神经网络的逻辑应该都是熟知的了,在这里想说明一下交叉验证
交叉验证方法:
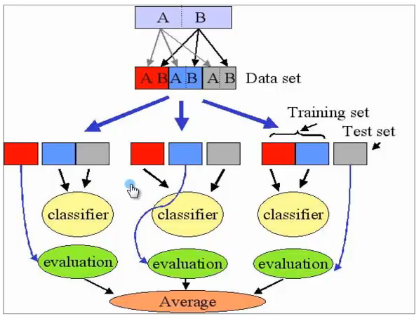
看图大概就能理解了,大致就是先将数据集分成K份,对这K份中每一份都取不一样的比例数据进行训练和测试。得出K个误差,将这K个误差平均得到最终误差
这第一个部分是BP神经网络的建立
参数选取参照论文:基于数据挖掘技术的股价指数分析与预测研究_胡林林
import math import random import tushare as ts import pandas as pd random.seed(0) def getData(id,start,end): df = ts.get_hist_data(id,start,end) DATA=pd.DataFrame(columns=['rate1', 'rate2','rate3','pos1','pos2','pos3','amt1','amt2','amt3','MA20','MA5','r']) P1 = pd.DataFrame(columns=['high','low','close','open','volume']) DATA2=pd.DataFrame(columns=['R']) DATA['MA20']=df['ma20'] DATA['MA5']=df['ma5'] P=df['close'] P1['high']=df['high'] P1['low']=df['low'] P1['close']=df['close'] P1['open']=df['open'] P1['volume']=df['volume'] DATA['rate1']=(P1['close'].shift(1)-P1['open'].shift(1))/P1['open'].shift(1) DATA['rate2']=(P1['close'].shift(2)-P1['open'].shift(2))/P1['open'].shift(2) DATA['rate3']=(P1['close'].shift(3)-P1['open'].shift(3))/P1['open'].shift(3) DATA['pos1']=(P1['close'].shift(1)-P1['low'].shift(1))/(P1['high'].shift(1)-P1['low'].shift(1)) DATA['pos2']=(P1['close'].shift(2)-P1['low'].shift(2))/(P1['high'].shift(2)-P1['low'].shift(2)) DATA['pos3']=(P1['close'].shift(3)-P1['low'].shift(3))/(P1['high'].shift(3)-P1['low'].shift(3)) DATA['amt1']=P1['volume'].shift(1)/((P1['volume'].shift(1)+P1['volume'].shift(2)+P1['volume'].shift(3))/3) DATA['amt2']=P1['volume'].shift(2)/((P1['volume'].shift(2)+P1['volume'].shift(3)+P1['volume'].shift(4))/3) DATA['amt3']=P1['volume'].shift(3)/((P1['volume'].shift(3)+P1['volume'].shift(4)+P1['volume'].shift(5))/3) templist=(P-P.shift(1))/P.shift(1) tempDATA = [] for indextemp in templist: tempDATA.append(1/(1+math.exp(-indextemp*100))) DATA['r'] = tempDATA DATA=DATA.dropna(axis=0) DATA2['R']=DATA['r'] del DATA['r'] DATA=DATA.T DATA2=DATA2.T DATAlist=DATA.to_dict("list") result = [] for key in DATAlist: result.append(DATAlist[key]) DATAlist2=DATA2.to_dict("list") result2 = [] for key in DATAlist2: result2.append(DATAlist2[key]) return result def getDataR(id,start,end): df = ts.get_hist_data(id,start,end) DATA=pd.DataFrame(columns=['rate1', 'rate2','rate3','pos1','pos2','pos3','amt1','amt2','amt3','MA20','MA5','r']) P1 = pd.DataFrame(columns=['high','low','close','open','volume']) DATA2=pd.DataFrame(columns=['R']) DATA['MA20']=df['ma20'].shift(1) DATA['MA5']=df['ma5'].shift(1) P=df['close'] P1['high']=df['high'] P1['low']=df['low'] P1['close']=df['close'] P1['open']=df['open'] P1['volume']=df['volume'] DATA['rate1']=(P1['close'].shift(1)-P1['open'].shift(1))/P1['open'].shift(1) DATA['rate2']=(P1['close'].shift(2)-P1['open'].shift(2))/P1['open'].shift(2) DATA['rate3']=(P1['close'].shift(3)-P1['open'].shift(3))/P1['open'].shift(3) DATA['pos1']=(P1['close'].shift(1)-P1['low'].shift(1))/(P1['high'].shift(1)-P1['low'].shift(1)) DATA['pos2']=(P1['close'].shift(2)-P1['low'].shift(2))/(P1['high'].shift(2)-P1['low'].shift(2)) DATA['pos3']=(P1['close'].shift(3)-P1['low'].shift(3))/(P1['high'].shift(3)-P1['low'].shift(3)) DATA['amt1']=P1['volume'].shift(1)/((P1['volume'].shift(1)+P1['volume'].shift(2)+P1['volume'].shift(3))/3) DATA['amt2']=P1['volume'].shift(2)/((P1['volume'].shift(2)+P1['volume'].shift(3)+P1['volume'].shift(4))/3) DATA['amt3']=P1['volume'].shift(3)/((P1['volume'].shift(3)+P1['volume'].shift(4)+P1['volume'].shift(5))/3) templist=(P-P.shift(1))/P.shift(1) tempDATA = [] for indextemp in templist: tempDATA.append(1/(1+math.exp(-indextemp*100))) DATA['r'] = tempDATA DATA=DATA.dropna(axis=0) DATA2['R']=DATA['r'] del DATA['r'] DATA=DATA.T DATA2=DATA2.T DATAlist=DATA.to_dict("list") result = [] for key in DATAlist: result.append(DATAlist[key]) DATAlist2=DATA2.to_dict("list") result2 = [] for key in DATAlist2: result2.append(DATAlist2[key]) return result2 def rand(a, b): return (b - a) * random.random() + a def make_matrix(m, n, fill=0.0): mat = [] for i in range(m): mat.append([fill] * n) return mat def sigmoid(x): return 1.0 / (1.0 + math.exp(-x)) def sigmod_derivate(x): return x * (1 - x) class BPNeuralNetwork: def __init__(self): self.input_n = 0 self.hidden_n = 0 self.output_n = 0 self.input_cells = [] self.hidden_cells = [] self.output_cells = [] self.input_weights = [] self.output_weights = [] self.input_correction = [] self.output_correction = [] def setup(self, ni, nh, no): self.input_n = ni + 1 self.hidden_n = nh self.output_n = no # init cells self.input_cells = [1.0] * self.input_n self.hidden_cells = [1.0] * self.hidden_n self.output_cells = [1.0] * self.output_n # init weights self.input_weights = make_matrix(self.input_n, self.hidden_n) self.output_weights = make_matrix(self.hidden_n, self.output_n) # random activate for i in range(self.input_n): for h in range(self.hidden_n): self.input_weights[i][h] = rand(-0.2, 0.2) for h in range(self.hidden_n): for o in range(self.output_n): self.output_weights[h][o] = rand(-2.0, 2.0) # init correction matrix self.input_correction = make_matrix(self.input_n, self.hidden_n) self.output_correction = make_matrix(self.hidden_n, self.output_n) def predict(self, inputs): # activate input layer for i in range(self.input_n - 1): self.input_cells[i] = inputs[i] # activate hidden layer for j in range(self.hidden_n): total = 0.0 for i in range(self.input_n): total += self.input_cells[i] * self.input_weights[i][j] self.hidden_cells[j] = sigmoid(total) # activate output layer for k in range(self.output_n): total = 0.0 for j in range(self.hidden_n): total += self.hidden_cells[j] * self.output_weights[j][k] self.output_cells[k] = sigmoid(total) return self.output_cells[:] def back_propagate(self, case, label, learn, correct): # feed forward self.predict(case) # get output layer error output_deltas = [0.0] * self.output_n for o in range(self.output_n): error = label[o] - self.output_cells[o] output_deltas[o] = sigmod_derivate(self.output_cells[o]) * error # get hidden layer error hidden_deltas = [0.0] * self.hidden_n for h in range(self.hidden_n): error = 0.0 for o in range(self.output_n): error += output_deltas[o] * self.output_weights[h][o] hidden_deltas[h] = sigmod_derivate(self.hidden_cells[h]) * error # update output weights for h in range(self.hidden_n): for o in range(self.output_n): change = output_deltas[o] * self.hidden_cells[h] self.output_weights[h][o] += learn * change + correct * self.output_correction[h][o] self.output_correction[h][o] = change # update input weights for i in range(self.input_n): for h in range(self.hidden_n): change = hidden_deltas[h] * self.input_cells[i] self.input_weights[i][h] += learn * change + correct * self.input_correction[i][h] self.input_correction[i][h] = change # get global error error = 0.0 for o in range(len(label)): error += 0.5 * (label[o] - self.output_cells[o]) ** 2 return error def train(self, cases, labels, limit=10000, learn=0.05, correct=0.1): for i in range(limit): error = 0.0 for i in range(len(cases)): label = labels[i] case = cases[i] error += self.back_propagate(case, label, learn, correct) def test(self,id): result=getData("000001", "2015-01-05", "2015-01-09") result2=getDataR("000001", "2015-01-05", "2015-01-09") self.setup(11, 5, 1) self.train(result, result2, 10000, 0.05, 0.1) for t in resulttest: print(self.predict(t))
下面是选取14-15年数据进行训练,16年数据作为测试集,调仓周期为20个交易日,大约1个月,对上证50中的股票进行预测,选取预测的涨幅前10的股票买入,对每只股票分配一样的资金,初步运行没有问题,但就是太慢了,等哪天有空了再运行
import BPnet import tushare as ts import pandas as pd import math import xlrd import datetime as dt import time # #nn =BPnet.BPNeuralNetwork() #nn.test('000001') #for i in ts.get_sz50s()['code']: holdList=pd.DataFrame(columns=['time','id','value']) share=ts.get_sz50s()['code'] time2=ts.get_k_data('000001')['date'] newtime = time2[400:640] newcount=0 for itime in newtime: print(itime) if newcount % 20 == 0: sharelist = pd.DataFrame(columns=['time','id','value']) for ishare in share: backwardtime = time.strftime('%Y-%m-%d',time.localtime(time.mktime(time.strptime(itime,'%Y-%m-%d'))-432000*4)) trainData = BPnet.getData(ishare, '2014-05-22',itime) trainDataR = BPnet.getDataR(ishare, '2014-05-22',itime) testData = BPnet.getData(ishare, backwardtime,itime) try: print(testData) testData = testData[-1] print(testData) nn = BPnet.BPNeuralNetwork() nn.setup(11, 5, 1) nn.train(trainData, trainDataR, 10000, 0.05, 0.1) value = nn.predict(testData) newlist= pd.DataFrame({'time':itime,"id":ishare,"value":value},index=["0"]) sharelist = sharelist.append(newlist,ignore_index=True) except: pass sharelist=sharelist.sort(columns ='value',ascending=False) sharelist = sharelist[:10] holdList=holdList.append(sharelist,ignore_index=True) newcount+=1 print(holdList)