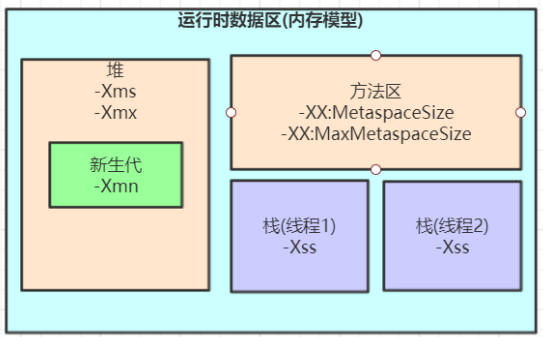
一、JVM整体结构和内存模型

上图示例中的代码:
public class Math {
public static int initData = 666;
public static User user = new User();
public int compute() {
int a = 1;
int b = 2;
int c = (a + b) * 10;
return c;
}
public static void main(String[] args) {
Math math = new Math();
math.compute();
System.out.println("test");
}
}
通过类加载器将类(类元信息)加载到方法区中,compute() 方法也被加载到方法区中;java代码在执行 math.compute() 的时候,通过 math 对象的对象头中的头指针找到存储在方法区中的 compute() 方法的指令码的入口地址,然后将这个入口地址放到栈中的动态链接内存区域中;
(1)类装载子系统,将class文件经过加载、验证、准备、解析、初始化后生产类元信息放入到方法区中(类装载子系统主要将类装载到方法区);常量池是在方法区中的;
(2)栈里面的变量引用指向堆中的对象;基本类型的局部变量放到对应的栈中,对象放到堆中;
(3)对象(在堆中)的对象头中有一个指针,指向的是这个对象所属类的类元信息(方法区中);
(4)静态变量是存在方法区中的,其引用指向堆中的对象;
方法区:线程共享的,通常用来储存装载的类的元结构信息。垃圾回收很少发生;
比如:运行时常量池 + 静态变量 + 常量 + 字段 + 方法字节码 + 在类/实例/接口初始化用到的特殊方法等。方法区是一个抽象的概念,它的实现是永久区(Java7) 或 元空间(Java8,使用的是物理内存,不是JVM的内存);
本地方法栈:线程私有的,调用本地方法的时候分配的内存;
程序计数器:线程私有的,用来存储指向下一条指令的地址,由执行引擎读取下一条指令;
栈:线程私有的,主管Java程序的运行,栈是在线程创建的时候创建;存放基本类型的变量、实例方法、引用类型变量都是在函数的栈内存中分配
二、JVM内存参数设置
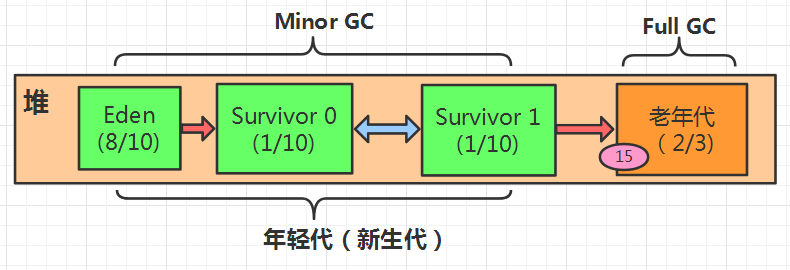
JVM调优:尽可能的让对象不要放入到老年代去,那么就要减少 Minor GC 垃圾回收的次数,则新生代的内存大小要设置的大点。
minor GC:回收未有引用的垃圾对象;
(1) 当new 一个对象,该对象被放入伊甸区(Eden),创建的对象越来越多,伊甸区(Eden)快满的时候启动一种轻垃圾回收(Minor GC),未被回收的对象被放入幸存0区(Survivor 0),Eden被清空;
(2)继续 new 对象,当伊甸园区再次快放满的时候,启动垃圾回收机制(Minor GC)去清理 伊甸园区 和 幸存0区,将这两个区域的垃圾对象回收完之后,将它们未被回收的对象一起放入到幸存1区(Survivor 1),Survivor 0 和 Eden 被清空;
(3)继续会 new 对象,当伊甸园区再次快满的时候,启动垃圾回收机制(Minor GC)去清理 伊甸园区 和 幸存1区,将这两个区域的垃圾对象回收完之后,将它们未被回收的对象一起放入到幸存0区(Survivor 0),Survivor 1 和 Eden 被清空;
(4)如此循环往复。对象的对象头中有个叫分代年龄的存储信息(默认是15),当这个对象的分代年龄达到了15了,还没有被垃圾机制回收,则会将这些对象放入到老年代;幸存区放慢也会进行垃圾回收然后放入到老年代;
(5)当老年代快满的时候触发一个重量级的GC(Full GC),清理未被引用的任何对象,清理之后还是无法再保存对象,就会产生OOM异常(OutOfMemoryError)。
不管哪种垃圾回收机制都会去调用 STW,去停止所有线程的继续执行;
栈内存溢出(StackOverflowError)示例
public class StackOverflowTest {
static int count = 0;
static void redo() {
count++;
redo();
}
public static void main(String[] args) {
try {
redo();
} catch (Throwable t) {
t.printStackTrace();
System.out.println(count);
}
}
}
运行结果:
java.lang.StackOverflowError
at com.tuling.jvm.StackOverflowTest.redo(StackOverflowTest.java:12)
at com.tuling.jvm.StackOverflowTest.redo(StackOverflowTest.java:13)
at com.tuling.jvm.StackOverflowTest.redo(StackOverflowTest.java:13)
结论:
-Xss设置越小count值越小,说明一个线程栈里能分配的栈帧就越少,但是对JVM整体来说能开启的线程数会更多;
Spring Boot程序的JVM参数设置格式(Tomcat启动直接加在bin目录下catalina.sh文件里)
java ‐Xms2048M ‐Xmx2048M ‐Xmn1024M ‐Xss512K ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐jar microservice‐eureka‐server.jar
三、逃逸分析
JVM的运行模式有三种:
- 解释模式 ( Interpreted Mode):只使用解释器(-Xint强制JVM使用解释模式),执行一行JVM字节码就编译一行为机器码;
- 编译模式 (Compiled Mode):只使用编译器(-XcompJVM使用编译模式),先将所有JVM字节码一次编译为机器码,然后一次性执行所有机器码;
- 混合模式(Mixed Mode):依然使用解释模式执行代码,但是对于一些 "热点" 代码采用编译模式执行,JVM一般采用混合模式执行代码;
解释模式启动快,对于只需要执行部分代码,并且大多数代码只会执行一次的情况比较适合;编译模式启动慢,但是后期执行速度快,而且比较占用内存,因为机器码的数量至少是JVM字节码的十倍以上,这种模式适合代码可能会被反复执行的场景;混合模式是JVM默认采用的执行代码方式,一开始还是解释执行,但是对于少部分 “热点 ”代码会采用编译模式执行,这些热点代码对应的机器码会被缓存起来,下次再执行无需再编译,这就是我们常见的JIT(Just In Time Compiler)即时编译技术。
在即时编译过程中JVM可能会对我们的代码最一些优化,比如对象逃逸分析等。
对象逃逸分析:就是分析对象动态作用域,当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中;
public User test1() {
User user = new User();
user.setId(1);
user.setName("zhuge");
//TODO 保存到数据库
return user;
}
public void test2() {
User user = new User();
user.setId(1);
user.setName("zhuge");
//TODO 保存到数据库
}
test1方法中的user对象被返回了,这个对象的作用域范围不确定,test2方法中的user对象我们可以确定当方法结束这个对象就可以认为是无效对象了,对于这样的对象我们其实可以将其分配的栈内存里,让其在方法结束时跟随栈内存一起被回收掉。
JVM对于这种情况可以通过开启逃逸分析参数(-XX:+DoEscapeAnalysis)来优化对象内存分配位置,JDK7之后默认开启逃逸分析,如果要关闭使用参数(-XX:-DoEscapeAnalysis)。