一、RabbitMQ的原理图:
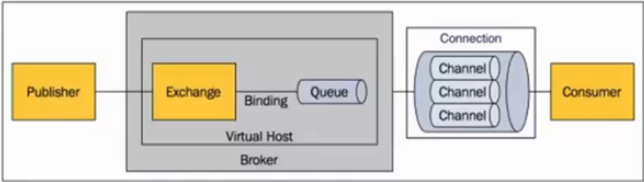
二、概念讲解:
|
1.Message |
|
消息。消息是不具名称的,它由消息头消息体组成。消息体是不透明的,而消息头则由一系列可选属性组成,这些属性包括:routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出消息可能持久性存储)等。 |
|
2.Publisher |
|
消息的生产者。也是一个向交换器发布消息的客户端应用程序。 |
|
3.Consumer |
|
消息的消费者。表示一个从消息队列中取得消息的客户端应用程序。 |
|
4.Exchange |
|
交换器。用来接收生产者发送的消息并将这些消息路由给服务器中的队列。 direct(发布与订阅 完全匹配) fanout(广播) topic(主题,规则匹配) |
|
5.Binding |
|
绑定。用于消息队列和交换器之间的关联。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。 |
|
6.Queue |
|
消息队列。用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者链接到这个队列将其取走。 |
|
7.Routing-key |
|
路由键。RabbitMQ决定消息该投递到哪个队列的规则。 队列通过路由键绑定到交换器。 消息发送到MQ服务器时,消息将拥有一个路由键,即便是空的,RabbitMQ也会将其和绑定使用的路由键进行匹配。 如果相匹配,消息将会投递到该队列。 如果不匹配,消息将会进入黑洞。 |
|
8.Connection |
|
链接。指rabbit服务器和服务建立的TCP链接。 |
|
9.Channel |
|
信道。 Channel中文叫做信道,是TCP里面的虚拟链接。例如:电缆相当于TCP,信道是一个独立光纤束,一条TCP连接上创建多条信道是没有问题的。 TCP一旦打开,就会创建AMQP信道。 无论是发布消息、接收消息、订阅队列,这些动作都是通过信道完成的。 |
|
10.Virtual Host |
|
虚拟主机。表示一批交换器,消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。每个vhost本质上就是一个mini版的RabbitMQ服务器,拥有自己的队列、交换器、绑定和权限机制。vhost是AMQP概念的基础,必须在链接时指定,RabbitMQ默认的vhost是/ |
|
11.Borker |
|
表示消息队列服务器实体。就是RabbitMQ整体应用。 |
|
12.交换器和队列的关系 |
|
交换器是通过路由键和队列绑定在一起的,如果消息拥有的路由键跟队列和交换器的路由键匹配,那么消息就会被路由到该绑定的队列中。 也就是说,消息到队列的过程中,消息首先会经过交换器,接下来交换器在通过路由键匹配分发消息到具体的队列中。 路由键可以理解为匹配的规则。 |
|
13.RabbitMQ为什么需要信道?为什么不是TCP直接通信? |
|
TCP的创建和销毁开销特别大。创建需要3次握手,销毁需要4次分手。 如果不用信道,那应用程序就会以TCP链接Rabbit,高峰时每秒成千上万条链接会造成资源巨大的浪费,而且操作系统每秒处理TCP链接数也是有限制的,必定造成性能瓶颈。 信道的原理是一条线程一条通道,多条线程多条通道同用一条TCP链接。一条TCP链接可以容纳无限的信道,即使每秒成千上万的请求也不会成为性能的瓶颈。 |
三、RabbitMQ的应用
示例代码:https://github.com/yucong/rabbitmq-learning
3.1 Direct交换器
是一种点对点,实现发布/订阅标准的交换器。Producer发送消息到RabbitMQ中,MQ中的Direct交换器接受到消息后,会根据Routing Key来决定这个消息要发送到哪一个队列中。Consumer则负责注册一个队列监听器,来监听队列的状态,当队列状态发生变化时,消费消息。注册队列监听需要提供交换器信息,队列信息和路由键信息。
这种交换器通常用于点对点消息传输的业务模型中。如电子邮箱。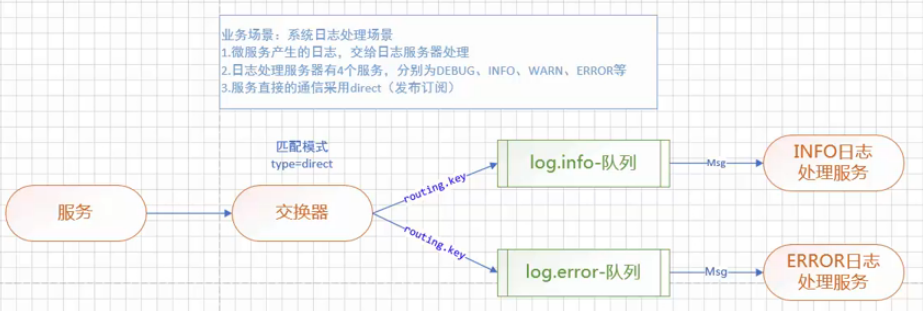
producer全局配置文件
|
spring.application.name=direct-producer # 必要配置 # 配置rabbitmq链接相关信息。key都是固定的。是springboot要求的。 # rabbitmq安装位置 spring.rabbitmq.host=192.168.1.122 # rabbitmq的端口 spring.rabbitmq.port=5672 # rabbitmq的用户名 spring.rabbitmq.username=test # rabbitmq的用户密码 spring.rabbitmq.password=123456 # 可选配置 # 配置producer中操作的Queue和Exchange相关信息的。key是自定义的。为了避免硬编码。 # exchange的命名。交换器名称可以随意定义。 mq.config.exchange=log.direct # 路由键, 是定义某一个路由键。 info级别日志使用的queue的路由键。 mq.config.queue.info.routing.key=log.info.routing.key # 路由键,error级别日志使用的queue的路由键。 mq.config.queue.error.routing.key=log.error.routing.key |
Consumer全局配置
|
spring.application.name=direct-consumer server.port=8081 spring.rabbitmq.host=192.168.1.122 spring.rabbitmq.port=5672 spring.rabbitmq.username=test spring.rabbitmq.password=123456 # 自定义配置。 配置交换器exchange、路由键routing-key、队列名称 queue name # 交换器名称 mq.config.exchange=log.direct # info级别queue的名称 mq.config.queue.info=log.info # info级别的路由键 mq.config.queue.info.routing.key=log.info.routing.key # error级别queue的名称 mq.config.queue.error=log.error # error级别的路由键 mq.config.queue.error.routing.key=log.error.routing.key |
3.2 Topic交换器
主题交换器,也称为规则匹配交换器。是通过自定义的模糊匹配规则来决定消息存储在哪些队列中。当Producer发送消息到RabbitMQ中时,MQ中的交换器会根据路由键来决定消息应该发送到哪些队列中。Consumer同样是注册一个监听器到队列,监听队列状态,当队列状态发生变化时,消费消息。注册监听器需要提供交换器信息,队列信息和路由键信息。
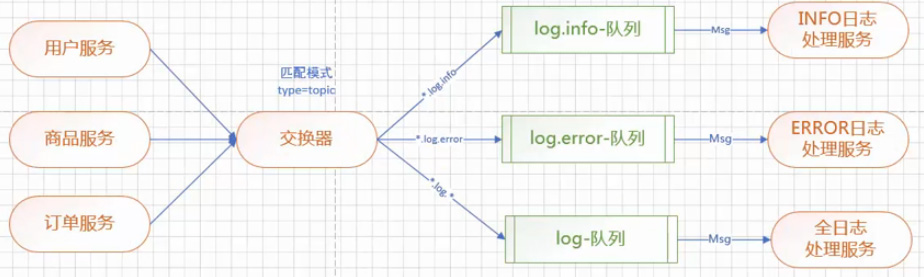
3.3 Fanout交换器
广播交换器。这种交换器会将接收到的消息发送给绑定的所有队列中。当Producer发送消息到RabbitMQ时,交换器会将消息发送到已绑定的所有队列中,这个过程交换器不会尝试匹配路由键,所以消息中不需要提供路由键信息。Consumer仍旧注册监听器到队列,监听队列状态,当队列状态发生变化,消费消息。注册监听器需要提供交换器信息和队列信息。
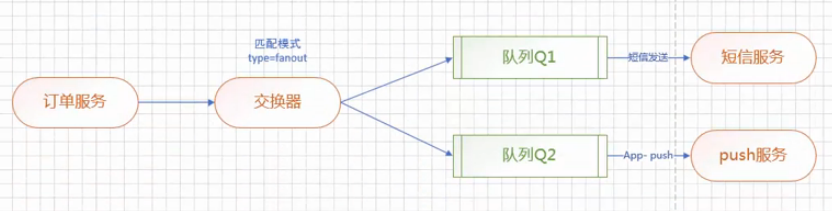
四、RabbitMQ消息可靠性处理
前面内容,如果consumer未启动,而producer发送了消息。则消息会丢失。
如果consumer先启动,创建queue后,producer发送消息可以正常消费。那么当所有的consumer宕机的时候,queue会auto-delete,消息仍旧会丢失。
这种情况,消息不可靠。有丢失的可能。
Rabbitmq的消息可靠性处理,分为两部分。
1 - 消息不丢失。当consumer全部宕机后,消息不能丢失。 持久化解决
2 - 消息不会错误消费。当consumer获取消息后,万一consumer在消费消息的过程中发生了异常,如果rabbitmq一旦发送消息给consumer后立刻删除消息,也会有消息丢失的可能。 确认机制解决
4.1 消息持久化
@Queue注解中的属性 - autoDelete:当所有消费客户端连接断开后,是否自动删除队列 。true:删除 false:不删除
@Exchange注解中的属性 - autoDelete:当交换器所有的绑定队列都不再使用时,是否自动删除交换器。true:删除 false:不删除
4.2 消息确认机制 ACK-acknowledge
什么是消息确认机制?
如果在消息处理过程中,消费者的服务器在处理消息时发生异常,那么这条正在处理的消息就很可能没有完成消息的消费,如果RabbitMQ在Consumer消费消息后立刻删除消息,则可能造成数据丢失。为了保证数据的可靠性,RabbitMQ引入了消息确认机制。
消息确认机制是消费者Consumer从RabbitMQ中收到消息并处理完成后,反馈给RabbitMQ的,当RabbitMQ收到确认反馈后才会将此消息从队列中删除。
如果某Consumer在处理消息时出现了网络不稳定,服务器异常等现象时,那么就不会有消息确认反馈,RabbitMQ会认为这个消息没有正常消费,会将消息重新放入队列中。
如果在Consumer集群环境下,RabbitMQ未接收到Consumer的确认消息时,会立即将这个消息推送给集群中的其他Consumer,保证不丢失消息。
如果Consumer没有确认反馈,RabbitMQ将永久保存消息。
消息确认机制默认都是开启状态的,同时不推荐关闭消息确认机制。
注意:如果Consumer没有处理消息确认,将导致严重后果。如:所有的Consumer都没有正常反馈确认信息,并退出监听状态,消息则会永久保存,并处于锁定状态,直到消息被正常消费为止。消息的发送者Producer如果持续发送消息到RabbitMQ,那么消息将会堆积,持续占用RabbitMQ所在服务器的内存,导致“内存泄漏”问题。
4.3 消息确认机制处理方案
编码异常处理(推荐)
通过编码处理异常的方式,保证消息确认机制正常执行。这种处理方案也可以有效避免消息的重复消费。
异常处理,不是让Consumer编码catch异常后,直接丢弃消息,或反馈ACK确认消息。而是做异常处理的。该抛的异常,还得抛,保证ACK机制的正常执行。或者使用其他的手法,实现消息的再次处理。如:catch代码块中,将未处理成功的消息,重新发送给MQ。如:catch代码中,本地逻辑的重试(使用定时线程池重复执行任务3次。)
配置重试次数处理
通常来说,消息重试3次以上未处理成功,就是Consumer开发出现了严重问题。需要修改Consumer代码,提升版本/打补丁之类的处理方案。
通过全局配置文件,开启消息消费重试机制,配置重试次数。当RabbitMQ未收到Consumer的确认反馈时,会根据配置来决定重试推送消息的次数,当重试次数使用完毕,无论是否收到确认反馈,RabbitMQ都会删除消息,避免内存泄漏的可能。具体配置如下:
|
#开启重试 spring.rabbitmq.listener.retry.enabled=true #重试次数,默认为3次 spring.rabbitmq.listener.retry.max-attempts=5 |
可参考文章:
安装教程:
http://www.cnblogs.com/uptothesky/p/6094357.html【失败】
http://blog.csdn.net/zhouyongku/article/details/53676837【成功】
使用场景
http://www.cnblogs.com/luxiaoxun/p/3918054.html
延时队列
http://blog.csdn.net/u014045580/article/details/72637710
消息队列 RabbitMQ 与 Spring 整合使用
http://www.cnblogs.com/libra0920/p/6230421.html
RabbitMQ学习(八)之spring-amqp的重要类的认识
http://blog.csdn.net/qq397709884/article/details/51918354