简介: 编者按:近几年国产数据库市场风生水起,涌现了多款优秀的国产数据库产品,本文选取了三款典型的国产分布式数据库进行全方位对比压测,呈现了国产分布式数据库的发展现状。
对于所有的应用系统,数据都是承载业务逻辑的核心资产,而存储数据的数据库系统则是最核心的系统之一。随着国产化进程的不断推进,应用系统基于国产化数据库进行构建越来越重要,也越来越成为数据库选型中的主流。
近几年国产数据库市场风生水起,涌现了多款优秀的国产数据库产品,各大厂商也在重金投入数据库研发中。本文选取了三款典型的国产分布式数据库进行全方位对比压测,分析国产分布式数据库的发展现状,供各位读者参考。
测试环境及数据库架构
PolarDB-X

![]()
数据库架构:

Oceanbase


TiDB


压测指标分析
Sysbench压测情况:
1. 压测参数配置
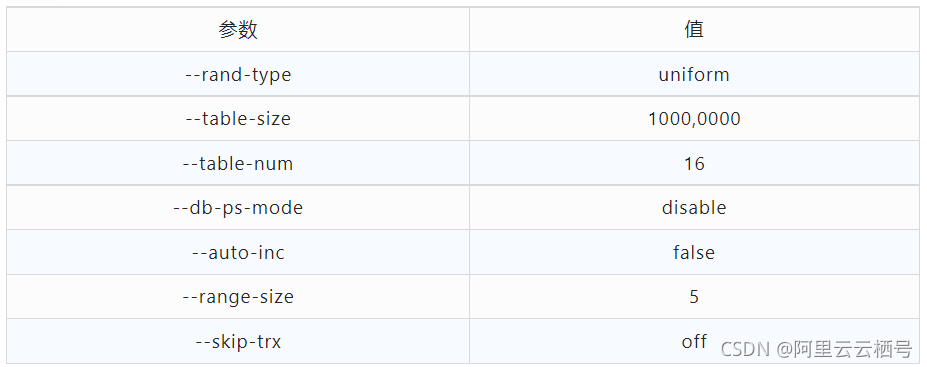
![]()
测试表结构: CREATE TABLE `sbtest1` ( `id` int(11) NOT NULL, `k` int(11) NOT NULL DEFAULT '0', `c` char(120) NOT NULL DEFAULT '', `pad` char(60) NOT NULL DEFAULT'', PRIMARY KEY (`id`), KEY `k_1` (`k`) ) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4
2. 场景说明
- 总计16 张表,每张表 1000 万行数据,数据分布uniform。
- tidb场景:基于range水平拆分模式的分布式(tidb默认会把所有表的数据按照range做自动均衡,某一张测试表的数据会均匀分布到多个机器上)。
- OB模式:单表即官网默认推荐模式,sysbench脚本不作修改时自动建立的表,这里简称非分区表;基于hash水平拆分模式的分布式,简称分区表。
- PolarDB-X场景:单表,sysbench脚本不作修改时自动建立的表,这里简称非分区表;基于hash水平拆分模式的分布式,简称分区表,索引采用本地索引;基于hash水平拆分模式的分布式,简称分区表,索引采用GSI全局索引。
3. 测试结果数据

TPCC (5000仓)
TPCC是专门针对联机交易处理系统(OLTP系统)的测试规范,一般情况下我们也把这类系统称为在线业务处理系统。1992年7月发布,几乎所有在OLTP市场提供软硬平台的国外主流厂商都发布了相应的TPC-C测试结果,随着计算机技术的不断发展,这些测试结果也在不断刷新。
TPCC通常用于模拟测试复杂的在线事务处理系统,在大压力情况测试数据库的事务处理能力,以下压测汇总了三种分布式数据库的最大tpmC指标:
// 数据导入 5000仓 tiup bench tpcc --warehouses 5000 -D tpcc -H xxx -P xxx -T threads_num prepare // 运行 tiup bench tpcc run -U root --db tpcc2 --host xxx --port xxx --time xxx --warehouses 5000 --threads

TPCH(商业智能计算测试)是美国交易处理效能委员会(TPC,TransactionProcessing Performance Council) 组织制定的用来模拟决策支持类应用的一个测试集。目前,在学术界和工业界普遍采用它来评价决策支持技术方面应用的性能。
这种商业测试可以全方位评测系统的整体商业计算综合能力,对厂商的要求更高,同时也具有普遍的商业实用意义,目前在银行信贷分析和信用卡分析、电信运营分析、税收分析、烟草行业决策分析中都有广泛的应用,以下以TPCH-100G来对比分析三种分布式数据库的分析能力:
// 导入数据 100G tiup bench tpch prepare --host xxx --port xxx --db tpch_100 --sf 100 --analyze --threads xxx // run tiup bench tpch run --host xxx --port xxx --db tpch_100 --sf 100 --check=true

DDL 能力
1. 场景说明
测试数据为tpch100g 生成的lineitem表,单表6亿行数据

并行DDL用于测试在达标的DDL过冲中,在前一个DDL未完成时,在同一张lineitem表下面加列、相同库下创建一张表、给小表(如nation表)建立索引,观察第二步是否能够立即返回,若能立即返回,则表明支持并行DDL。

热点行更新
对于有限的数据库资源,如果有大量请求去消费的话,肯定会产生大量的锁竞争(数据库对一条数据的更新会导致在索引上给这条记录加锁),消耗服务器资源,而且请求的成功率也不高(换句话说就是你在浪费服务器资源,性价比不高);热点行更新用来测试数据库锁控制能力和高并发大压力下事务情况。

读写分离
场景介绍:一致性读用于在只读节点读取数据的时候,是否可用控制读的数据一致,包括强一致读和弱一致读;并且只读节点延迟控制用于控制业务在读取过程中,备库最大支持多长时间的延迟。

分区变更特性
场景介绍:分区规则变更用于验证数据库的分布式调整能力,分区策略调整可以灵活适配线上表的业务场景,尤其从单表到分区表(分布式表),或者从单表到广播表的场景。

特殊场景
1. 大事务
测试数据为tpch100g 生成的lineitem表,单表6亿行数据 select * from lineitem; update lineitem set L_PARTKEY=L_PARTKEY+1;
测试结果:


单机表数量用于测试在复杂业务场景下,单机上可以存储的最大表(分区)的数量情况,验证数据库的元数据管理能力,并且考察在单机支持更多表的情况下可以降低分布式的存储成本。

TiDB、OceanBase、PolarDB-X均可以平滑删除,对在线业务无影响。
5. 应急限流
场景介绍:应急限流用于在线上紧急情况下,对部分烂SQL或者问题SQL进行紧急限流,保证大多数业务正常的情况下,限制部分烂SQL的运行,可用于紧急线上恢复。

场景介绍:用户验证是否支持oltp和olap场景自动资源隔离,olap通常需要大量的数据查询分析资源,如果无法资源隔离有可能影响在线业务的使用和稳定性。

场景介绍:用于测试执行计划绑定能力

测试结果分析
TiDB:
1. 开启了实验室特性(plan cache),不建议生产直接使用。生产环境默认不开启的话,point_select性能会有60%左右的性能下降,100核左右的资源点查场景只有36万QPS
2. sysbench测试场景中,会有比较大量的where id between xx and xx,但在实际业务中单纯基于用户id或者交易id的范围查询意义并不大,更多是在时间范围的查询。TiDB基于Range的分区策略,在between的分区裁剪可以做到只访问1个数据分片,而PolarDB-X和OceanBase基于Hash的策略会访问5个数据分片,因此TiDB的数据结构会在sysbench单纯指标能力上占一定的优势。ps. 针对Range 和 Hash分区的性能差异,在PolarDB-X上基于read only场景下跑了下Range分区的对比测试,Range相比于Hash分区差不多有45%左右的性能提升(28万 vs 19万)
3. TPC-C场景下,整体劣势比较明显
4. TPC-H场景下,在tilfash模式下性能表现不错,但在普通的tikv模式下,部分SQL跑不出结果
5. 特殊场景下,加索引的DDL性能有待提升,支持json但不建议生产使用,以及在热点行更新下有明显瓶颈
OceanBase:
1. 非分区表(通常理解的单表),在OceanBase内部会在分布式多个节点上做表级别的均衡,一张表的数据只在一个节点,不同表可以在不同的节点,在非分区表下比较考验纯单机的能力。针对sysbench场景下的多张表在测试过程中是完全独立的,这样可以充分利用"多个单机"跑出一个更好的总吞吐值。这样的模式下,相比于TiDB会有30%~70%的优势,多个独立的单表模式在真实业务场景中一般需要配合业务端的分库分表。
2. 分区表,在OceanBase内部支持将一张表的数据分布到多台机器上,实现行级别的水平扩展能力,在分区表下会存在分布式事务、分片聚合查询等额外代价,是最考验分布式能力的地方。分区表和 非分区表在sysbench的性能测试结果上,两者的性能差异巨大。尤其在写入和混合读写场景,分区表只有单表测试的1/5左右,分布式事务的性能还需要有进一步的提升空间。
3. TPC-C场景下表现优秀。在TPC-H场景下,通过并行计算+行存整体表现不错。
4. 特殊场景下,不支持json,以及在热点行更新下有明显瓶颈。
PolarDB-X:
1. 非分区表(通常理解的单表),PolarDB-X上支持通过locality模式将表分配到不同的节点,一张表的数据只在一个节点上,比较考验纯单机的能力。针对纯读和混合读写场景,相比于TiDB会有2~2.5倍的性能优势。
2. 分区表,在PolarDB-X内部支持将一张表的数据分布到多台机器上,实现方式和TiDB、OceanBase分布式表基本一致,在write only上整体性能会比TiDB好一些;在最常见的业务场景read write下,分区表和单机表性能都比OB要好很多,非分区表比TIDB有明显的性能优势,分区表跟tidb基本保持一致
3. TPC-C场景下表现优秀。在TPC-H场景下,通过并行计算+行存整体表现不错
4. 特殊场景下,快速加列DDL需要优化,支持json,以及针对热点更新的优化明显。
polardb-x对分区规则变更支持最好,基本支持所有常见的分区变更策略
总结
1. PolarDB-X/OceanBase/TiDB在分布式水平扩展的性能上大同小异,区分度并不大。
2. TiDB有一些不错的实验性质的功能(比如plan cache、json),对性能和功能易用性帮助比较大,但眼下生产不推荐使用。
3. OceanBase的模型比较复杂,测试场景需要充分理解分区表和 非分区表(单表)。在非分区表(单表)模式下,性能表现不错,重点考察的是纯单机能力,性能尚可,略低于MySQL。但分区表模式下,性能下降比较多,需要业务区分来看。
4. PolarDB-X功能性和易用性比较不错,json、大事务、热点更新支持比较完整。在非分区表(单表)模式下,纯MySQL单机的能力表现突出,在分区表模式下,可以通过分布式能力进一步扩展性能,对分区表的变更策略支持最完善。(完)
原文链接
本文为阿里云原创内容,未经允许不得转载。