背景
项目要对两个文件(一个用户名和一个密码文件)顺序存储的记录进行交叉组合遍历,组装成登陆命令进行远程主机的登陆尝试。
但是由于遍历集合太大,要做每次固定数量的增量扫描,下次扫描会从上次中断的地方继续。
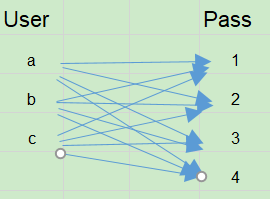
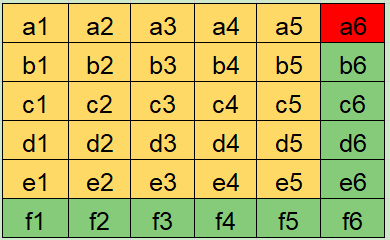
在两次扫描之间,可能会添加新的用户名和密码追加到两个文件尾部。这样,仅仅使用保存下标的信息是不行的。如下图所示。
-
两个集合的笛卡儿积
-
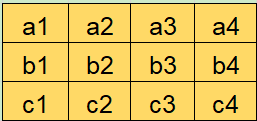
假设每次只有 5 个扫描额度,然后暂停并且保存了下一次要扫描的位置([b, 2])。
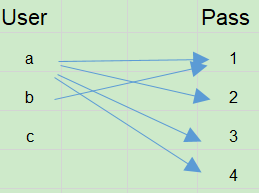
扫描集合: {[a, 1], [a, 2], [a, 3], [a, 4], [b, 1]}
保存状态: [b, 2] -
当恢复下次扫描的时候,可以直接从保存的状态恢复。
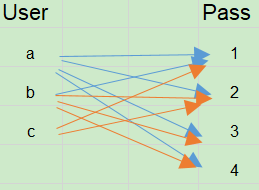
扫描集合: {[b, 2], [b, 3], [b, 4], [c, 1], [c ,2]}
保存状态: [c, 3] -
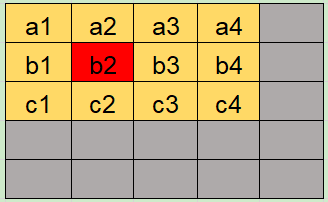
但是如果在第 2 和 第 3 步之间,字典文件进行了更新(暂且只支持 Append 操作),则会发生漏扫描。
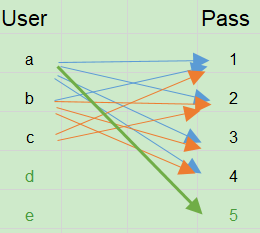
扫描集合: {[b, 2], [b, 3], [b, 4], [c, 1], [c ,2]}
保存状态: [c, 3]
丢失集合: {[a, 5]}
在增加了 User 集合的 {5,6} 和 Pass 集合的 {d} 拢共 3 个元素之后,由于缺乏回溯机制,会导致丢失 [a, 5+] 部分的组合。仅仅根据目前保存的中间状态,是无法确定哪部分的记录是增加的。因此需要额外保存信息来记录这种改变。
总结一下问题和条件:
- 必须完整并且无冗余的进行组合遍历。
- 每两次中断之间可能会对数据进行追加,简单的回溯方法可能比较麻烦并且不好实现。
- 外部输入参数目前有上次保存的位置
lastIndex以及每次扫描的步长stepSize。 - 不允许将两个数据文件预先混成一个,因为不便于维护。
- 给新数据添加时间戳,然后每次回溯时可以基于时间戳比较,但是同样不便于维护。
- 尽量最少的保存外部状态。
算法描述:
保证完整遍历的关键,就是要保证每次扫描中断时,一定范围内的用户名和密码的组合要稳定的,即不受外部增加新数据的影响。如果将两个集合的乘积看作一个矩阵,而进行组合遍历就相当于遍历这个矩阵。定义三个区域,这三个区域都是以 (0,0) 起始,并且用 <右下坐标-x, 右下坐标-y> 来描述的。
- used: 初始数据区域。开始是一个 {users.count * passwords.count} 的矩阵。当坐标落在 used 区域中时,可以很容易将 lastIndex 映射到矩阵的下标。
- work: 扩展区域。在这个区域中扫描意味着 used 中的初始数据已经完成组合遍历,但是在扫描 used 过程中添加了新的数据,于是在完成 used 扫描的时候扩展得到了 work 区域。第一次扫描的时候是与 used 重合的。当坐标落在 work 区域中时,需要在 L 型的区域进行寻址。
- max: 开始的阶段因为没有新的数据增加,所以与used重合。
在扫描过程中,会有两种区域扩展的动作,其时机为:
- 初始的 used 区域扫描完成。此时状态为
used == work <= max。如果max > work,说明有新的数据,则将 work 扩展到 max,然后扫描 work 中的区域。若work == max说明组合遍历结束。 - 在 work 区域扫描完成。此时状态为
used < work <= max。会将 used 扩展到 work,work 扩展到 max。
需要保存的状态:
| name | description | initial Value | scope |
|---|---|---|---|
| lastIndex | 存档点 | 0 | [0, 笛卡儿积容量] |
| stepSize | 步长 | 5 | [1, 笛卡儿积容量] |
| usedRegion | used 区域右下端点坐标 | [初始集合1的长度, 初始集合2的长度] | |
| workRegion | work 区域右下端点坐标 | [初始集合1的长度, 初始集合2的长度] |
总计需要保存 6 个整形数值。
其中 max 区域的坐标可以从两个数据文件行数相乘得来,不需要保存。
每次组合遍历开始时从外部读入上述参数,结束时将上述参数写回外部存储。
原理说明
used: 黄色区块
work: 绿色区块
max: 灰色区块
存档点: 红色区块
已扫描的组合: 蓝色线
当前扫描的组合: 橙色线
遗漏的组合:绿色线
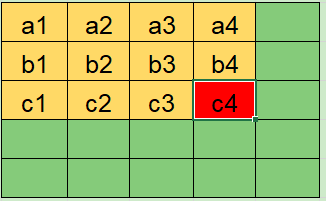
初始状态
可以看到这三个区域是重叠的,遍历这个矩阵就等于得到了全部的用户名和密码组合。
第一次组合遍历
读取状态
lastIndex = 0
stepSize = 5
usedRegion = [3,4]
workRegion = [3,4]
maxRegion = [3,4]

保存状态
lastIndex = 5
stepSize = 5
usedRegion = [3,4]
workRegion = [3,4]
第二次组合遍历
读取状态
lastIndex = 5
stepSize = 5
usedRegion = [3,4]
workRegion = [3,4]
maxRegion = [5,5]
虽然有新的数据加入进来,但是 work 区域只是当 used 区域扫描完成再扩展。
保存状态
lastIndex = 10
stepSize = 5
usedRegion = [3,4]
workRegion = [3,4]
第一次区域扩展
读取状态
lastIndex = 10
stepSize = 5
usedRegion = [3,4]
workRegion = [3,4]
maxRegion = [5,5]
在 work region 中寻址方式需要改变。
保存状态
lastIndex = 15
stepSize = 5
usedRegion = [3,4]
workRegion = [5,5]
扩展区域中的扫描
读取状态
lastIndex = 15
stepSize = 5
usedRegion = [3,4]
workRegion = [5,5]
maxRegion = [5,5]

保存状态
lastIndex = 20
stepSize = 5
usedRegion = [3,4]
workRegion = [5,5]
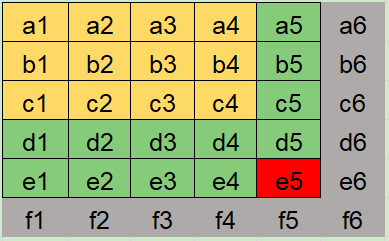
第二次区域扩展
当 work 区域扫描完成,如果 max 有数据,说明在扫描 work 区域的期间又增加了新的数据。
状态
lastIndex = 20
stepSize = 5
usedRegion = [3,4]
workRegion = [5,5]
maxRegion = [6,6]
状态
lastIndex = 25
stepSize = 5
usedRegion = [3,4]
workRegion = [5,5]
maxRegion = [6,6]
状态
lastIndex = 26
stepSize = 5
usedRegion = [5,5]
workRegion = [5,5]
maxRegion = [6,6]
结束扫描
当经过扩展之后,三个坐标重叠,说明已经完成一轮完整的扫描。
状态
lastIndex = 36
stepSize = 5
usedRegion = [6,6]
workRegion = [6,6]
maxRegion = [6,6]
演示代码:
package main
import (
"fmt"
"io/ioutil"
"strings"
)
/*Point indicate a coordinate contain a pairs <x,y>*/
type Point struct {
x int
y int
}
/*Square is a region which marked use coordinate*/
type Square struct {
start Point
end Point
area int
}
func NewSquareOriginly(endX int, endY int) Square {
return NewSquare(0, 0, endX, endY)
}
func NewSquare(startX int, startY int, endX int, endY int) Square {
var startPoint = Point{startX, startY}
var endPoint = Point{endX, endY}
return Square{
start: startPoint,
end: endPoint,
area: (endX - startPoint.x) * (endY - startPoint.y),
}
}
func (thisSquare *Square) ExpandSquare(endX int, endY int) {
thisSquare.ReCoordinate(thisSquare.start.x, thisSquare.start.y, endX, endY)
}
func (thisSquare *Square) ReCoordinate(startX int, startY int, endX int, endY int) {
thisSquare.start.x = startX
thisSquare.start.y = endX
thisSquare.end.x = endX
thisSquare.end.y = endY
thisSquare.area = (endX - startX) * (endY - startY)
}
func loadData(filename string) []string {
fileContent, err := ioutil.ReadFile(filename)
if err != nil {
panic("can not read file")
}
var contextString = string(fileContent)
var dataArray = strings.Split(contextString, "
")
return dataArray
}
func main() {
// cmdline parameters, lastIndex means start index which begin 0
var lastIndex = 25
const stepSize = 5
// region status parameters from cmdline, used >= work >= max
var usedRegion = NewSquareOriginly(3, 4)
var workRegion = NewSquareOriginly(5, 7)
// internal variables
const userFileName = "data/u.txt"
const PasswordFileName = "data/p.txt"
var users = loadData(userFileName)
var passwords = loadData(PasswordFileName)
var maxRegion = NewSquareOriginly(len(users), len(passwords))
var mapedPoint Point
for ind, endIndex := lastIndex, (lastIndex + stepSize); ind < endIndex; ind++ {
if ind < usedRegion.area {
// if ind not out of used region, we can simply located the coordinate
mapedPoint = getCoordinateInUsed(usedRegion, ind)
} else if ind < workRegion.area {
// in work region, we use L-sharpe located way
mapedPoint = getCoordinateInWork(workRegion, usedRegion, ind)
} else {
// expand used region to work region, expand woek region to max region
usedRegion.ExpandSquare(workRegion.end.x, workRegion.end.)
workRegion.ExpandSquare(maxRegion.end.x, maxRegion.end.y)
// no more data
if (usedRegion.end.x==maxRegion.end.x && usedRegion.end.y==maxRegion.end.y) break
mapedPoint = getCoordinateInWork(workRegion, usedRegion, ind)
}
fmt.Println(mapedPoint)
}
}
// rectangle coordinate
func getCoordinateInUsed(region Square, uniformIndex int) Point {
return Point{uniformIndex / region.end.y, uniformIndex % region.end.y}
}
// L-sharp coordinate
func getCoordinateInWork(integralRegion Square, hollowRegion Square, uniformIndex int) Point {
// right square region
rightWidth := integralRegion.end.y - hollowRegion.end.y
// rightHeight := hollowRegion.end.x
rightSquare := NewSquare(0, hollowRegion.end.y, hollowRegion.end.x, integralRegion.end.y)
// bottom square region
bottomWidth := integralRegion.end.y
edgeIndex := uniformIndex - hollowRegion.area
if edgeIndex < rightSquare.area {
return Point{edgeIndex / rightWidth, edgeIndex%rightWidth + hollowRegion.end.y}
} else {
edgeBottomIndex := edgeIndex - rightSquare.area
return Point{edgeBottomIndex/bottomWidth + hollowRegion.end.x, edgeBottomIndex % bottomWidth}
}
}
小结和扩展
上面涉及到在初始的 used 区域中和扩展 work 区域中两种寻址方式,可以将初始的 used 置为 (0,0) 来统一成 L型 一种寻址方式。由于考虑到数据文件更新并非很频繁和计算的简单性,可以在遍历 used 就结束整个扫描过程了。
平时工作中总是可以使用简单的设计来避免使用暴力的解决方案。对于本文的问题,简单的根据 (M*N) => (M + a)*(N + b) = MN + aN + bM + ab 可知每次存档后需要对当前扫描的区域进行保存即可。如果是多个集合的组合遍历,则保存多个维度并且不是在二维的 L型 区域寻址而是 N维的空间寻址。