1、Spring中都使用了哪些设计模式?
工厂模式:
单例模式:保证一个类仅有一个实例,并提供一个访问它的全局访问点;
代理模式:在织入切面时,AOP容器会为目标对象创建动态的创建一个代理对象。SpringAOP就是以这种方式织入切面的;
适配器模式:Spring定义了一个适配接口,使得每一种Controller有一种对应的适配器实现类,让适配器代替controller执行相应的方法。这样在扩展Controller时,只需要增加一个适配器类就完成了SpringMVC的扩展了。
装饰器模式:动态地给一个对象添加一些额外的职责。就增加功能来说,Decorator模式相比生成子类更为灵活。
观察者模式:spring的事件驱动模型使用的是 观察者模式 ,Spring中Observer模式常用的地方是listener的实现。
策略模式:Spring框架的资源访问Resource接口。该接口提供了更强的资源访问能力,Spring 框架本身大量使用了Resource 接口来访问底层资源。
模板方法:父类定义了骨架(调用哪些方法及顺序),某些特定方法由子类实现。
2、AQS是的实现原理是什么?怎么获取锁和释放锁的?底层使用的乐观锁还是悲观锁?
AQS 是 AbstractQueuedSynchronizer 抽象队列同步器;在 java.util.concurrent 包下,简称JUC。
AQS实现原理:https://blog.csdn.net/zhujiangtaotaise/article/details/105843274
CLH 队列使用的双向链表;
(1)AQS中维护了 volatile 修饰的 int 类型的变量 state 来记录加锁的状态;维护了 exclusiveOwnerThread 变量,表示获得锁的线程;还有一个用来存储获取锁失败线程的 CLH 队列。
(2)T1 调用 lock() 来加锁,使用 CAS 操作将 state 的值由 0 修改为 1;并设置 exclusiveOwnerThread 为 当前线程;
(3)T2 调用 lock() 来加锁,使用 CAS 操作将 state 的值由 0 修改为 1 失败,说明当前已经有线程持有锁了,再判断当前持有锁的线程不是本线程,则会加锁失败,将获取失败的线程放到等待队列的尾部;等待 线程1 的释放锁去唤醒 线程2;
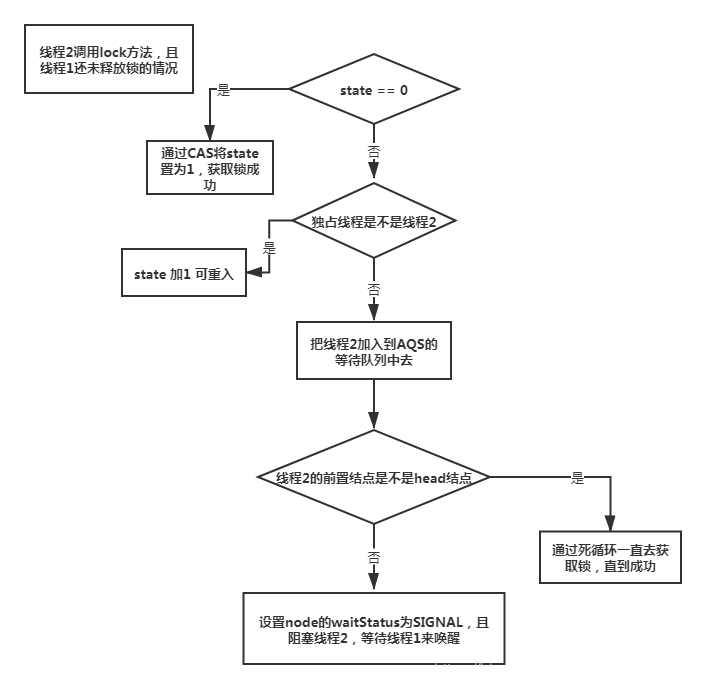
AQS 底层使用的乐观锁CAS;
3、Synchronized 会引起上下文切换吗?CAS会引起上下文切换?
Synchronized:会; CAS: 不会;
4、Synchronized 和 ReentrantLock 有什么区别?
- synchronized:隐式的获取锁和释放锁;ReentrantLock:显示的获取锁和释放锁;
- synchronized 是 JVM 级别的; ReentrantLock 是 API 级别的;
-
底层实现不一样, synchronized 是同步阻塞,使用的是悲观并发策略,lock 是同步非阻塞,采用的是乐观并发策略;
- synchronized 在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而 Lock 在发生异常时,如果没有主动通过 unLock()去释放锁,则很可能造成死锁现象,因此使用 Lock 时需要在 finally 块中释放锁。
- Lock 可以让等待锁的线程响应中断,而 synchronized 却不行,使用 synchronized 时,等待的线程会一直等待下去,不能够响应中断。
- 通过 Lock 可以知道有没有成功获取锁,而 synchronized 却无法办到。
5、如何保证接口的幂等性 ,除了使用唯一ID还有什么方法?如何保证接口请求的顺序执行?
6、RabbitMq的消息堆积满了,除了增加消费者之外还要怎么处理?
7、nacos 和其他的一些注册中心有什么不一样?
nacos 可以进行 AP 和 CP 的切换;
8、使用 @Transactional 的时候有没有遇到什么问题?怎么解决?@Transactional 的属性都有哪些?
事务失效的情况:
- 使用了 private 去定义方法;
- 发生了自调用,类里面的 a() 直接使用 this 调用类里面的另外一个方法;可以使用 AopContext.currentProxy() 获取代理对象,去调用同类中的方法;
- 异常被吃掉了,事务不会回滚;抛出的异常没有被定义;默认回滚为 RunTimeException 类;
@Transactional 的属性:
- rollbackFor:设置需要进行回滚的异常类数组;
- noRollbackFor:设置不需要进行回滚的异常类数组;
- propagation:设置事务的传播行为;
- isolation:设置底层数据库的事务隔离级别;
- timeout:设置事务的超时秒数;
- readOnly:设置当前事务是否为只读事务,设置为true表示只读,false则表示可读写,默认值为false。
9、Spring的事务实现原理?
(1)在一个方法上加了@Transactional注解后,Spring会基于这个类生成一个代理对象,会将这个代理对象作为bean;
(2)当在使用这个代理对象去调用方法时,如果这个方法上存在@Transactional注解,则利⽤事务管理器创建⼀个数据库连接;
(3)代理逻辑会先修改数据库连接的 autocommit 属性为 false;
(4)再去执行原本的业务逻辑方法;
(5)如果执行业务逻辑方法没有出现异常,那么代理逻辑中就会将事务进行提交,如果执行业务逻辑方法出现了异常,那么则会将事务进行回滚。
10、怎么保证数据库和缓存的双写一致?
延时双删:先删除缓存,再更新数据库,再异步删除缓存中数据;
11、对象头都存储了什么信息?
https://www.cnblogs.com/makai/p/12466541.html
(1)Mark Word
这部分主要用来存储对象自身的运行时数据,如 hashcode、gc分代年龄、锁标志状态、持有锁的线程ID、ptr_to_lock_record:指向栈中锁记录的指针 等。
mark word的位长度为JVM的一个Word大小,也就是说32位JVM的Mark word为32位,64位JVM为64位。
12、Synchronized 锁的升级膨胀?
13、事务的隔离级别是什么?mysql的默认数据库隔离级别是什么?可重复读怎么理解的?可重复读是怎么实现的?
(1)事务隔离级别:读未提交(会产生脏读)、读已提交(会产生不可重复读问题)、可重复读(会产生幻读)、可串行化 ;
(2)默认:可重复读;使用的 MVCC 实现;
14、索引失效的情况都有哪些?索引失效了,会引起表锁吗?创建索引的时候会锁表吗?对一个数据量较大的表创建索引的时候,怎么不让锁表?
(1)索引失效情况:
- like 以 % 开始;
- 复合索引未用左列字段;
- 需要类型转换;
- 索引列使用了函数;
- where 条件中索引列有运算;
- where 条件中使用了 or;
(2)InnoDB的行锁是针对索引加的锁,不是针对记录加的锁。该索引失效,会从行锁升级为表锁;
(3)建立索引不让锁表:???
https://blog.csdn.net/weixin_39522698/article/details/110797185?utm_term=%E5%88%9B%E5%BB%BA%E7%B4%A2%E5%BC%95%E4%BC%9A%E9%94%81%E8%A1%A8%E5%90%97&utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~sobaiduweb~default-2-110797185&spm=3001.4430
15、分布式锁在使用的时候过期时间预估的过期了,怎么处理?Redisson的底层怎么实现的?
16、最近有没有学习到什么值得分享的东西,你们项目的缓存都在什么地方使用?
17、性能优化,在不了解业务的时候怎么去发现问题并优化?业界有什么方法?
18、CMS使用了哪些垃圾回收算法?
19、CAP是什么?为什么不能同时满足?举个例子说明一下。什么是BASE理论?
CAP:
C:(Consistency)表示强⼀致性;
A:(Availability)表示可⽤性;
P:(Partition Tolerance)表示分区容错性;
⼀个分布式系统是必须要保证分区容错性的,在这个前提下,分布式系统要么保证CP,要么保证AP,无法同时保证CAP。
分区容错性表示:⼀个系统虽然是分布式的,但是对外看上去应该是⼀个整体,不能由于分布式系统内部的某个结点挂点,或⽹络出现了故障,⽽导致系统对外出现异常。
强一致性表示:要保证强一致性,则分布式系统中各个结点之间能及时的同步数据,但是在数据同步过程中,是不能对外提供服务的,不然就会造成数据不一致,对不外提供服务又和高可用矛盾,所以强一致性和可高性是不能同时满足的。
可⽤性表示:⼀个分布式系统对外要保证可⽤。
BASE:
由于不能同时满足CAP,所以出现了BASE理论;
(1)BA:Basically Avaiable,表示基本可用,表示可以允许一定程度的不可用;比如由于系统故障,请求时间变长,或者由于系统故障导致部分非核心功能不可用,都是允许的;
(2)S:soft state: 表示分布式系统可以处于一种中间状态,比如数据正在同步;
(3)E:Eventually consistent,表示最终一致性,不要求分布式系统数据实时达到一致,允许在经过一段时间后再达到一致,在达到一致过程中,系统也是可用的;
20、线程池的参数都有什么?线程池是怎么工作的?java中的线程池工具类为什么我们不使用它?
21、为什么使用网关,不要网关可以吗?
22、RabbitMQ的交换机类型都有什么?若交换机没有连接队列,发送消息给这个交换机的时候这个交换机怎么处理?
23、Redis 中的数据过期了,就会马上不存在吗?
24、@ReponseBody 可以加载Get请求的方法上吗?
25、对以后的规划有什么?业务上,技术上的
26、你觉得你们系统比较难的地方是什么?有没有可以再优化的?
27、FactoryBean 和 BeanFactory 有什么区别?在哪些场景可以使用 FactoryBean ?
28、Spring 是怎么整合 Mybatis 的?
29、接口限流,怎么去实现呢?有几种方法?
(1)令牌桶
若限流是10个/s,使用Redis去存储值为0,过期时间为1s;来个请求之后redis中的值就增加1,若 key 还存在且 key 的值超过10,则已经应该要限流了。
(2)滑动时间窗口
(3)漏桶算法
30、I/O 多路复用的优点?
31、CopyOnWriteArrayList的底层原理是怎样的?它和 Vector 有什么不同?
(1)CopyOnWriteArrayList 的内部也使用数组实现的;
add()方法:
- 向 CopyOnWriteArrayList 添加元素的时候,先会使用 ReetrantLock 去加锁;
- 接着将原来的数组拷贝一份出来将它的大小加1,并将需要添加的元素放入进去;
- 写入结束之后,将它的成员变量 arry 指向新数组;
get() 方法:
直接去数组中拿,也不去加锁,性能比较高;
使用场景:CopyOnWriteArrayList允许在写操作时来读取数据,大大提高了读的性能,因此适合读多写少的应用场景,但是CopyOnWriteArrayList会⽐较占内存,同时可能读到的数据不是实时最新的数据,所以不适合实时性要求很高的场景。
(2)Vector
add() 方法 和 get() 方法上都加了 synchronized;
32、ConcurrentHashMap的扩容机制?
1.7版本:
(1)1.7版本的ConcurrentHashMap是基于Segment分段锁实现的,Segment对象内部也有一个数组,内部也可以存储链表;
(2)每个Segment内部会进⾏扩容,和HashMap的扩容逻辑类似;
(3)先⽣成新的数组,然后转移元素到新数组中;
(4)扩容的判断也是每个Segment内部单独判断的,判断是否超过阈值;
1.8版本:
(1);
(2)当某个线程进⾏put时,如果发现ConcurrentHashMap正在进⾏扩容那么该线程⼀起进⾏扩容;
33、为什么说NIO是非阻塞的?
非阻塞的意思就是调用是实时返回的不会导致当前线程被挂起(阻塞),比如对一个通道进行read操作nio下如果通道中没有可读数据会直接返回只不过返回值是0,而BIO(阻塞IO)下则会等到通道中有数据才会返回;
但是 IO 中有个特例就是File IO,因为文件是确定的 而且文件句柄在操作系统中是不能同时被多个线程持有的(多个线程不能同时读写同一个文件,虽然java中有些API声称可以同时操作 只不过是底层实现每次操作都获取一次句柄释放一次句柄而已),所以呢File IO你可以理解为都是非阻塞的,因为read时候文件里面有数据就读数据返回 没数据就是EOF。
34、nginx的动静分离怎么配置?
35、Zuul 和 GateWay 有什么不一样?
36、MySQL的索引怎么理解?为什么使用B+树索引不使用哈希索引?
哈希索引对于排序,范围查询检索就没有什么办法了。
37、CDN是什么?与DNS有什么关系?
38、nacos的配置中心的原理是什么?修改配置中心之后服务是怎么获取配置的?