use an algorithm to separate the letters from sentences. ( kind of classifier)
the architecture of neural networks:
input layer; hidden layer; output layer
different kinds of neural networks:
feedforward neural networks; recurrent neural networks; and so on
Usually, we use optimizer ( e.g. SGD Stochastic Gradient Descent in this chapter) to optimize/find a solution. As we all known, NNs is supervised learning. So we need to learn from the training dataset first, the we get our model from the data, then, test our result on the test dataset in the end.
traning dataset: MNIST data ( Modified NIST) comes in two parts: the first part contains 6000 images to be used as training data; the second part of the MNIST data set is 10000 images to be used as testing data.
notation x to denote a training input, it'll be regarded as a 28*28 = 784 dimensional vector as the image vector. And the corresponding output y = y(x) is a 10-dimensional vector. The element in y is either 0 or 1, and there will be only 1 in the vector y. ( e.g. if the input x is 6, if we recongnize the x correctly, then, the output y will be (0,0,0,0,0,0,1,0,0,0)T ).
for each neuron, there are two parameters--weight and bias. Wj,kl is weight of the lth connection the kth neuron ( right side) to the jth neron ( left side ). So after the formation the input x is z=w⋅x+b. Then, use the activation function in this chapter is sigmoid function to compute each output f(z) to decide which neuron to be fired.
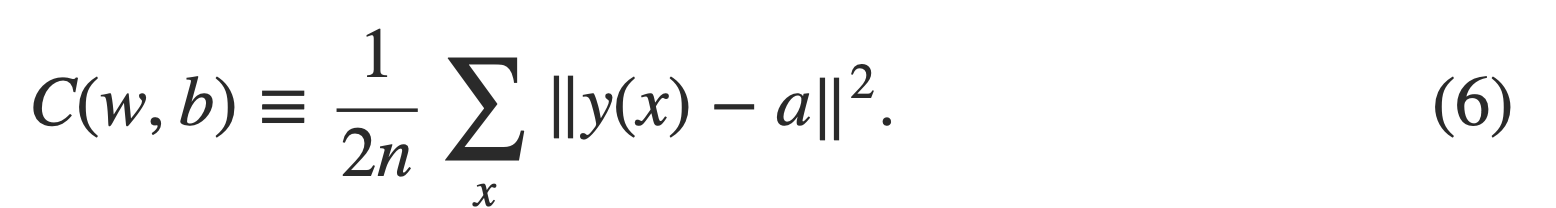
w denotes the collection of all weights in the network, b all the biases, n is the total number of training inputs, a is the vector of outputs from the network when x is input, and the sum is over all training inputs, x.
Why not try to maximize that number directly, rather than minimizing a proxy measure like the quadratic cost? The problem with that is that the number of images correctly classified is not a smooth function of the weights and biases in the network. For the most part, making small changes to the weights and biases won't cause any change at all in the number of training images classified correctly. That makes it difficult to figure out how to change the weights and biases to get improved performance. If we instead use a smooth cost function like the quadratic cost it turns out to be easy to figure out how to make small changes in the weights and biases so as to get an improvement in the cost.
The cost function C changes as follows, then, we need to choose Δv1, Δv2 to make (7) negative.
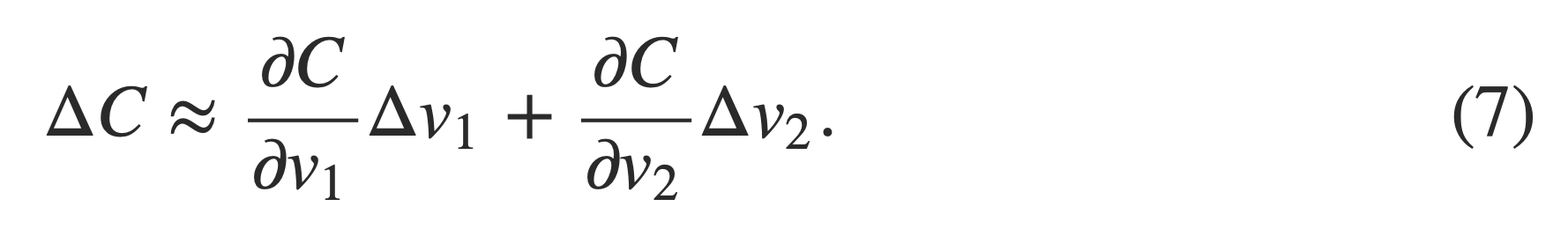
An idea called stochastic gradient descent can be used to speed up learning. The idea is to estimate the gradient ∇Cby computing ∇Cx for a small sample of randomly chosen training inputs. By averaging over this small sample it turns out that we can quickly get a good estimate of the true gradient ∇C∇C, and this helps speed up gradient descent, and thus learning.
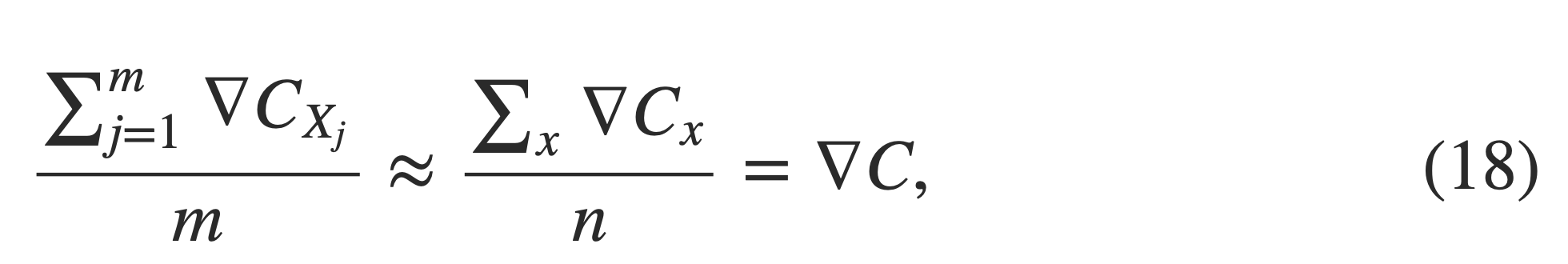
Then stochastic gradient descent works by picking out a randomly chosen mini-batch of training inputs, and training with those, ( In other words, use backpropagation to update w,b in each mini-batch) Then we get the final set of weights and biases of the neural network as the result
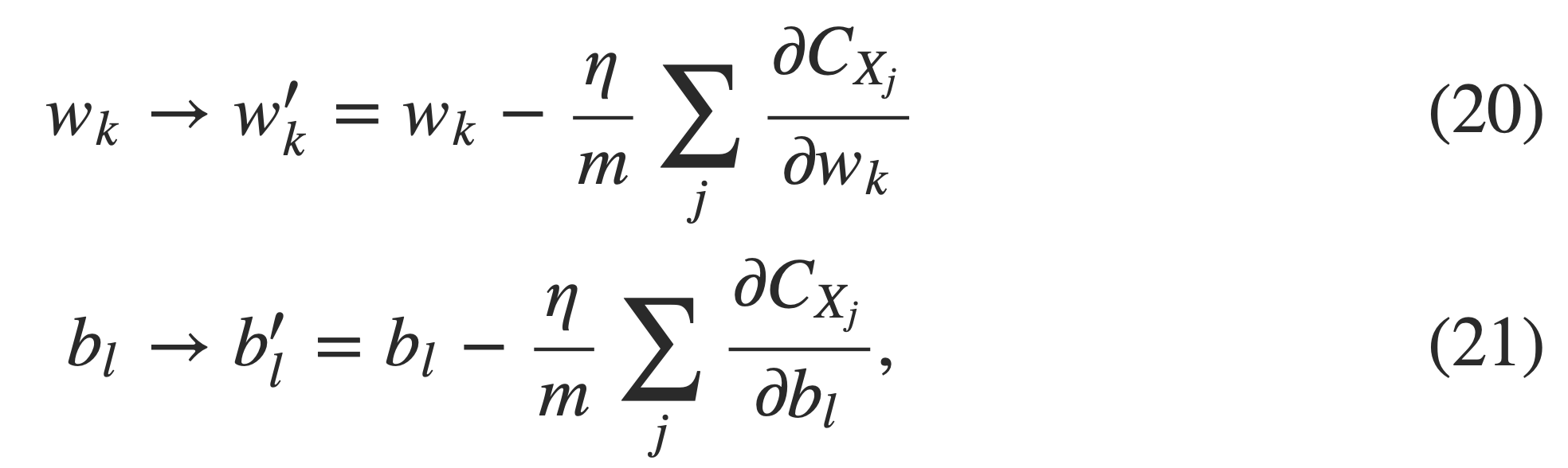
1 # %load network.py 2 3 """ 4 network.py 5 ~~~~~~~~~~ 6 IT WORKS 7 8 A module to implement the stochastic gradient descent learning 9 algorithm for a feedforward neural network. Gradients are calculated 10 using backpropagation. Note that I have focused on making the code 11 simple, easily readable, and easily modifiable. It is not optimized, 12 and omits many desirable features. 13 """ 14 15 #### Libraries 16 # Standard library 17 import random 18 19 # Third-party libraries 20 import numpy as np 21 22 class Network(object): 23 24 def __init__(self, sizes): 25 """The list ``sizes`` contains the number of neurons in the 26 respective layers of the network. For example, if the list 27 was [2, 3, 1] then it would be a three-layer network, with the 28 first layer containing 2 neurons, the second layer 3 neurons, 29 and the third layer 1 neuron. The biases and weights for the 30 network are initialized randomly, using a Gaussian 31 distribution with mean 0, and variance 1. Note that the first 32 layer is assumed to be an input layer, and by convention we 33 won't set any biases for those neurons, since biases are only 34 ever used in computing the outputs from later layers.""" 35 self.num_layers = len(sizes) 36 self.sizes = sizes 37 self.biases = [np.random.randn(y, 1) for y in sizes[1:]] 38 self.weights = [np.random.randn(y, x) 39 for x, y in zip(sizes[:-1], sizes[1:])] 40 41 def feedforward(self, a): 42 """Return the output of the network if ``a`` is input.""" 43 for b, w in zip(self.biases, self.weights): 44 a = sigmoid(np.dot(w, a)+b) 45 return a 46 47 def SGD(self, training_data, epochs, mini_batch_size, eta, 48 test_data=None): 49 """Train the neural network using mini-batch stochastic 50 gradient descent. The ``training_data`` is a list of tuples 51 ``(x, y)`` representing the training inputs and the desired 52 outputs. The other non-optional parameters are 53 self-explanatory. If ``test_data`` is provided then the 54 network will be evaluated against the test data after each 55 epoch, and partial progress printed out. This is useful for 56 tracking progress, but slows things down substantially.""" 57 58 training_data = list(training_data) 59 n = len(training_data) 60 61 if test_data: 62 test_data = list(test_data) 63 n_test = len(test_data) 64 65 for j in range(epochs): 66 random.shuffle(training_data) 67 mini_batches = [ 68 training_data[k:k+mini_batch_size] 69 for k in range(0, n, mini_batch_size)] 70 for mini_batch in mini_batches: 71 self.update_mini_batch(mini_batch, eta) 72 if test_data: 73 print("Epoch {} : {} / {}".format(j,self.evaluate(test_data),n_test)); 74 else: 75 print("Epoch {} complete".format(j)) 76 77 def update_mini_batch(self, mini_batch, eta): 78 """Update the network's weights and biases by applying 79 gradient descent using backpropagation to a single mini batch. 80 The ``mini_batch`` is a list of tuples ``(x, y)``, and ``eta`` 81 is the learning rate.""" 82 nabla_b = [np.zeros(b.shape) for b in self.biases] 83 nabla_w = [np.zeros(w.shape) for w in self.weights] 84 for x, y in mini_batch: 85 delta_nabla_b, delta_nabla_w = self.backprop(x, y) 86 nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)] 87 nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)] 88 self.weights = [w-(eta/len(mini_batch))*nw 89 for w, nw in zip(self.weights, nabla_w)] 90 self.biases = [b-(eta/len(mini_batch))*nb 91 for b, nb in zip(self.biases, nabla_b)] 92 93 def backprop(self, x, y): 94 """Return a tuple ``(nabla_b, nabla_w)`` representing the 95 gradient for the cost function C_x. ``nabla_b`` and 96 ``nabla_w`` are layer-by-layer lists of numpy arrays, similar 97 to ``self.biases`` and ``self.weights``.""" 98 nabla_b = [np.zeros(b.shape) for b in self.biases] 99 nabla_w = [np.zeros(w.shape) for w in self.weights] 100 # feedforward 101 activation = x 102 activations = [x] # list to store all the activations, layer by layer 103 zs = [] # list to store all the z vectors, layer by layer 104 for b, w in zip(self.biases, self.weights): 105 z = np.dot(w, activation)+b 106 zs.append(z) 107 activation = sigmoid(z) 108 activations.append(activation) 109 # backward pass 110 delta = self.cost_derivative(activations[-1], y) * 111 sigmoid_prime(zs[-1]) 112 nabla_b[-1] = delta 113 nabla_w[-1] = np.dot(delta, activations[-2].transpose()) 114 # Note that the variable l in the loop below is used a little 115 # differently to the notation in Chapter 2 of the book. Here, 116 # l = 1 means the last layer of neurons, l = 2 is the 117 # second-last layer, and so on. It's a renumbering of the 118 # scheme in the book, used here to take advantage of the fact 119 # that Python can use negative indices in lists. 120 for l in range(2, self.num_layers): 121 z = zs[-l] 122 sp = sigmoid_prime(z) 123 delta = np.dot(self.weights[-l+1].transpose(), delta) * sp 124 nabla_b[-l] = delta 125 nabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) 126 return (nabla_b, nabla_w) 127 128 def evaluate(self, test_data): 129 """Return the number of test inputs for which the neural 130 network outputs the correct result. Note that the neural 131 network's output is assumed to be the index of whichever 132 neuron in the final layer has the highest activation.""" 133 test_results = [(np.argmax(self.feedforward(x)), y) 134 for (x, y) in test_data] 135 return sum(int(x == y) for (x, y) in test_results) 136 137 def cost_derivative(self, output_activations, y): 138 """Return the vector of partial derivatives partial C_x / 139 partial a for the output activations.""" 140 return (output_activations-y) 141 142 #### Miscellaneous functions 143 def sigmoid(z): 144 """The sigmoid function.""" 145 return 1.0/(1.0+np.exp(-z)) 146 147 def sigmoid_prime(z): 148 """Derivative of the sigmoid function.""" 149 return sigmoid(z)*(1-sigmoid(z))