1.在python中往kakfa写数据和读取数据,使用的是python-kafka库
2.消费者需持续写入数据,因groupid存在偏移量,才能看看到数据。
3.安装库的命令为pip install python-kafka -i https://pypi.douban.com/simple
4.其中返回的message为一个生成器,其中元素的type为<class 'kafka.consumer.fetcher.ConsumerRecord'>
代码如下
#!/usr/bin/env python # -*- coding: utf-8 -*- from kafka import KafkaProducer from kafka import KafkaConsumer from kafka.errors import KafkaError import json class Kafka_producer(): ''' 使用kafka的生产模块 ''' def __init__(self, kafkahost,kafkaport, kafkatopic): self.kafkaHost = kafkahost self.kafkaPort = kafkaport self.kafkatopic = kafkatopic self.producer = KafkaProducer(bootstrap_servers = '{kafka_host}:{kafka_port}'.format( kafka_host=self.kafkaHost, kafka_port=self.kafkaPort )) def sendjsondata(self, params): try: parmas_message = json.dumps(params) producer = self.producer producer.send(self.kafkatopic, parmas_message.encode('utf-8')) producer.flush() except KafkaError as e: print e class Kafka_consumer(): ''' 使用Kafka—python的消费模块 ''' def __init__(self, kafkahost, kafkaport, kafkatopic, groupid): self.kafkaHost = kafkahost self.kafkaPort = kafkaport self.kafkatopic = kafkatopic self.groupid = groupid self.consumer = KafkaConsumer(self.kafkatopic, group_id = self.groupid, bootstrap_servers = '{kafka_host}:{kafka_port}'.format( kafka_host=self.kafkaHost, kafka_port=self.kafkaPort )) def consume_data(self): try: for message in self.consumer: # print json.loads(message.value) yield message except KeyboardInterrupt, e: print e def main(): ''' 测试consumer和producer :return: ''' ##测试生产模块 #producer = Kafka_producer("127.0.0.1", 9092, "ranktest") #for id in range(10): # params = '{abetst}:{null}---'+str(i) # producer.sendjsondata(params) ##测试消费模块 #消费模块的返回格式为ConsumerRecord(topic=u'ranktest', partition=0, offset=202, timestamp=None, #\timestamp_type=None, key=None, value='"{abetst}:{null}---0"', checksum=-1868164195, #\serialized_key_size=-1, serialized_value_size=21) consumer = Kafka_consumer('127.0.0.1', 9092, "ranktest", 'test-python-ranktest') message = consumer.consume_data() for i in message: print i.value if __name__ == '__main__': main()
消费结果为:
i.value:
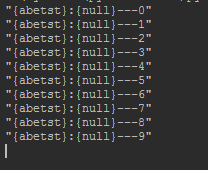
i.offset:
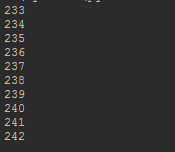
作 者:小闪电
出处:http://www.cnblogs.com/yueyanyu/
本文版权归作者和博客园共有,欢迎转载、交流,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。如果觉得本文对您有益,欢迎点赞、欢迎探讨。本博客来源于互联网的资源,若侵犯到您的权利,请联系博主予以删除。