- Logistic Regression
- We can approach the classfication problem ignoring the fact that y is discrete-valued, and use old linear regression algorithm to try to predict y given x.
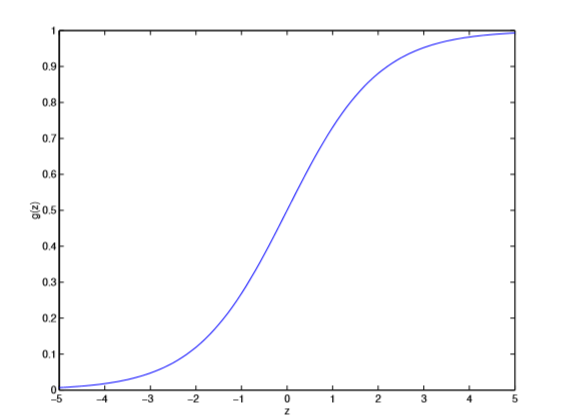
- Intuitively, it also doesn't make sense for hθ(x) to take values larger than 1 or smaller than 0
- To fix this, let's change the form for hypotheses hθ(x), it's called logistic function or sigmoid function
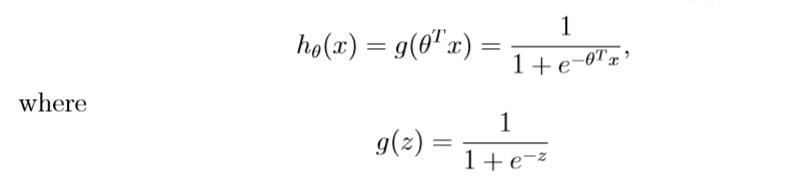
-
- a useful property of the derivetive of the sigmoid function, which is written as g'
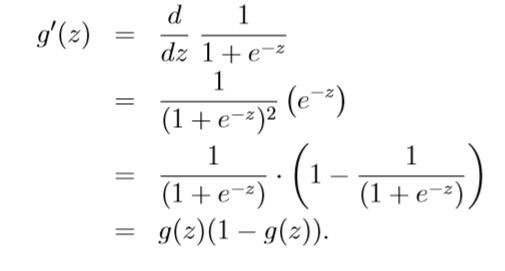
- To fit θ for logisitic regerssion model, let's endow our classification model with a set of probabilistic assumptions, and then fit the parameters via maximum likelihood
- assume that
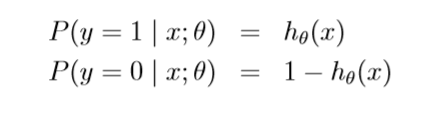
it can be written more compactly as
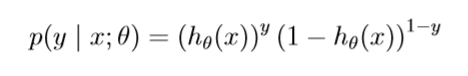
-
Assuming that the n training examples wear generated independently, we can the write down th likelihood function of the parameters as
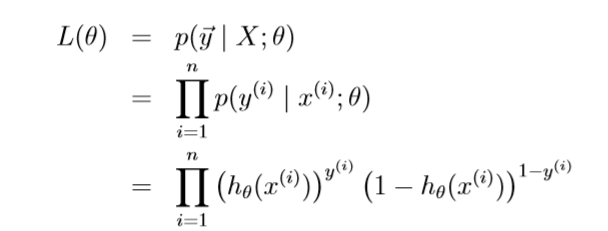
and log likelihood function

-
To get the maximum of l(θ), similar to our derivation in the case of linear regression, we can use gradient ascent. Written in vectorial notation, our updates will therefore be given by
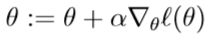 , take derivatives to derive the stochastic gradient ascent rule:
, take derivatives to derive the stochastic gradient ascent rule: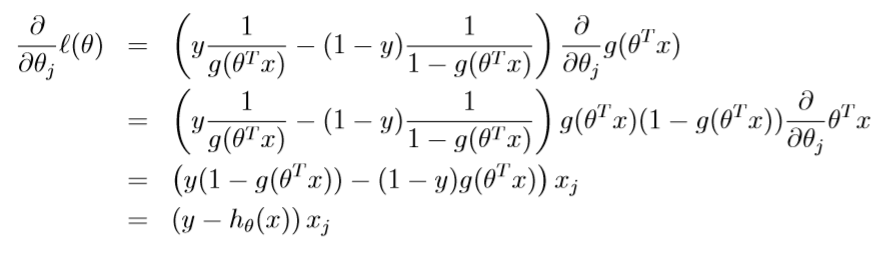
-
This therefore gives us the stochastic gradient ascent rule

- assume that
- a useful property of the derivetive of the sigmoid function, which is written as g'