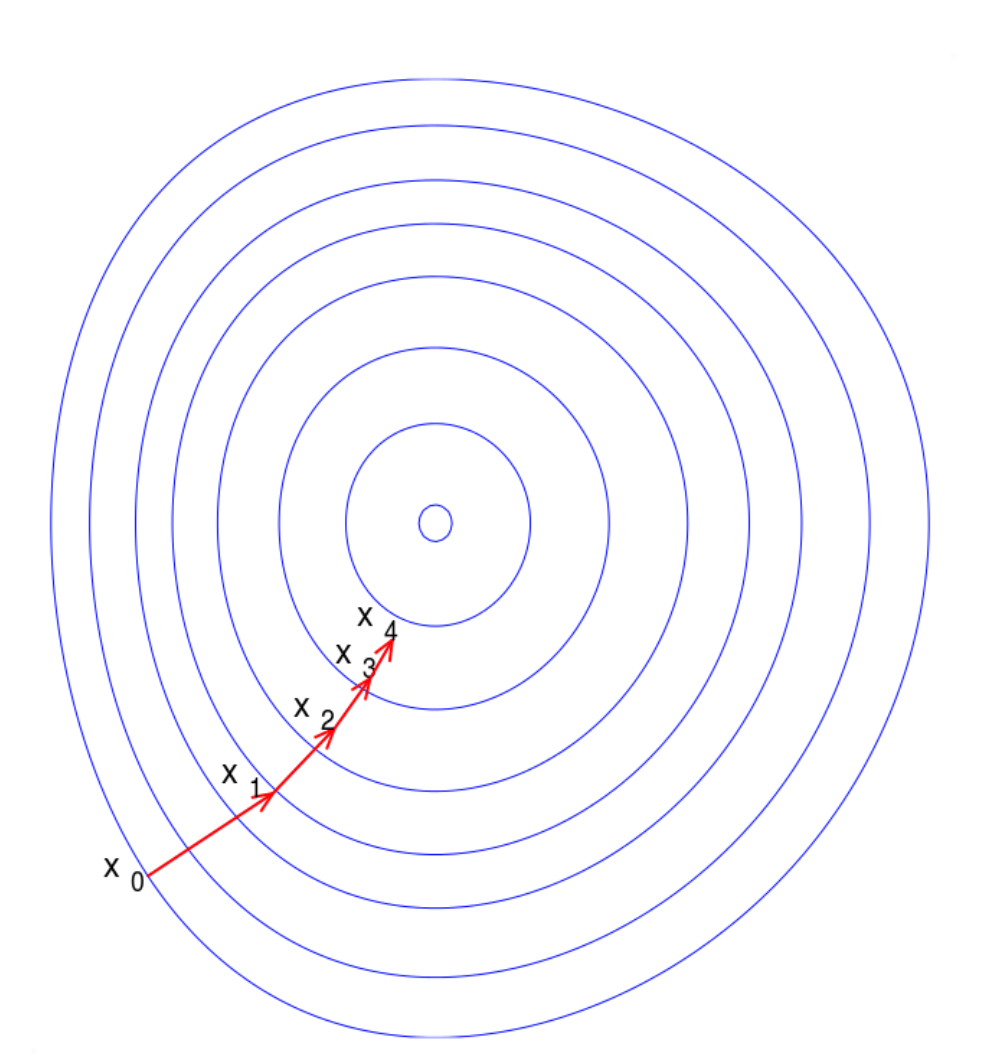
Gradient descent is a first-order iterative optimization algorithm for finding a local minimum of a differentiable function. To find a local minimum of a function using gradient descent, we take steps proportional to the negative of the gradient (or approximate gradient) of the function at the current point. But if we instead take steps proportional to the positive of the gradient, we approach a local maximum of that function; the procedure is then known as gradient ascent. Gradient descent is generally attributed to Cauchy, who first suggested it in 1847,[1] but its convergence properties for non-linear optimization problems were first studied by Haskell Curry in 1944.[2]
梯度下降是寻找可微函数的局部最小值的先序迭代优化算法。为了找到一个局部最小值,我们采用步长来成比例地从当前点沿着函数的负梯度或负梯度的大致方向(来接近最小值)。但是如果我们如果采用正梯度,我们会找到函数的局部最大值;这个过程称为梯度下降。总的来说,梯度下降是高斯在1847年最早提出的,但Haskell Curry在1944年最早研究了它的非线性优化问题的收敛特性。
Gradient descent is based on the observation that if the multi-variable function
is defined and differentiable in a neighborhood of a point
, then
at
.
梯度下降给予对于多变量函数F(x)的观察,F(x)是定义在点a临域可导的函数,F(x)从a出发沿着a的负梯度方向
It follows that, iffor
small enough, then
.
每次迭代
In other words, the termis subtracted from
for a local minimum of
such that

换种说法,从a点(处的值)减去
We have a monotonic sequence
so hopefully the sequence
converges to the desired local minimum. Note that the value of the step size
is allowed to change at every iteration. With certain assumptions on the function
Lipschitz) and particular choices of
![{displaystyle gamma _{n}={frac {left|left(mathbf {x} _{n}-mathbf {x} _{n-1}
ight)^{T}left[
abla F(mathbf {x} _{n})-
abla F(mathbf {x} _{n-1})
ight]
ight|}{left|
abla F(mathbf {x} _{n})-
abla F(mathbf {x} _{n-1})
ight|^{2}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a4bd0be3d2e50d47f18b4aeae8643e00ff7dd2e9)
我们获得了单调序列, 
convergence to a local minimum can be guaranteed. When the function
Solution of a linear system
Gradient descent can be used to solve a system of linear equations, reformulated as a quadratic minimization problem, e.g., using linear least squares. The solution of
in the sense of linear least squares is defined as minimizing the function

- 线性空间的解
- 梯度下降可以解线性方程组,用线性最小二乘重新定义求二次曲线最小值的问题。
的解在线性最小二乘可定义为最小化函数
-
In traditional linear least squares for real
and
the Euclidean norm is used, in which case
In this case, the line search minimization, finding the locally optimal step size
在传统的线性最小二乘中,对于实值的向量矩阵A和b使用了欧几里得范数,如在对向量矩阵构成的函数求导的场合
在线性搜索最小值的情况,每一次迭代可分析得到一个局部最优步长
The algorithm is rarely used for solving linear equations, with the conjugate gradient method being one of the most popular alternatives. The number of gradient descent iterations is commonly proportional to the spectral condition number
of the system matrix
), while the convergence of conjugate gradient method is typically determined by a square root of the condition number, i.e., is much faster. Both methods can benefit from preconditioning, where gradient descent may require less assumptions on the preconditioner.[7]
算法很少用来解决线性方程,因为共轭梯度算法*是一个很火的选项。梯度下降的迭代数是与系统矩阵A成比例的光谱条件数
Solution of a non-linear system
Gradient descent can also be used to solve a system of nonlinear equations. Below is an example that shows how to use the gradient descent to solve for three unknown variables, x1, x2, and x3. This example shows one iteration of the gradient descent.
梯度下降也用来解决非线性问题。这里有一个相关的例子,用梯度下降法求解三个未知数 x1, x2, 和x3。这个例子展示了梯度下降的一次迭代。
Consider the nonlinear system of equations
Let us introduce the associated function
where
One might now define the objective function
which we will attempt to minimize.
F(x)是我们要进行梯度下降求最小值的方程
As an initial guess, let us use
We know that
where the Jacobian matrix
is given by
初始猜测x(0)为3*1的零矩阵,通过递归下降的迭代转移公式,推导得到x(1),其中JG(x)为矩阵G(x)对x求导所得。(由前文可得,gama由经验值设定)
We calculate:
Thus
and
Now, a suitable
must be found such that
This can be done with any of a variety of line search algorithms. One might also simply guess
which gives
Evaluating the objective function at this value, yields
The decrease from
to the next step's value of
第一次迭代不同gama值的详细过程



![{displaystyle F(mathbf {x} )={frac {1}{2}}G^{mathrm {T} }(mathbf {x} )G(mathbf {x} )={frac {1}{2}}left[left(3x_{1}-cos(x_{2}x_{3})-{frac {3}{2}}
ight)^{2}+left(4x_{1}^{2}-625x_{2}^{2}+2x_{2}-1
ight)^{2}+left(exp(-x_{1}x_{2})+20x_{3}+{frac {10pi -3}{3}}
ight)^{2}
ight],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/31ebfa155b6d0cdef7771ecacf28d5179dd9b111)







