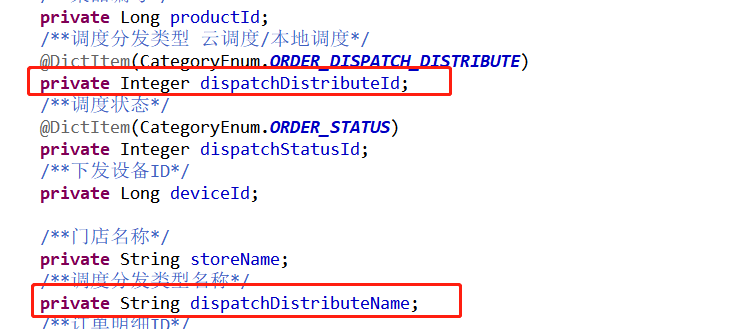
1、编写翻译字典@Dict
/**
* 数据字典翻译注解
*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Dict {
public static final String SOURCE_NAME = "Id";
public static final String TARGET_NAME = "Name";
}
2、编写翻译字段注解@DictItem
@Target({ FIELD })
@Retention(RUNTIME)
public @interface DictItem {
CategoryEnum value();
}
3、编写切面实现翻译
@Aspect
@Component
@Slf4j
public class DictAspect {
@Reference
private SysDictionaryDubboService sysDictionaryDubboService;
@Pointcut("execution(* com.bgy.order.controller..*(..))")
public void packagePointCut(){}
/**
* 返回增强:目标方法正常执行完毕时执行
*
* @param joinPoint
* @param result
*/
@AfterReturning(pointcut = "packagePointCut() && @annotation(dict)", returning = "result")
public void afterReturningMethod(JoinPoint joinPoint, Dict dict, Object result) {
processData(result);
}
private void processData(Object result) {
List<String> needProcessFieldList = new ArrayList<>();
Map<String,Field> fieldMap = new HashMap<>();
if (result instanceof Page) {
for(Object object : ((Page<?>)result).getRecords()){
getProcessFieldList(object, needProcessFieldList, fieldMap);
processSingleData(object, needProcessFieldList, fieldMap);
}
} else if(result instanceof List) {
for(Object object : (List<?>) result) {
getProcessFieldList(object, needProcessFieldList, fieldMap);
processSingleData(object, needProcessFieldList, fieldMap);
}
} else if(result instanceof Map){
for(Object obj : ((Map<?,?>)result).values()){
processData(obj);
}
} else if(result instanceof Serializable){
getProcessFieldList(result, needProcessFieldList,fieldMap);
processSingleData(result, needProcessFieldList,fieldMap);
}
}
private void getProcessFieldList(Object result, List<String> needProcessFieldList, Map<String,Field> fieldMap) {
if(!(result instanceof Serializable)){
return;
}
List<Field> declaredFields = getAllField(result.getClass());
if (CollectionUtils.isEmpty(declaredFields)) {
return;
}
for(Field field : declaredFields){
fieldMap.put(field.getName(), field);
DictItem dictItem = field.getAnnotation(DictItem.class);
if(dictItem != null){
needProcessFieldList.add(field.getName());
}
}
}
private List<Field> getAllField(Class<?> clz){
List<Field> fieldList = new ArrayList<>() ;
Class<?> tempClass = clz;
while (tempClass != null) {//当父类为null的时候说明到达了最上层的父类(Object类).
fieldList.addAll(Arrays.asList(tempClass.getDeclaredFields()));
tempClass = tempClass.getSuperclass(); //得到父类,然后赋给自己
}
return fieldList;
}
private void processSingleData(Object data, List<String> needProcessFieldList,Map<String,Field> fieldMap){
for(String fieldName : needProcessFieldList){
setDataDesc(data, fieldMap, fieldName);
}
}
private void setDataDesc(Object data, Map<String, Field> fieldMap, String fieldName) {
try {
Field field = fieldMap.get(fieldName);
Class<?> type = fieldMap.get(fieldName).getType();
if(!type.equals(Integer.class)){
return;
}
field.setAccessible(true);
Integer dictKey = (Integer)field.get(data);
DictItem dictItem = field.getAnnotation(DictItem.class);
CategoryEnum categoryEnum = dictItem.value();
if(!fieldName.endsWith(Dict.SOURCE_NAME)){
return;
}
String targetFiledName = fieldName.replace(Dict.SOURCE_NAME,Dict.TARGET_NAME);
Field findField = fieldMap.get(targetFiledName);
if (findField == null || !findField.getType().equals(String.class)) {
return ;
}
findField.setAccessible(true);
String dictValue = sysDictionaryDubboService.getDictName(categoryEnum, dictKey);
findField.set(data, dictValue);
} catch (Exception e) {
log.error("注入字典名称报错", e);
}
}
4、测试