上一篇我们讨论了,SQL Server 2005 分页 的两种情况,在取不同分页时,花的时间很大,如果我们真的取后面几页,如果有几千倍的ioa差异,
假如客户是自己输入页数,那他要等多长时间才能打开,有没有好的办法优化速度。
我们先把先前的sql语句做一个修改:
 select * from (select id, row_number() over (order by id) scn from [dbo].[[[zping.com]]]]] ) t where scn<100000 and scn>100000-20
select * from (select id, row_number() over (order by id) scn from [dbo].[[[zping.com]]]]] ) t where scn<100000 and scn>100000-20这里我们看到只是把select *,row_number() over (order by id)修改成了
select id, row_number() over (order by id)
执行一下看看效率:
(19 行受影响) 表 '[[zping.com]]'。扫描计数 1,逻辑读取 740 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。这时我们发现和上次很大差距,上一次是10万IO,这次是740个,为何,看看执行计划
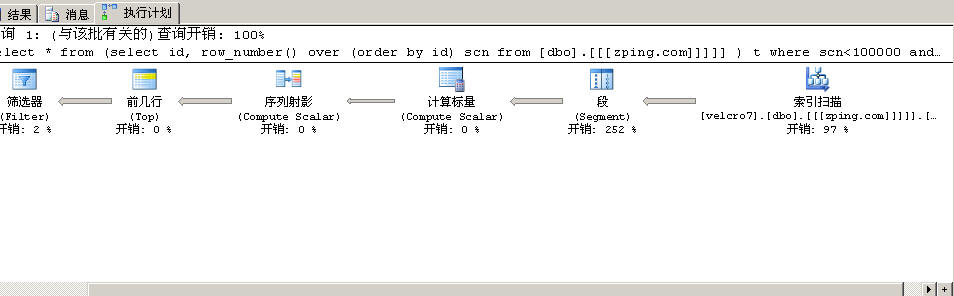
这时发现,数据库并没有去扫描表数据,而是直接去扫描索引。效率很高 ,但有个缺点就是不能读出需要的数据 。
那对于上次分页的10万IO,我们怎么优化啊,如果数据有1000万,那时间是很长的。这时我们可以利用这个索引扫描来
优化该分页:
修改了一下10万行的分页的sql语句:
 select * from [dbo].[[[zping.com]]]]] where id in ( select id from (select id, row_number() over (order by id) scn from [dbo].[[[zping.com]]]]] ) t where scn<100000 and scn>100000-20)
select * from [dbo].[[[zping.com]]]]] where id in ( select id from (select id, row_number() over (order by id) scn from [dbo].[[[zping.com]]]]] ) t where scn<100000 and scn>100000-20)
这时候运行一下sql语句
(19 行受影响) 表 '[[zping.com]]'。扫描计数 1,逻辑读取 816 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。这时你发现读出的数据都有了,逻辑IO次数有10万次变成816次,io数大大降低。时间也大大提高。
注意:
我们现在讨论时单个表的数据分页,而且是索引覆盖情况下,当复杂多表关联查询分页,效率不高,有很大局限性。
前两次讨论了SQL server 2005分页效率和方法。在sql server 2000的分页是采用什么方法啊,对比一下两者的差别和性能
SQL server 2000的分页方法,
其常用分页sql代码如下:
SELECT TOP 19 * FROM [dbo].[[[zping.com]]]]] WHERE (ID NOT IN (SELECT TOP (10*(10000-1)) ID FROM [dbo].[[[zping.com]]]]] ORDER BY ID DESC)) ORDER BY ID DESC
这里的第10万页是分页的页数。在取10万页的分页看看执行效率:
19 行受影响) 表 '[[zping.com]]'。扫描计数 2,逻辑读取 101723 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。发现和上次去的第10万行分页逻辑读是一样的。而且扫描表有2次,说明和上一个分页效率一样,越到最后页效率很低。
我个人认为:
网上说这个方法在sql server 2000可以“实现高性能千万量的数据分页”,这不一定对,在前几页效率是很高的,越到最后分页效率是很低的,SQL server 2005在中分页的确做了很大提升。在使用时大家要注意到这一点:“并不是取所有分页数据都很快”
前几次,讨论了sql server 2005的分页和优化,后面谈到目前常用的分页方法在读取后面分页是会越来越慢。后面给了一个高效的分页方法
,但是想一下,对单个表并且在索引覆盖情况下是很高效的,但实际业务逻辑很复杂,取的数据可能来自多个表,这样的方法是不好的。
那到底是用哪个分页方法啊,这两天看了一下,淘宝网 (http://www.taobao.com/) 和 易趣网 (http://www.eachnet.com/)这两的海量数据库分页方法,
目前淘宝是用的Oracle数据库,易趣网不太清楚是哪个数据库,不管是那个数据库,查询原理一样,在分页时都会遇到这样问题。
在淘宝网,输入“1”查宝贝的数据,就发现有4,395,524个结果,看看下面的分页,最多让你分100页,也就是说,淘宝最多看到100页数据,其后面的数据是不让你看的。为何,个人认为:
1,可能就是分页效率低下,为保证网站的高性能,后面数据不让查询,
2,也可能是业务上认为没必要提供100页以后的数据,客户不会关心了。
分页的问题,淘宝网的陈吉平在《Oracle数据库性能优化》一书中,就有提到分页效率和对策。
同样在 易趣网,输入“1”,查物品,有334页个分页数据。一共有10020个物品,如果你在输入500页的数据,系统提示出错。后面数据不让查询的。
既然大型的门户网站都这样,我们在做Web分页时,可以考虑这样的手段,
采用通用的分页方法时,这时对分页页码做个一个限制。(如最多显示500页等)
摘录自http://www.cnblogs.com/zping/archive/2008/07/21/1247718.html