现在网络上充斥着大量关于神经网络的消息,但是,什么是神经网络?其本质到底是什么?你是不是对这个熟悉又陌生的词感到困惑?
用几分钟阅读完这篇文章,我不能保证你能够成为这个领域的专家,但可以保证的是,你已经入门了。
什么是神经网络?
想要透彻的了解神经网络,我们首先要知道什么是机器学习。为了更好的理解机器学习,我们首先谈谈人的学习,或者说什么是“经典程序设计”。
在经典的程序设计中,作为一名开发人员,我需要了解所要解决的问题的各个方面,以及我要以什么规则为基础。
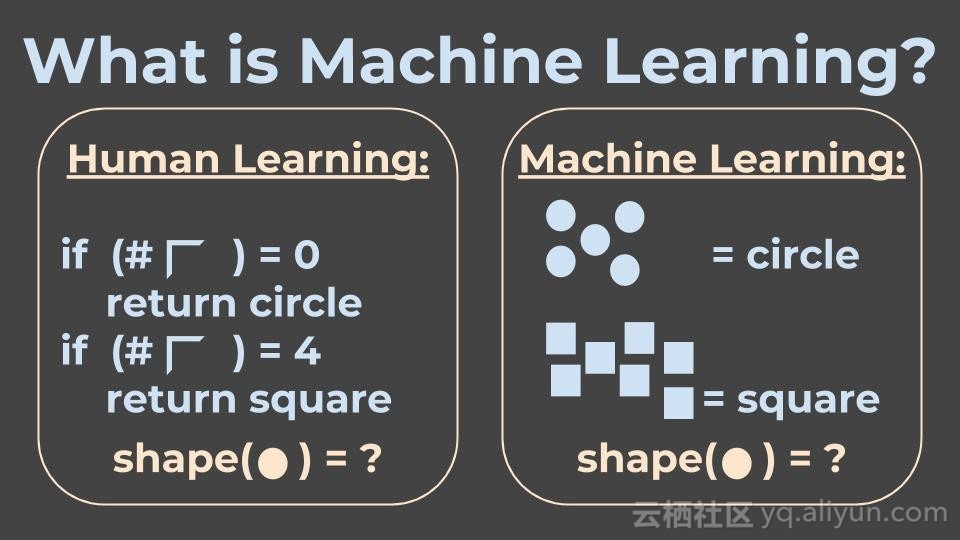
举个例子来说,假设我要设计一个能够区别正方形和圆形的程序。处理方法则是编写一个可以检测到角的程序,然后计算角的数量。如果程序能检测到4个角,那么图形为正方形;如果角的个人为0,则为圆形。
那么这个机器学习有何关系?一般来说,机器学习=从示例中学习。
在机器学习中,该如何区别正方形和圆形呢?这时候,我们就要设计一个学习系统,将许多形状及类别不同的图形作为输入,然后我们希望机器能够自己学习形状及类别,然后识别出不同图形的不同特性。
一旦机器学会了这些属性,我们就可以输入一个新的图形(机器以前没见过的图形),然后机器对这些图形进行分类。
什么是神经网络?
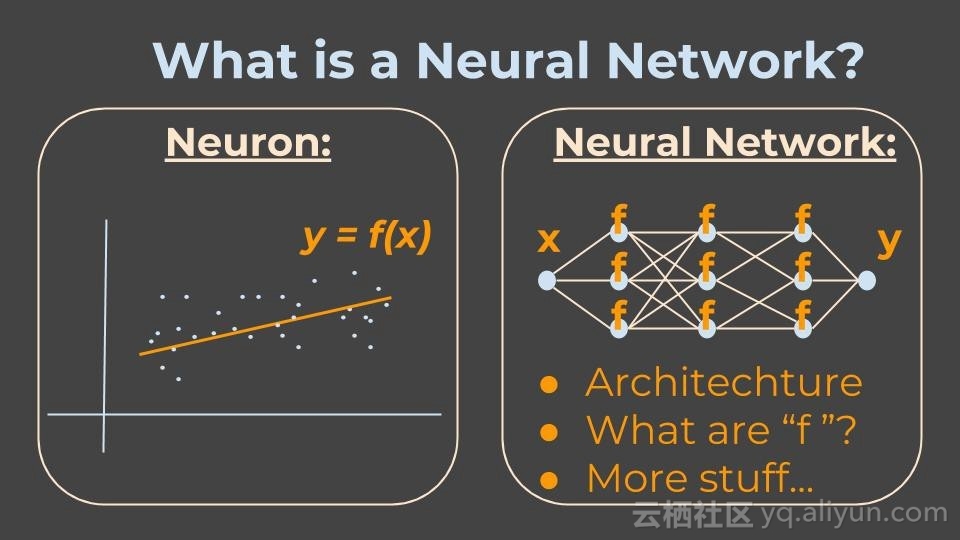
在神经网络中,神经元是一个很奇特的名字,比较类似于函数。在数学和计算机领域,函数可以接受某个输入,经过一系列的逻辑运算,输出结果。
更重要的是,我们可以将神经元看做一个学习单元。
因此,我们需要理解什么是学习单元,然后再了解神经网络的基本构建块,即神经元。
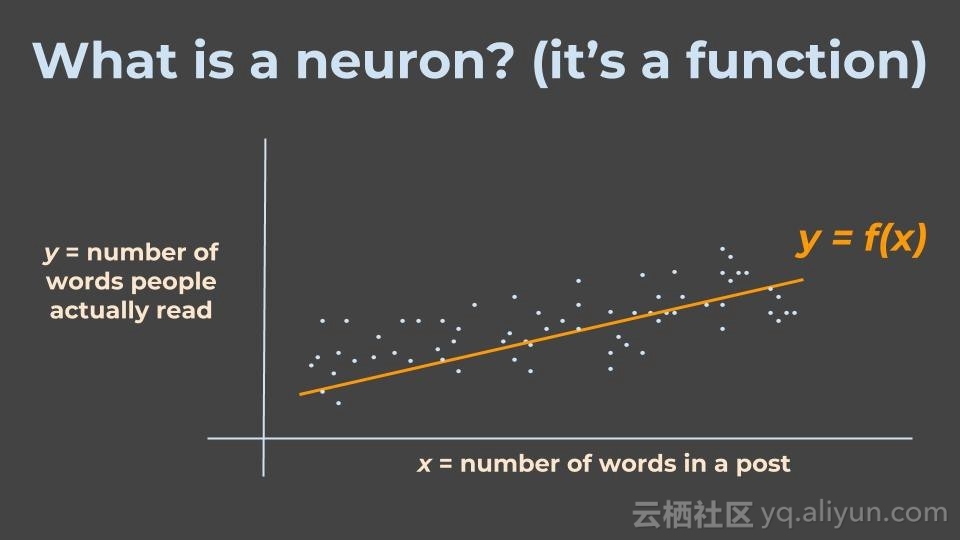
为了更好的理解,假设我们试图理解博客文章中单词数量与人们实际从博客中读取单词数量之间的关系。请记住一点,在机器学习领域,我们从示例中学习。
因此,我们用x表示机器收集到文章的单词数量,用y表示人们实际读到的单词数,它们之间的关系用f表示。
然后,我只需要告诉机器(程序)我希望看到的关系(比如直线关系),机器再将会理解它所需要绘制的线。
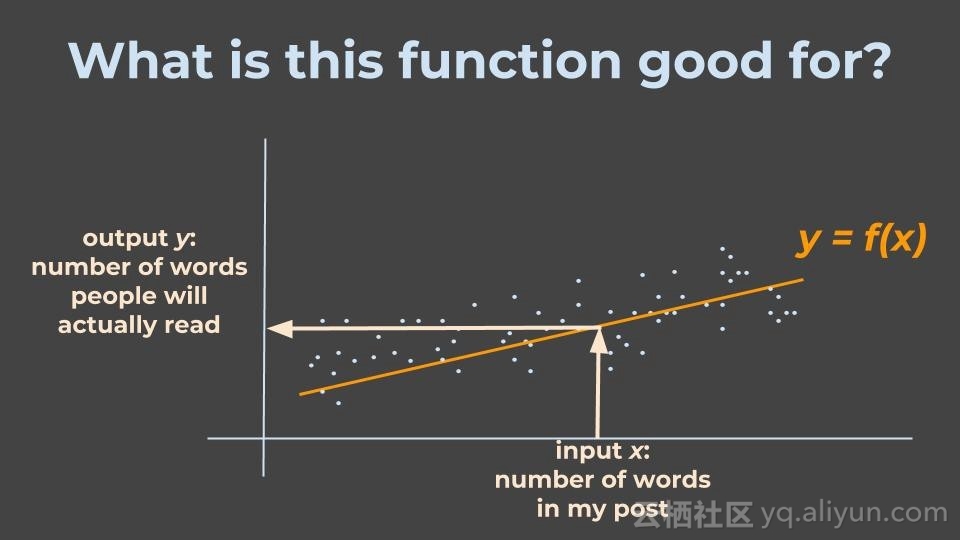
我在这里得到了什么?
下次我想写一篇包含x个单词的文章时,机器可以根据对应关系f找到人们真正能阅读到的单词数y。
那么,神经网络到底是什么?如果一个神经元是一个函数,那么神经网络就是一个函数网络,也就是说,我们有很多个这样的功能(比如学习单元),这些学习单元的输入和输出相互交织,相互之间也有反馈。
作为一名神经网络的设计人员,我的主要工作就是:
1.如何建模输入和输出?例如,如果输入是文本,我可以用什么建模?数字?还是向量?
2.每个神经元有哪些功能?(它们是线性?还是指数?...)
3.神经网络的架构是什么?(即哪个函数的输出是哪个函数的输入?)
4.我可以用哪些通俗易懂的词来描述我的网络?
一旦我回答了以上这些问题,我就可以向网络“展示”大量具有正确输入和输出的例子,神经网络学习后,当我再次输入一个新的输入时,神经网路就会有个正确的输出。
神经网络的学习是件永无止境时,这个领域的知识呈爆炸性增长,每时每刻都会有新的知识和内容更新。
原文链接
本文为云栖社区原创内容,未经允许不得转载。