一.etcd介绍
etcd是一个分布式、可靠的key-value存储的分布式系统,它不仅仅可以用于存储,还提供共享配置和服务发现。这里提供配置共享和服务发现的系统较多,比较常用的有zookeeper。
二.etcd安装
这里,我们以二进制+TLS证书部署kubernetes的etcd集群为例,进行说明:
2.1 部署环境
| 环境IP | 主机名 | 操作系统 |
|---|---|---|
| 172.16.1.188 | k8s001 | centos7.5 |
| 172.16.1.189 | k8s002 | centos7.5 |
| 172.16.1.190 | k8s003 | centos7.5 |
2.2 安装CFSSL加密工具
这里在172.16.1.188节点安装即可:
[root@k8s001 ~]#wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
[root@k8s001 ~]#wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
[root@k8s001 ~]#wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
[root@k8s001 ~]#chmod +x cfssl_linux-amd64 cfssljson_linux-amd64 cfssl-certinfo_linux-amd64
[root@k8s001 ~]#mv cfssl_linux-amd64 /usr/local/bin/cfssl
[root@k8s001 ~]#mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
[root@k8s001 ~]#mv cfssl-certinfo_linux-amd64 /usr/bin/cfssl-certinfo
2.3 创建证书
2.3.1 创建根证书
- 所有节点创建根证书存放目录
[root@k8s001 ~]# mkdir -p /etc/kubernetes/cert
[root@k8s002 ~]# mkdir -p /etc/kubernetes/cert
[root@k8s003 ~]# mkdir -p /etc/kubernetes/cert
- 创建CA配置文件
[root@node-01 ~]# cd /etc/kubernetes/cert
#这里我们设置证书的有效时长为10年
[root@k8s001 cert]# cat << EOF | tee ca-config.json
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "87600h"
}
}
}
}
EOF
- 创建CA证书签名请求
[root@k8s001 cert]# cat << EOF | tee ca-csr.json
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
- 生成CA证书和私钥
#这一步生成ca.pem和ca-key.pem和ca.csr
[root@k8s001 cert]# cfssl gencert -initca ca-csr.json | cfssljson -bare ca
- 将证书分发到三台服务器节点
[root@k8s001 cert]#scp -p ca*pem 172.16.1.189:/etc/kubernetes/cert/
[root@k8s001 cert]#scp -p ca*pem 172.16.1.190:/etc/kubernetes/cert/
2.3.2 创建etcd证书
- 创建etcd证书配置文件
#注意:hosts需要配置本机,所有etcd节点的IP信息
[root@k8s001 cert]# cat << EOF | tee etcd-csr.json
{
"CN": "etcd",
"hosts": [
"127.0.0.1",
"172.16.1.188",
"172.16.1.189",
"172.16.1.190"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
- 生成etcd证书
#生成etcd-key.pem和etcd.pem和etcd.csr
[root@k8s001 cert]#cfssl gencert -ca=/etc/kubernetes/cert/ca.pem
-ca-key=/etc/kubernetes/cert/ca-key.pem
-config=/etc/kubernetes/cert/ca-config.json
-profile=kubernetes etcd-csr.json | cfssljson -bare etcd
- 将etcd证书和私钥分发到三台etcd节点的/etc/kubernetes/cert目录下
这里etcd使用的证书文件为:ca.pem、etcd-key.pem、etcd.pem
[root@k8s001 cert]#scp -p etcd*pem 172.16.1.189:/etc/kubernetes/cert/
[root@k8s001 cert]#scp -p etcd*pem 172.16.1.190:/etc/kubernetes/cert/
2.4 部署etcd集群
- 下载etcd的安装包[所有节点]
[root@k8s001 ~]# wget https://github.com/etcd-io/etcd/releases/download/v3.3.10/etcd-v3.3.10-linux-amd64.tar.gz
[root@k8s001 ~]# tar -xvf etcd-v3.3.10-linux-amd64.tar.gz
[root@k8s001 ~]# cp etcd-v3.3.10-linux-amd64/etcd* /usr/bin
[root@k8s001 ~]# scp etcd-v3.3.10-linux-amd64/etcd* 172.16.1.189:/usr/bin
[root@k8s001 ~]# scp etcd-v3.3.10-linux-amd64/etcd* 172.16.1.190:/usr/bin
- 创建etcd的工作目录[所有节点]
[root@k8s001 ~]# mkdir -p /var/lib/etcd
[root@k8s002 ~]# mkdir -p /var/lib/etcd
[root@k8s003 ~]# mkdir -p /var/lib/etcd
- 创建etcd的service文件
[root@k8s001 system]# cat << EOF | tee /usr/lib/systemd/system/etcd.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/
ExecStart=/usr/bin/etcd
--name etcd1
--cert-file=/etc/kubernetes/cert/etcd.pem
--key-file=/etc/kubernetes/cert/etcd-key.pem
--peer-cert-file=/etc/kubernetes/cert/etcd.pem
--peer-key-file=/etc/kubernetes/cert/etcd-key.pem
--trusted-ca-file=/etc/kubernetes/cert/ca.pem
--peer-trusted-ca-file=/etc/kubernetes/cert/ca.pem
#这里指定etcd对应节点的IP
--initial-advertise-peer-urls https://172.16.1.188:2380
#这里指定etcd对应节点的IP
--listen-peer-urls https://172.16.1.188:2380
#这里指定etcd对应节点的IP
--listen-client-urls https://172.16.1.188:2379,http://127.0.0.1:2379
#这里指定etcd对应节点的IP
--advertise-client-urls https://172.16.1.188:2379
--initial-cluster-token etcd-cluster-0
#这里对应etcd集群所有节点的IP信息
--initial-cluster etcd1=https://172.16.1.188:2380,etcd2=https://172.16.1.189:2380,etcd3=https://172.16.1.190:2380
--initial-cluster-state new
--data-dir=/var/lib/etcd
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
- 将etcd.service分发到其它节点,并修改配置
[root@k8s001 system]# scp -p etcd.service 172.16.1.189:/usr/lib/systemd/system/
[root@k8s001 system]# scp -p etcd.service 172.16.1.190:/usr/lib/systemd/system/
[root@k8s002 ~]# cat /usr/lib/systemd/system/etcd.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/
ExecStart=/usr/bin/etcd
--name etcd2
--cert-file=/etc/kubernetes/cert/etcd.pem
--key-file=/etc/kubernetes/cert/etcd-key.pem
--peer-cert-file=/etc/kubernetes/cert/etcd.pem
--peer-key-file=/etc/kubernetes/cert/etcd-key.pem
--trusted-ca-file=/etc/kubernetes/cert/ca.pem
--peer-trusted-ca-file=/etc/kubernetes/cert/ca.pem
--initial-advertise-peer-urls https://172.167.1.189:2380
--listen-peer-urls https://172.16.1.189:2380
--listen-client-urls https://172.16.1.189:2379,http://127.0.0.1:2379
--advertise-client-urls https://172.16.1.189:2379
--initial-cluster-token etcd-cluster-1
--initial-cluster etcd1=https://172.16.1.188:2380,etcd2=https://172.16.1.189:2380,etcd3=https://172.16.1.190:2380
--initial-cluster-state new
--data-dir=/var/lib/etcd
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
[root@k8s003 ~]# cat /usr/lib/systemd/system/etcd.service
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/
ExecStart=/usr/bin/etcd
--name etcd3
--cert-file=/etc/kubernetes/cert/etcd.pem
--key-file=/etc/kubernetes/cert/etcd-key.pem
--peer-cert-file=/etc/kubernetes/cert/etcd.pem
--peer-key-file=/etc/kubernetes/cert/etcd-key.pem
--trusted-ca-file=/etc/kubernetes/cert/ca.pem
--peer-trusted-ca-file=/etc/kubernetes/cert/ca.pem
--initial-advertise-peer-urls https://172.16.1.190:2380
--listen-peer-urls https://172.16.1.190:2380
--listen-client-urls https://172.16.1.190:2379,http://127.0.0.1:2379
--advertise-client-urls https://172.16.1.190:2379
--initial-cluster-token etcd-cluster-2
--initial-cluster etcd1=https://172.16.1.188:2380,etcd2=https://172.16.1.189:2380,etcd3=https://172.16.1.190:2380
--initial-cluster-state new
--data-dir=/var/lib/etcd
Restart=on-failure
RestartSec=5
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
- 所有etcd节点启动etcd服务
[root@k8s001 ~]# systemctl daemon-reload && systemctl enable etcd && systemctl start etcd
[root@k8s002 ~]# systemctl daemon-reload && systemctl enable etcd && systemctl start etcd
[root@k8s003 ~]# systemctl daemon-reload && systemctl enable etcd && systemctl start etcd
- 查看etcd集群是否运行正常
[root@k8s001 ~]# etcdctl --ca-file=/etc/kubernetes/cert/ca.pem --cert-file=/etc/kubernetes/cert/etcd.pem --key-file=/etc/kubernetes/cert/etcd-key.pem cluster-health
member 2721asdasd42e0a4 is healthy: got healthy result from https://172.16.1.189:2379
member 2dad92695qewe7e7 is healthy: got healthy result from https://172.16.1.190:2379
member eqwe321313455dfg is healthy: got healthy result from https://172.16.1.188:2379
cluster is healthy
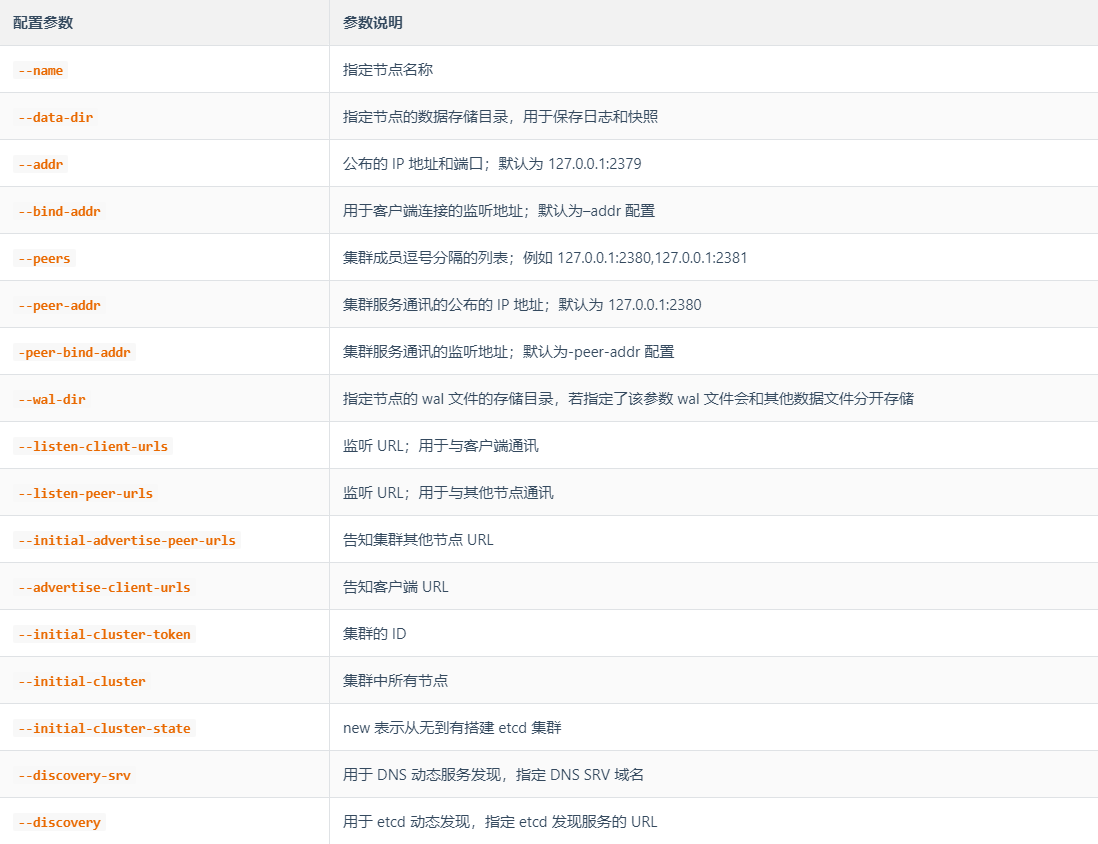
2.5 etcd常用配置参数
3.ETCD数据目录介绍
使用etcd,我们指定了数据存放目录/var/lib/etcd,查看这个目录下的内容,目录下存在两个子目录snap和wal目录,具体如下:
[root@k8s001 ~]# ls /var/lib/etcd/member
snap wal
- snap
- 存放快照数据,存储etcd的数据状态
- etcd防止WAL文件过多而设置的快照
- wal
- 存放预写式日志
- 最大的作用是记录了整个数据变化的全部历程
- 在etcd中,所有数据的修改在提交前,都要先写入到WAL中。
[root@k8s001 etcd]# tree member
member
├── snap
│ ├── 0000000000000006-000000000056f9d9.snap
│ ├── 0000000000000006-000000000058807a.snap
│ ├── 0000000000000006-00000000005a071b.snap
│ ├── 0000000000000006-00000000005b8dbc.snap
│ ├── 0000000000000006-00000000005d145d.snap
│ └── db
└── wal
├── 0000000000000065-00000000005a0f54.wal
├── 0000000000000066-00000000005adeea.wal
├── 0000000000000067-00000000005bae72.wal
├── 0000000000000068-00000000005c7dfd.wal
├── 0000000000000069-00000000005d4d81.wal
└── 1.tmp
2 directories, 12 files
使用WAL进行数据的存储使得etcd拥有两个重要功能,那就是故障快速恢复和数据回滚/重做。故障快速恢复就是当你的数据遭到破坏时,就可以通过执行所有WAL中记录的修改操作,快速从最原始的数据恢复到数据损坏前的状态。数据回滚重做就是因为所有的修改操作都被记录在WAL中,需要回滚或重做,只需要方向或正向执行日志中的操作即可。
既然有了WAL实时存储了所有的变更,为什么还需要snapshot呢?随着使用量的增加,WAL存储的数据会暴增。为了防止磁盘很快就爆满,etcd默认每10000条记录做一次snapshot操作,经过 snapshot 以后的WAL文件就可以删除。而通过API可以查询的历史etcd操作默认为 1000 条。
首次启动时,etcd会把启动的配置信息存储到data-dir参数指定的数据目录中。配置信息包括本地节点的ID、集群ID和初始时集群信息。用户需要避免etcd从一个过期的数据目录中重新启动,因为使用过期的数据目录启动的节点会与集群中的其他节点产生不一致。所以,为了最大化集群的安全性,一旦有任何数据损坏或丢失的可能性,你就应该把这个节点从集群中移除,然后加入一个不带数据目录的新节点。
4.Raft算法介绍
在分布式系统中,etcd往往扮演了非常重要的地位,由于很多服务配置发现以及配置的信息都存储在etcd中,所以整个集群可用性的上限往往就是etcd的可用性。使用3~5个etcd节点构成高可用的集群是比较正常的配置。
etcd在使用的过程中会启动多个节点,如何处理几个节点之间的分布式一致性就是一个比较有挑战的问题了,解决多个节点数据一致性的方案其实就是共识算法,即Raft共识算法。
Raft一开始被设计成一个易于理解和实现的共识算法,它在容错和性能上与Paxos协议比较类似,区别在于它将分布式一致性的问题分解成了几个子问题,然后一一解决。
每一个Raft集群中都包含多个服务器,在任意时刻,每一台服务器只可能处于Leader、Follower以及Candidate三种状态;在处于正常的状态时,集群中只会存在一个Leader状态,其余的服务器都是Follower状态。

所有的Follower节点都是被动的,它们不会主动发出任何的请求,只会响应Leader和Candidate发出的请求。对于每一个用户的可变操作,都会被路由给Leader节点进行处理,除了Leader和Follower节点之外,Candidate节点其实只是集群运行过程中的一个临时状态。
Raft集群中的时间也被切分成了不同的几个任期(Term),每一个任期都会由Leader 选举开始,选举结束后就会进入正常操作的阶段,直到Leader节点出现问题才会开始新一轮的选择。

每一个服务器都会存储当前集群的最新任期,它就像是一个单调递增的逻辑时钟,能够同步各个节点之间的状态,当前节点持有的任期会随着每一个请求被传递到其他的节点上。Raft协议在每一个任期的开始时都会从一个集群中选出一个节点作为集群的Leader节点,这个节点会负责集群中的日志的复制以及管理工作。
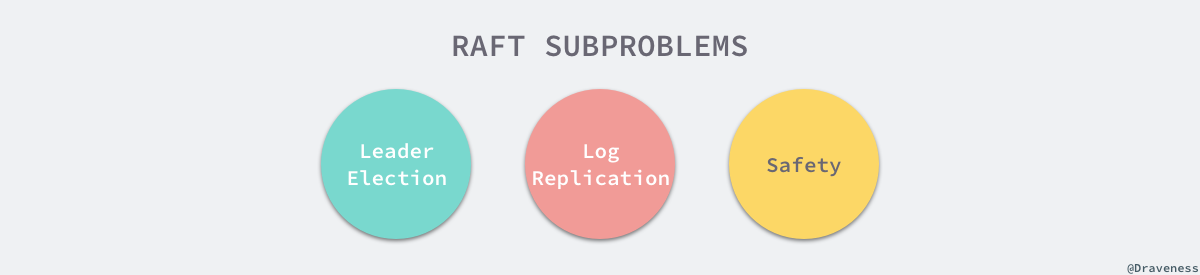
我们将 Raft 协议分成三个子问题:节点选举、日志复制以及安全性。
5. 服务发现
服务发现是etcd服务主要的用途之一。
服务发现要解决的也是分布式系统中最常见的问题之一,即在同一个分布式集群中的进程或服务,要如何才能找到对方并建立连接。本质上来说,服务发现就是想要了解集群中是否有进程在监听UDP或TCP端口,并且通过名字就可以查找和连接。要解决服务发现的问题,需要有下面三大支柱,缺一不可。
- 一个强一致性、高可用的服务存储目录
- 基于Raft算法的etcd天生就是这样一个强一致性高可用的服务存储目录
- 一种注册服务和监控服务健康状态的机制
- 用户可以在etcd中注册服务,并且对注册的服务设置key TTL值,定时保持服务的心跳以达到监控服务健康状态的效果。
- 一种查找和连接服务的机制
- 为了确保连接,我们可以在每个服务机器上都部署一个Proxy模式的etcd,这样就可以确保能访问etcd集群的服务都能互相连接。
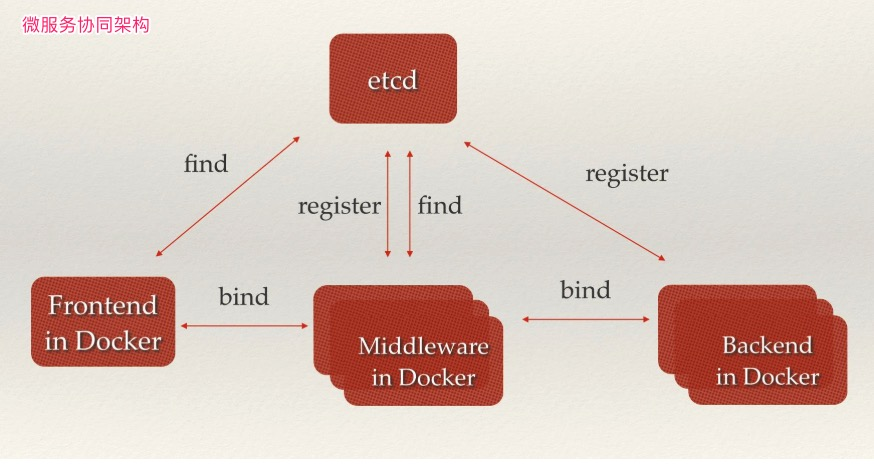
- 为了确保连接,我们可以在每个服务机器上都部署一个Proxy模式的etcd,这样就可以确保能访问etcd集群的服务都能互相连接。
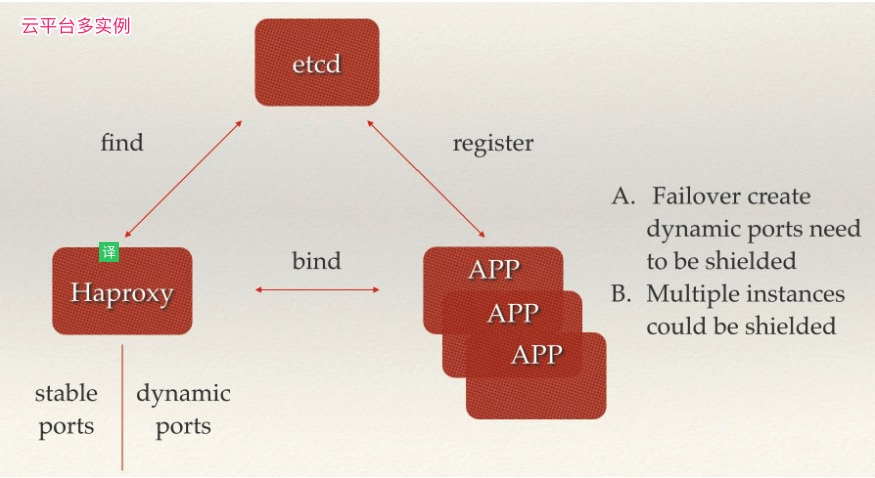
日常开发集群管理功能中,如果要设计可以动态调整集群大小。那么首先就要支持服务发现,就是说当一个新的节点启动时,可以将自己的信息注册给master,然后让master把它加入到集群里,关闭之后也可以把自己从集群中删除。etcd提供了很好的服务注册与发现的基础功,我们采用etcd来做服务发现时,可以把精力用于服务本身的业务处理上。
6.灾难恢复
etcd被设计为能承受集群自动从临时失败(例如机器重启)中恢复,而且对于一个有N个成员的集群能容许(N-1)/2 的持续失败。当一个成员持续失败时,不管是因为硬件失败或者磁盘损坏,它丢失到集群的访问。如果集群持续丢失超过(N-1)/2 的成员,则它只能悲惨的失败,无可救药的失去法定人数(quorum)。一旦法定人数丢失,集群无法达到一致性而导致无法继续接收更新。为了从灾难失败中恢复数据,etcd v3提供快照和修复工具来重建集群而不丢失v3键数据。
6.1 etcd证书制作
由于 v3 版本的 etcd 证书是基于 IP 的,所以每次新增 etcd 节点都需要重新制作证书。这里具体可以参考2.2和2.3章节。
6.2 备份集群
# 在单节点etcd上执行下面的命令就可以对etcd进行数据备份
$ export ETCDCTL_API=3
$ etcdctl --endpoints 127.0.0.1:2379 snapshot save $(date +%Y%m%d_%H%M%S)_snapshot.db
6.3 恢复集群
为了恢复集群,使用之前任意节点上备份的快照 "db" 文件。恢复的手,可以使用etcdctl snapshot restore命令来恢复etc 数据目录,此时所有成员应该使用相同的快照恢复。因为恢复数据死后,会覆盖某些快照元数据(特别是成员ID和集群ID)信息,集群内的成员可能会丢失它之前的标识。因此为了从快照启动集群,恢复必须启动一个新的逻辑集群。
在恢复时,快照完整性的检验是可选的。如果快照是通过etcdctl snapshot save得到的话,使用etcdctl snapshot restore命令恢复的时候,会检查hash值的完整性。如果快照是从数据目录复制而来,则没有完整性校验,因此它只能通过使用--skip-hash-check来恢复。
1.恢复时,首先停止掉etcd的服务
[root@k8s001 ~]# systemctl stop etcd
[root@k8s002 ~]# systemctl stop etcd
[root@k8s003 ~]# systemctl stop etcd
2.清除异常数据目录
[root@k8s001 ~]# rm -rf /var/lib/etcd
[root@k8s002 ~]# rm -rf /var/lib/etcd
[root@k8s003 ~]# rm -rf /var/lib/etcd
3.恢复etcd数据目录
[root@k8s001 ~]# export ETCDCTL_API=3
[root@k8s001 ~]# etcdctl snapshot restore 20200629_200504_snapshot.db --name etcd1 --initial-cluster etcd1=https://172.16.1.188:2380,etcd2=https://172.16.1.189:2380,etcd3=https://172.16.1.190:2380 --initial-cluster-token=etcd-cluster-0 --initial-advertise-peer-urls=https://172.16.1.188:2380 --data-dir /var/lib/etcd
[root@k8s002 ~]# export ETCDCTL_API=3
[root@k8s002 ~]# etcdctl snapshot restore 20200629_200504_snapshot.db --name etcd2 --initial-cluster etcd1=https://172.16.1.188:2380,etcd2=https://172.16.1.189:2380,etcd3=https://172.16.1.190:2380 --initial-cluster-token=etcd-cluster-1 --initial-advertise-peer-urls=https://172.16.1.189:2380 --data-dir /var/lib/etcd
[root@k8s003 ~]# export ETCDCTL_API=3
[root@k8s003 ~]# etcdctl snapshot restore 20200629_200504_snapshot.db --name etcd3 --initial-cluster etcd1=https://172.16.1.188:2380,etcd2=https://172.16.1.189:2380,etcd3=https://172.16.1.190:2380 --initial-cluster-token=etcd-cluster-2 --initial-advertise-peer-urls=https://172.16.1.190:2380 --data-dir /var/lib/etcd
4.启动etcd服务
[root@k8s001 ~]# systemctl restart etcd
[root@k8s002 ~]# systemctl restart etcd
[root@k8s003 ~]# systemctl restart etcd
6.4 单节点集群备份恢复
[root@k8s001 ~]# export ETCDCTL_API=3
[root@k8s001 ~]# etcdctl --endpoints 127.0.0.1:2379 snapshot save $(date +%Y%m%d_%H%M%S)_snapshot.db
[root@k8s001 ~]# systemctl stop etcd
[root@k8s001 ~]# rm -rf /var/lib/etcd
[root@k8s001 ~]# etcdctl snapshot restore 20200629_141504_snapshot.db --data-dir /var/lib/etcd
[root@k8s001 ~]# systemctl restart etcd