,通过配置开关进行模式的选择。在数据集开发和数据作品制作的过程中获得加速体验,可以有效提升用户报表的数据查询速度,减少用户的数据库查询压力。
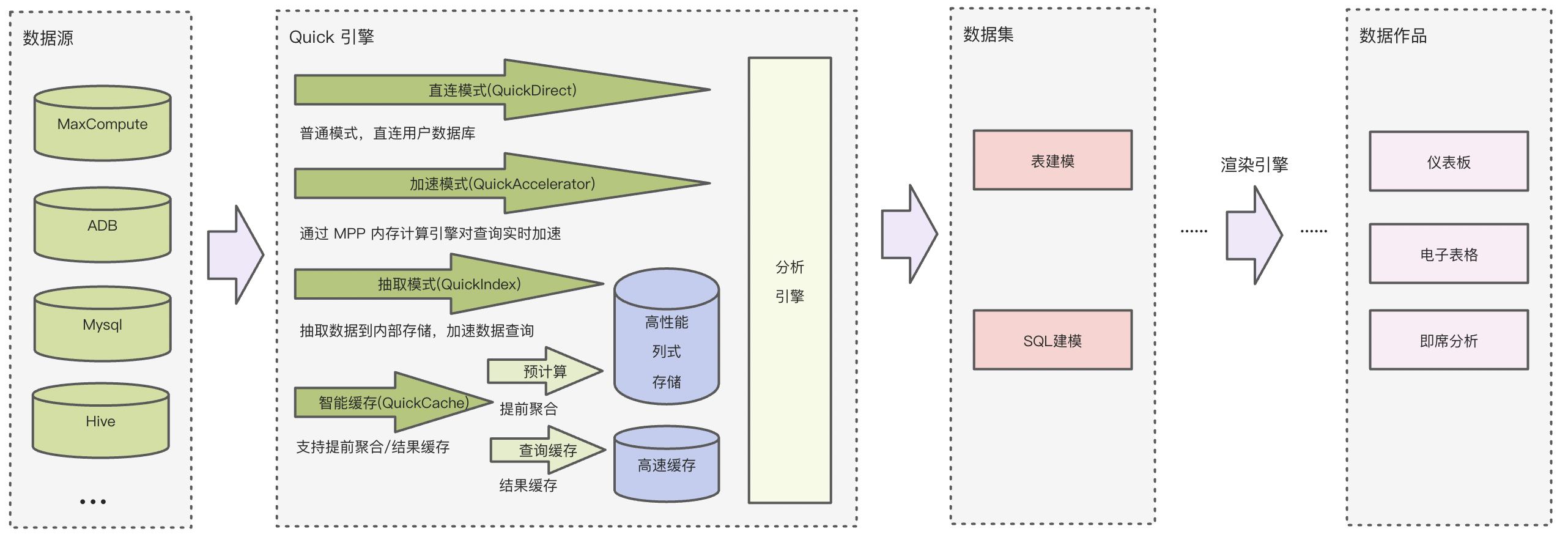
实时加速
基于 MPP 内存计算引擎,查询中实时从数据库(调/读)取数据,并在计算引擎的内存中进行计算,有效提升用户数据计算的性能,适用于对数据时效有高要求的情况。
抽取模式
把数据库或数仓的数据抽取到Quick引擎的高性能列式存储引擎中,支持全量模式和增量模式,分析计算负载直接在Quick BI引擎中进行,充分利用Quick引擎性能的同时,降低用户数仓的负担,适用于没有独立数仓或数仓负载过重的情况。
智能缓存
提供的2种缓存模式都可以直接返回结果,提升用户查询速度,减少数据库访问次数。
数据集缓存
将用户已经查询过的结果缓存在 Quick BI 高速缓存组件内,一段时间内完全一致的查询可以直接返回查询结果。
智能预计算
算法根据用户的历史查询记录,对数据集的查询进行预聚合,提前计算出用户所需的结果,保存在高性能存储中。一旦用户查询命中,则直接返回结果。
2、渲染引擎
负责取得肉眼可见页面的内容,包括图像、图表等,并进行数据信息整理,以及计算网页的显示方式,然后输出并展现。由于BI场景的报表(仪表板、电子表格、门户等)内容相当复杂,渲染引擎的加速可以非常直接的影响Quick BI报表的打开速度,优化用户的报表阅览体验。渲染引擎的加速动作无需进行任何配置,无声地服务整个分析流程。
渲染引擎进行了如下整体升级:
- 资源(js/css/ajax等)加载优化:包括预加载、按需加载、任务调度、TreeShaking等
- 前端计算&执行优化:数据流节流、懒数据策略、mutable改造、深克隆等计算优化等
- 可视化升级:底层可视化统一,桑基图等大数据量下解析优化、渲染次数收敛等
- 移动端升级:包体积优化(压缩前20.6M减少至5.6M)、图表预加载、资源本地化缓存等
- 查询链路优化:支持 MaxCompute 加速查询、登录层优化、防止配置查询缓存穿透、缓存优化等
- 性能工具升级:SQL诊断支持 MaxCompute 数据源,并支持 SQL 诊断工具的国际化等
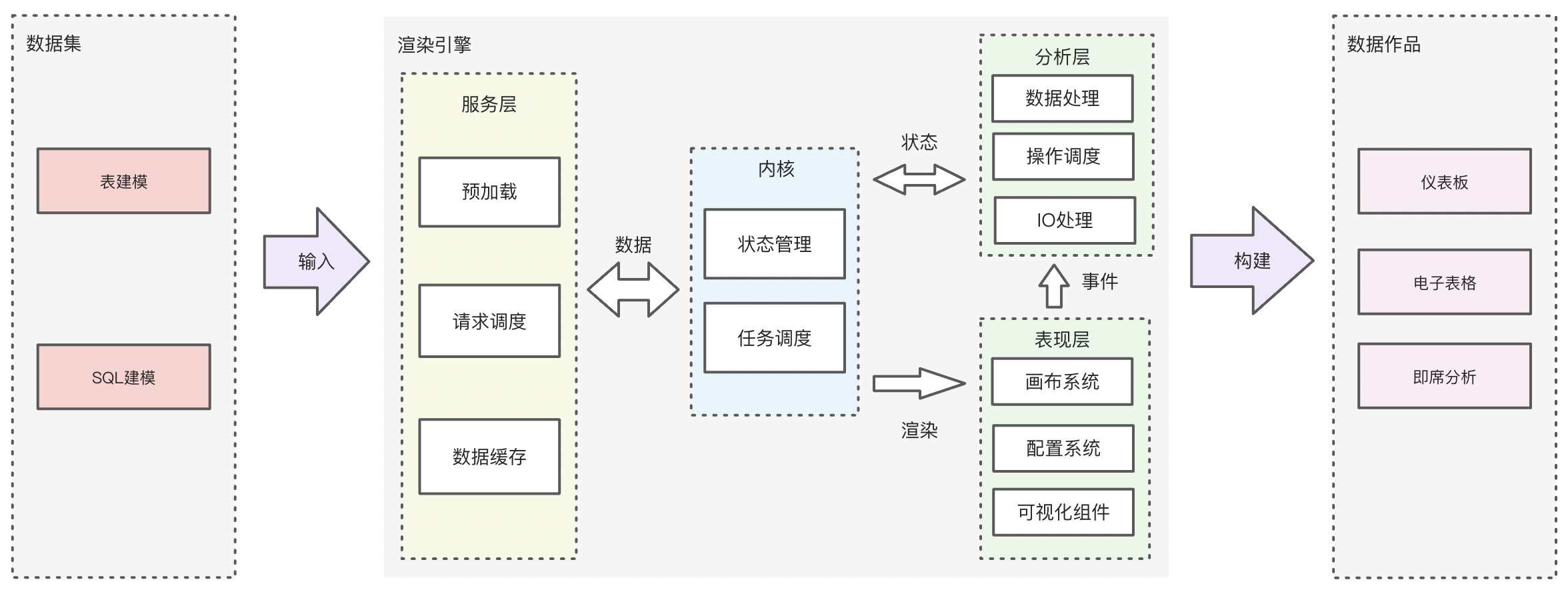
任务调度机制
支持在各段加载和执行流程中利用组件或函数控制CPU时间和网络占用优先级,从而将首屏内容的展示时间点缩短至少了30%。
截流渲染机制
支持Redux类数据流体系,以配置化方式控制单位时间组件渲染次数,组件平均渲染次数减少90%以上。
按需计算机制
按需加载和执行JS逻辑组件及其资源,利用LazyObject思路(即:使用时初始化执行,而非定义时)进行按需调用,LazyCache思路(即:命中时计算和缓存,而非实时)进行数据流模型计算,节省约30%的CPU时间以及40%的网络占用。
预加载机制
通过将原本串行依赖的流程逻辑按不同时机并行(如:当页面拉取JS资源时同时拉取后端数据,在空闲时预加载下一屏内容),根据历史使用习惯预先加载后续可能访问的内容,达到瞬时查看的效果。
资源本地化缓存机制
将js等资源本地化的形式,加上根据不同设备(移动端等)的资源管理策略,有效解决系统内存释放导致的缓存失效,弱网环境导致的资源加载缓慢等问题。
经过一系列核心能力的升级和特定场景的针对性优化,操作平均FPS(每秒传输帧数)可达55左右,较复杂报表下,首屏加载时间也从最初18秒降至3秒以内(中等简单报表2秒内),结合Quick引擎,还可以支持10亿级数据量的报表3秒内展现。
典型场景下的性能体验全面提升
1、数据开发视角的场景方案
(1)报表展示的数据在一定时间内固定不变
有些客户对数据需要每天进行一次汇总,并通过 Quick BI 的可视化图表以日报形式展示出来。这些展示的数据在下一次汇总之前都不会发生变化,同时这些汇总数据比较固定,不需要阅览报表的人主动更改查询条件。
如是场景,推荐开启数据集上的缓存功能。用户可以自行设置缓存的有效期,在有效期内,相同的查询会命中缓存,直接将该周期内第一次查询的结果毫秒级返回。以上述场景为例,用户可以开启 12 小时的缓存,这样日报只会在第一次打开时进行数据查询,之后一整天的时间,一旦客户点击打开,报表就会立刻展现。

(2)报表数据存在较多变化,对非实时数据进行分析
以大促为例,商家在活动结束后,对大促期间的销量、营业额以及营销投放效果进行复盘。数据分析包含很多维度,比如类目、地区、部门等等。商家的分析师或者决策者在查看报表时,往往会对维度进行调整、变更、钻取,来获得更加深入的洞察。这个场景下用户数据查询的动作多变,上述的缓存策略往往很难命中。
此时,可以在数据集的 Quick 引擎中开启抽取加速。抽取加速默认全表加速,允许用户同步T-1 的数据到 Quick 引擎高性能存储及分析模块中,后续的查询和计算会直接在 Quick 引擎中进行,减少用户数据库的性能压力。抽取加速可以做到亿级数据,亚秒级响应。
与此同时还可以开启智能预计算模式, 会对用户的查询历史进行分析, 提前对可能的查询进行预聚合。用户的查询如果命中,则会直接返回聚合结果。
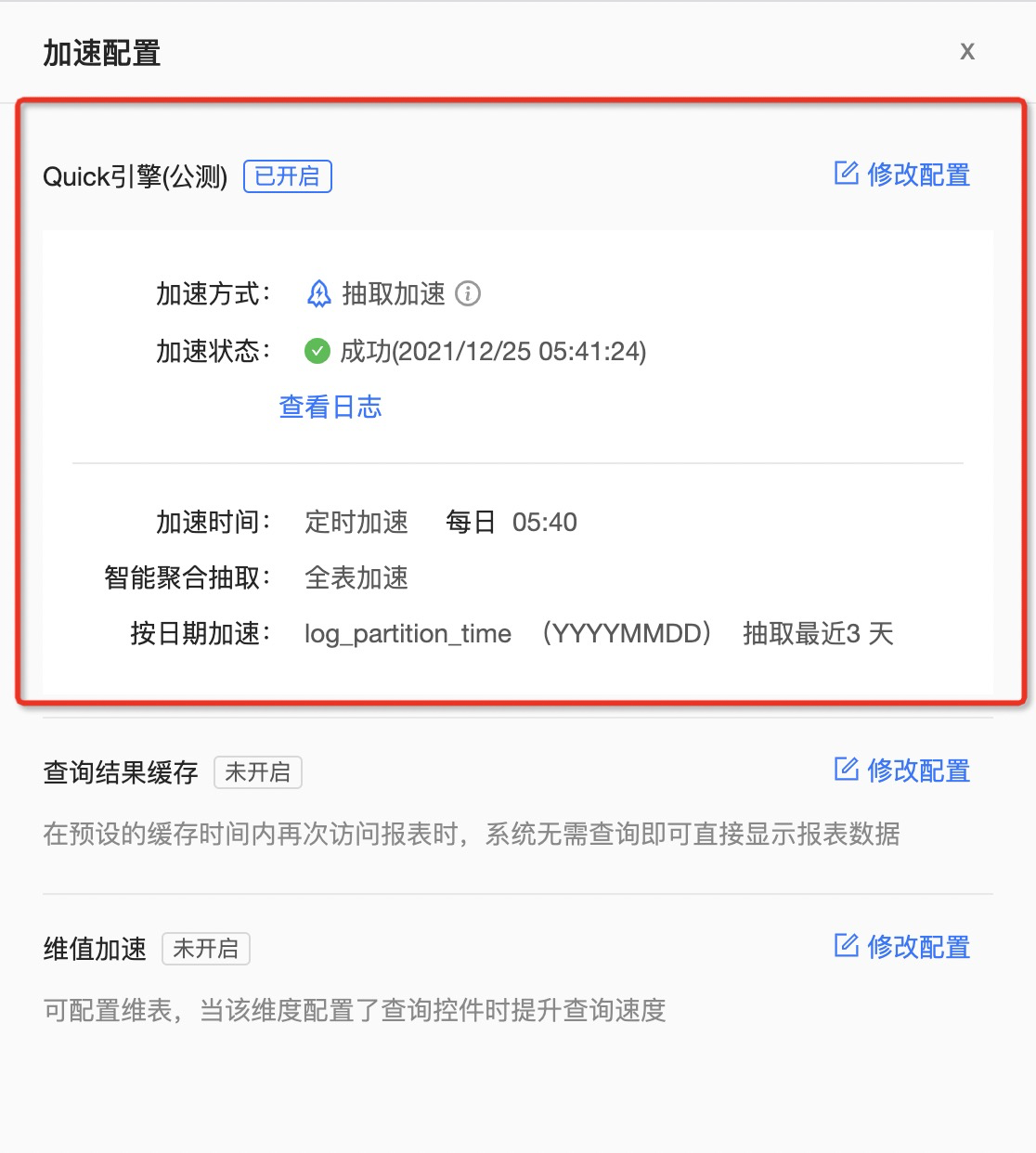
(3)用户数据源查询慢,但对数据实时性有要求
有的用户,数仓里的数据每天都在实时变化。以仓储管理为例,仓库里每天货物的进出是动态的,这些数据会实时落到数据库里,而客户希望能够通过 Quick BI 的报表,对这些动态数据进行分析。显然,上面提到的缓存方案以及抽取加速都无法达成这个目的。
对于这类用户来说,他们可以在数据集的 Quick 引擎里开启实时加速, 通过引擎内置的 MPP 内存计算引擎,对数据进行实时的内存计算,从而达到加速的目的。
开启了 Quick 引擎的实时加速,可以做到亿级数据,秒级响应。
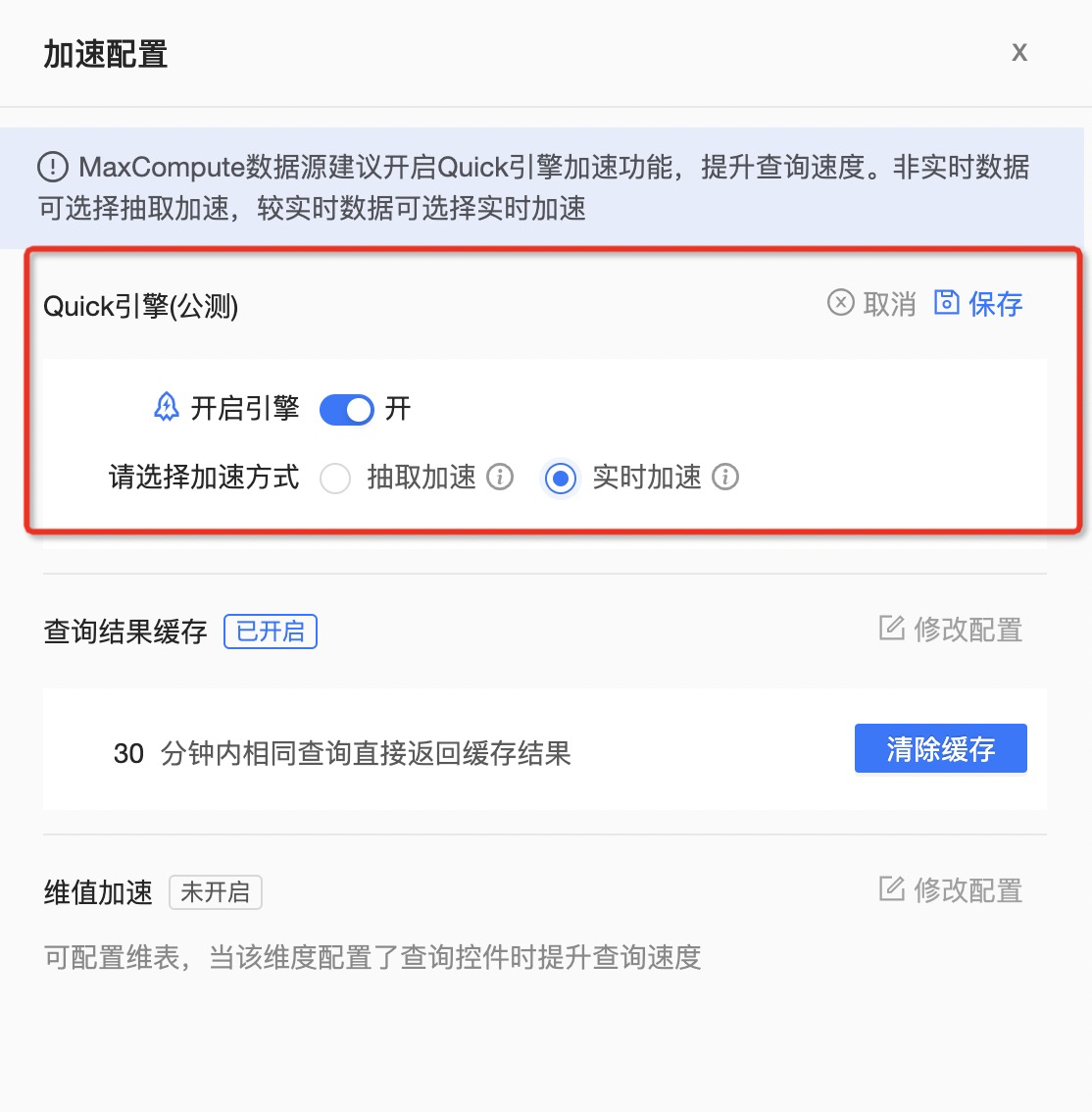
(4)用户查询依赖维度值的获取
企业如果需要以产品类目为维度,对销售记录进行分析。这个时候,就会用到 Quick BI 的查询控件,以下拉列表的方式对“类目”这个维度的值进行展示和选择。
以服装公司为例,共有100 个产品类目,销售记录上千万条。这个时候从完整的销售记录里获取类目值,效率太低。可以使用 Quick BI 提供的维值加速方案, 将类目的维度表配置进维值加速功能,此时100 个类目仅对应 100 行数据,而不再是原来的上千万条。
再获取类目下拉列表时,就会直接从维度表中读取,大大提升下拉列表里维度值的获取效率。

![]()
2、Quick BI阅览者视角的加速效果
(1)即席分析表格
500W单元格,秒级渲染完毕(60 FPS),操作流畅:

![]()
(2)报表首屏打开
基于双引擎,在1亿行数据,20个图表组件,常规聚合类查询下进行标准测试,一个标准复杂报表可在2秒内展现:

本文为阿里云原创内容,未经允许不得转载。