作为一个整天以代码为伴的码农,避免不了会接触到各种代码提示工具,但是呢,用久了之后会发现他们都有个共同点,那就是 模型巨大,动辄几百兆;并且模型大必然需要更多的计算,同样会导致电脑内存占用高,风扇呼呼的转,时间久了逐渐会发现电脑存储不够用了,电脑变卡了等等问题。
那么,有没有一款轻量化的代码提示插件?或者说,如何实现一款轻量化的代码提示插件呢?
下面我会从 模型选择、模型实现、模型优化三个方面 来介绍我们在代码智能提示方面的一些实践。
模型选择
如何衡量一个模型的效果是好还是不好呢?
我们首先建立了基本的模型衡量体系,见下图。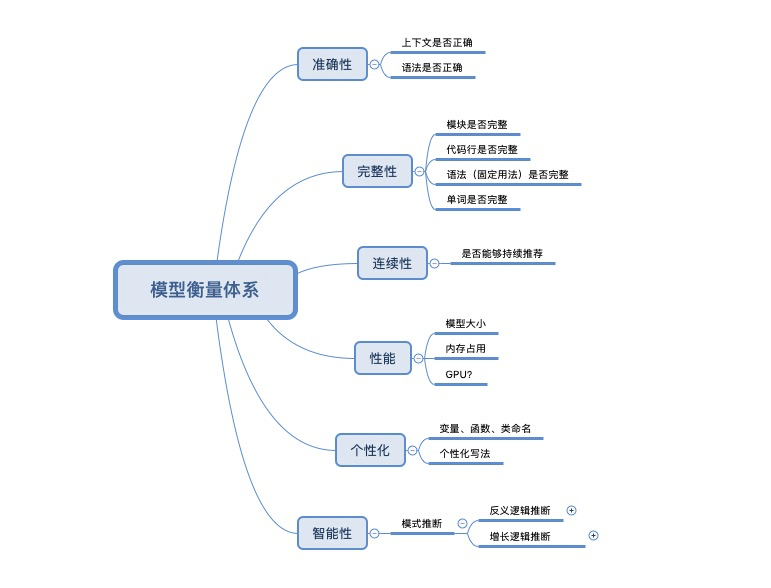
我们会从推荐的准确性、完整性、连续性、性能、个性化以及智能性六个维度去综合评价一个模型的优劣。之后,我们会进一步完善这个体系,使之能够系统完整的评测模型的效果。
实践中,我们选取了 GPT-2模型和基于markov的n-gram统计模型进行对比。
对比发现,GPT-2模型在准确性和完整性方面表现优异,但是在性能方面,由于模型较大,推荐一次耗时较久,(这里我们试了最少参数的版本,训练之后模型在500M左右,推荐一次大概需要10S ),由于暂时没找到模型压缩的方法,只能暂时放弃。
另一个n-gram模型,在测试后发现,它在持续推荐和性能 方面表现优异,模型大小仅有40M,但也并非完美,在准确性和完整性方面表现的不是很好。
在实践中,我们发现,推荐耗时在毫秒级别能够使用户顺畅无阻碍的编写下去,多于1s,则会让用户的输入产生停顿。 基于此我们暂时选取n-gram作为我们的推荐模型。
模型实现
下面介绍一下n-gram模型的基本原理以及我们的实现。
首先,n-gram模型基于马尔可夫链的假设,即:当前这个词出现的概率仅仅跟前面几个有限的词相关。 以最简单的n=2为例,即 下一个词出现的概率仅跟之前一个词相关,基于这个思想,我们将大量代码进行切分,这样我们得到了很多的二元组,这里可以使用单词的出现次数代表概率。这样,我们根据一个词就可以得到一个不同概率分布的推荐列表,然后每次都以当前词进行推荐,就可以产生持续不断的推荐了。切分的效果参考这张图
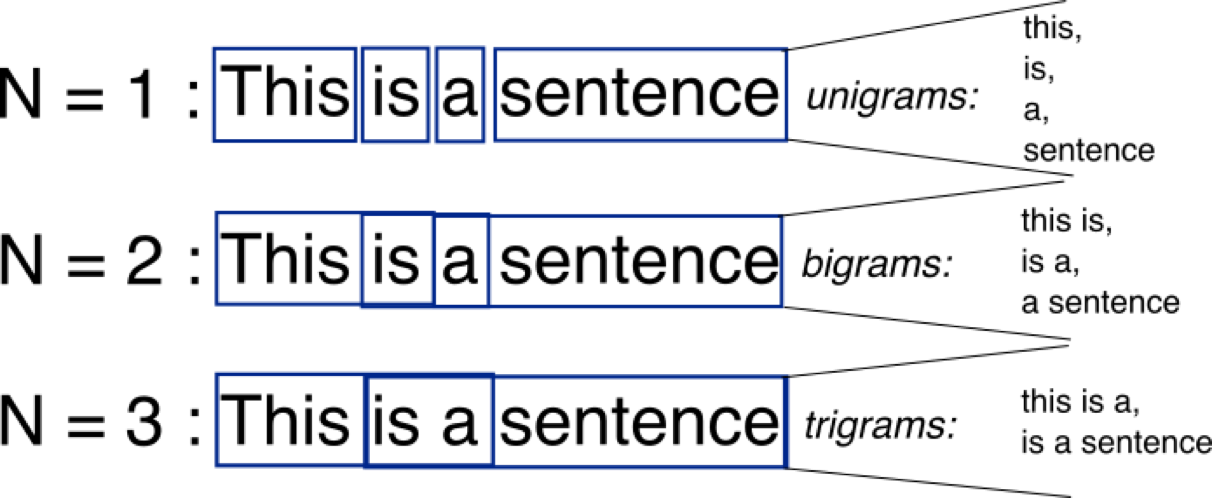
以下是模型训练和产生推荐的大致流程。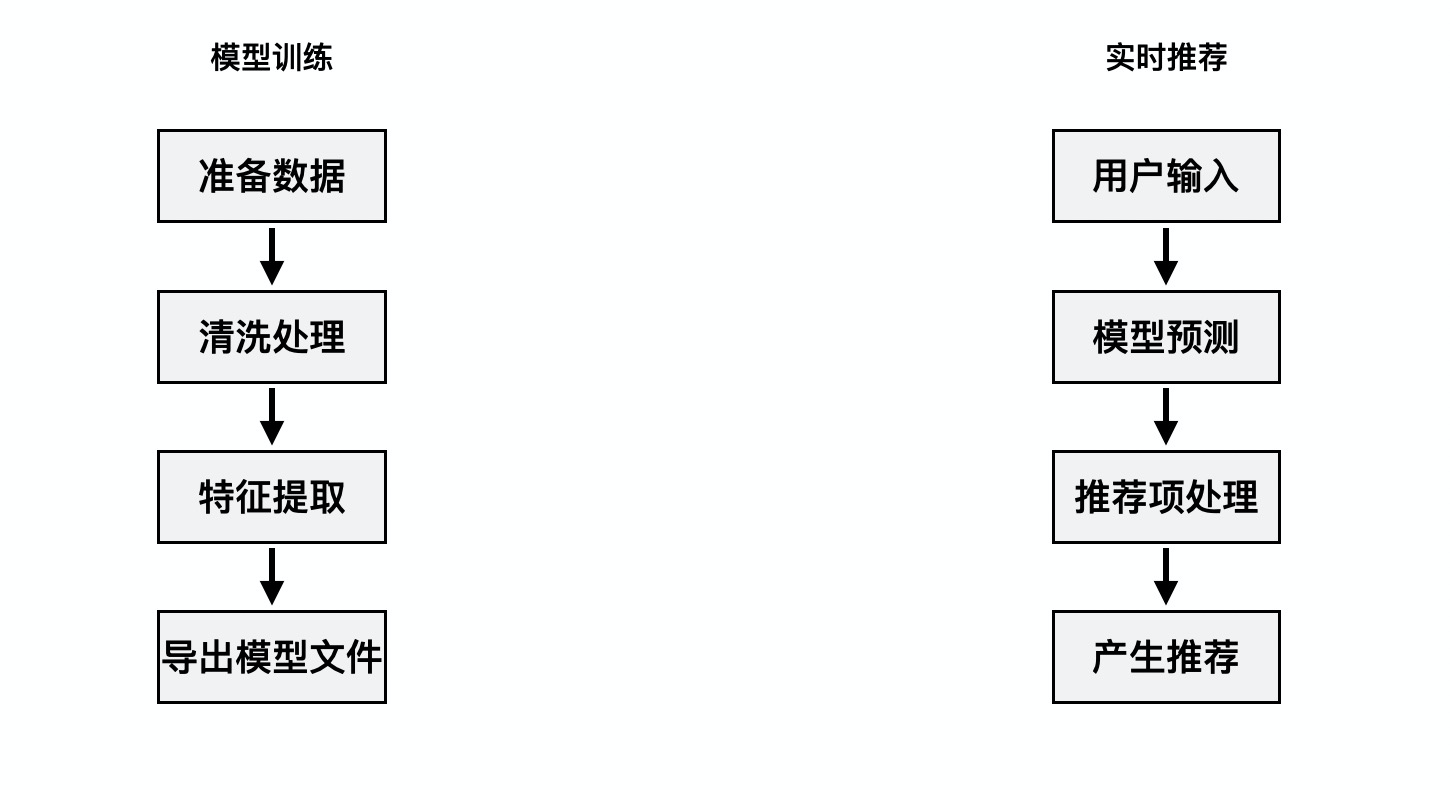
模型优化
在真实应用中,仅仅有这些是远远不够的。模型只是其中一部分,更多的应该是在应用过程中,依据实践经验和用户的反馈,对模型进行不断调优:
- 比如,在实际应用中,基于同一个上下文,我们一般会同时产生基于n=3,n=4等等不通粒度的推荐,我们会给不通粒度赋予不同的权重,然后结合概率进行筛选和排序,并且根据实际效果以及我们的反馈体系,对权重进行断优化,确保产生最佳效果的推荐。
- 另外,为了让推荐更加个性化,我们的模型需要具备实时训练的能力,即用户的输入在产生推荐的同时,还要参与模型的增量训练,并根据用户实际的选择对模型进行调优,确保模型的准确性和个性化,大致流程图如下

- 还有,为了得到更加轻量的模型,我们对语料库也进行了精简,比如,在初始模型中,我们对出现概率极低的语料进行了删减,保持模型的轻巧和高效,同时由于具备实时训练的能力,确保这个操作不会影响到推荐的准确率。
结语
当然,目前的这些对于一个轻巧好用的代码提示来说是远远不够的,当前我们正在尝试完善模型的衡量体系 ,并且在尝试更多轻量的语言模型,希望给用户提供完美的体验。
原文链接
本文为阿里云原创内容,未经允许不得转载。