网络爬虫 Web crawler 可以代替人工自动从互联网中进行数据信息的采集和整理 按照一定的规则自动抓取万维网上的信息程序或者脚本
从功能上区分为 数据采集 处理 储存 这三个部分
从流程上来说 从一个或者若干个网页URL地址去抓取指定的想要的内容
为什么学习爬虫
1 可以实现搜索引擎 2大数据时代,可以让我们获取更多的数据源 3可以更好的进行搜索引擎优化SEO 4 有利于就业
依赖 Apache Httpclient 4.5.2
日志jar包 log4j 1.7.25 注意作用域 设置 默认为test测试
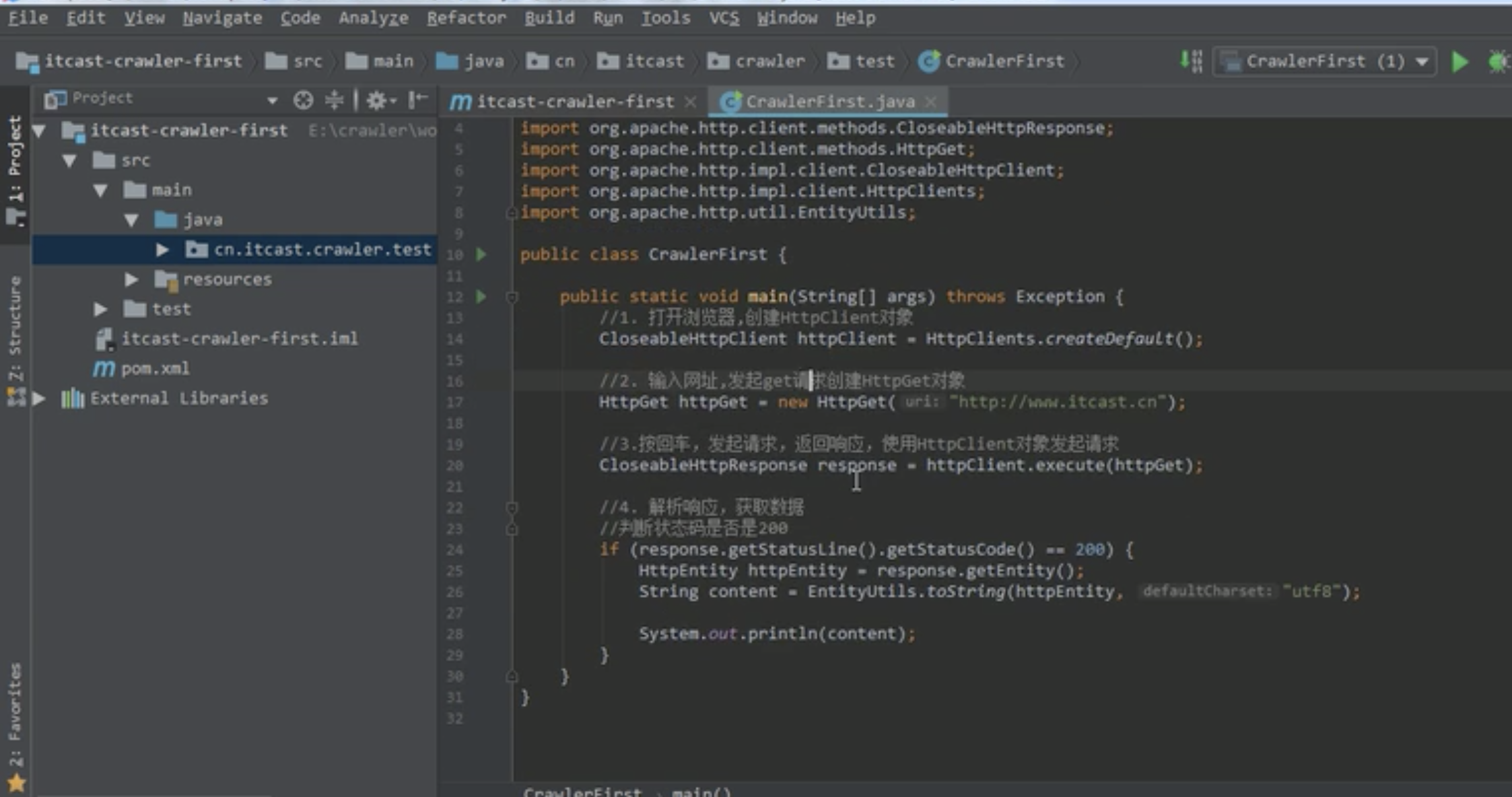
一个入门 爬取html
1.创建httpClient对象、 HttpClients。createDefault();
2 创建httpget 或者 httppost 请求 对象 在对象里设置url 地址
3 声明 List<NameValuePair> 封装表单中的参数 对象.add (BasicNameValuePair 实例对象 需要传参数的key value )
4 创建表单的Entity对象,第一个参数就是封装好的表单数据,第二个参数就是编码 UrlEncodedFormEntit (上面的对象 ,utf8)
5 实体对象拿到了 设置表单的Entity对象到url 上
6 使用HttpClient发起请求,获取response response = httpClient.execute(httpPost);
7 解析响应 response.getStatusLine().getStatusCode() == 200 的时候
当这时候会有一个资源浪费问题
解决办法 使用连接次管理起来
1 创建 连接池 PoolingHttpClientConnectionManager cm
2 设置最大连接数 cm.setMaxTotal(100);
3 设置每个主机的最大连接数 当爬去多个地址url的时候需要设置 可以平均爬去数据 cm.setDefaultMaxPerPoute(10);
4 连接池管理 doGet(cm); 可以创建多个 就是多个连接池
5 不需要每次创建新的httpClient 而是从连接池中获取httpClient 对象 HttpClients.custom().setConnectionManager(cm).build();
httpClient.execute(new HttpGet (url));
加一个判断 当状态码为200 的时候 在输出 最后记得关流 但是只是关闭 响应的对象 而httpClient 不需要关闭 已经交给了连接池管理
当网路不好的场景 可以设置请求时间 和响应时间 还有传输时间 根据实际情况调整时间长短 RequestConfig.custom().setConnectTimeout(1000)
最后记得build一下
底层实现 Jsoup
需要导入依赖
jsoup junit commons IO 里面有一些我们常用的工具类 commons Lang 包含stringUtil
其主要是通过docament id选择器 class css选择器等取html文本信息 类似jquery
webMagic
分为四大部分 一。Downloader 下载 二。Page Processor 处理 三。Scheduler 管理 四。Pipeline 持久化 由 Spider将它们组织起来 webMagic 的设计参考Scapy
Spider 可以理解成为一个大的容器 也就是webMagic逻辑的核心 下面是流程图

执行流程 可以为 Downloader负责从互联网上下载页面 下载的工具呢 就是 Apache HttpClient
PageProcessor 负责解析下载好的页面 抽取需要的信息 已经发现新的连接等 解析的工具呢 使用的 Jsoup 并且基于该工具 开发了解析XPath的工具 Xsoup
scheduler 负责管理待抓取的url 以及去重工作 管理url呢 默认提供了JDK 的内存队列来管理URL 用集合来进行去重 并且支持使用redis分布式管理 把url 交给下载器管理
pipeline 负责抽取结果的处理 包括计算 持久化 到文件,数据库等 默认提供了 输出到控制台 和保存到文件两种处理方案
创建一个项目 导入 核心包 webmagic-core 这里有个bug
最新版本的0.7。3 等于ssl 的并不安全 如果直接从maven中央仓库下载依赖 在爬去只支持ssl v1.2的网站会有ssl的异常抛出 解决方案 直接去 gitlub https://github.com/code4craft/webmagic.git 去源码包下载 或者修改重写方法
临时适配方式,修改HttpClientGenerator中的buildSSLConnectionSocketFactory方法,
return new SSLConnectionSocketFactory(createIgnoreVerifySSL(), new String[]{"SSLv3", "TLSv1", "TLSv1.1", "TLSv1.2"},
null,
new DefaultHostnameVerifier())
一个实现类 实现 PageProcessor 需要重写两个方法 public void process(Page page) getSite()
第一步 主函数执行爬虫 Spider.create(实例类) //爬虫入口 方法内是实现方法JobProcessor 实现了PagePrcessor.addUrl("") //设置爬取数据的页面
.addPipeline(new FilePipeline("/文件地址")) //设置持久化
.thread(5) //设置线程个数
pageProcessor 的作用