HashMap是Java程序员使用频率最高的用于映射(键值对)处理的数据类型。HashMap 继承自 AbstractMap 是基于哈希表的 Map 接口的实现,以 Key-Value 的形式存在,即存储的对象是 Entry (同时包含了 Key 和 Value)
本文所有源码都是基于JDK1.8的,不同版本的代码差异可以自行查阅官方文档。
HashMap源码(JDK1.8):
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable { /** * The maximum capacity, used if a higher value is implicitly specified * by either of the constructors with arguments. * MUST be a power of two <= 1<<30. */ static final int MAXIMUM_CAPACITY = 1 << 30; static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; // .... } /** * The table, initialized on first use, and resized as * necessary. When allocated, length is always a power of two. * (We also tolerate length zero in some operations to allow * bootstrapping mechanics that are currently not needed.) */ transient Node<K,V>[] table; //.... }
HashMap 内部存储使用了一个 Node 数组(默认大小是16),每个Node都是一个链表。每个链表存储相同索引的元素。
之所以采取这样的数据结构存储数据是为了防止冲突发生:Java中两个不同的对象可能有一样的hashCode,所以不同的键可能有一样hashCode,从而导致冲突的产生。
static final int TREEIFY_THRESHOLD = 8; static final int UNTREEIFY_THRESHOLD = 6;
从Java 8开始,HashMap(ConcurrentHashMap以及LinkedHashMap)在处理频繁冲突时,为了提升性能将使用平衡树来代替链表,当同一hash桶中的元素数量超过特定的值(TREEIFY_THRESHOLD )便会由链表切换到平衡树,这会将get()方法的性能从O(n)提高到O(logn)。
而对HashMap进行split操作而生成元素数量在特定的值或以下时,平衡树会被重新转化成链表。
HashMap的自动扩容机制
/** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 /** * The load factor used when none specified in constructor. */ static final float DEFAULT_LOAD_FACTOR = 0.75f;
HashMap 内部的 Node 数组默认的大小是16(DEFAULT_INITIAL_CAPACITY )。
假设有1万个元素需要放入HashMap,那么最好的情况下每个 hash 桶里都有625个元素(每625个元素共用一个索引)。此时你要调用put()、get()、remove()等方法去操作某一个元素,平均要遍历313个元素,效率大大降低。
为了解决这个问题,HashMap 提供了自动扩容机制,当元素个数达到 数组大小 × 负载因子 的数量后会扩大数组的大小(最长链表的Entry个数 > threshold)。在默认情况下,数组大小为16,因子(DEFAULT_LOAD_FACTOR )为0.75,也就是说当 HashMap 中的元素超过16*0.75=12时,会把数组大小扩展为2*16=32,并且重新分配索引,计算每个元素在新数组中的位置。
线程不安全
HashMap 在并发时可能出现的问题主要是两方面:
1. put的时候导致的多线程数据不一致
比如有两个线程A和B,首先A希望插入一个key-value对到HashMap中,首先计算记录所要落到的 hash桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的 hash桶索引和线程B要插入的记录计算出来的 hash桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。
2. resize而引起死循环(JDK1.8已经不会出现该问题)
这种情况发生在JDK1.7 中HashMap自动扩容时,当2个线程同时检测到元素个数超过 数组大小 × 负载因子。此时2个线程会在put()方法中调用了resize(),两个线程同时修改一个链表结构会产生一个循环链表(JDK1.7中,会出现resize前后元素顺序倒置的情况)。接下来再想通过get()获取某一个元素,就会出现死循环。
线程安全的Map
- Hashtable
- ConcurrentHashMap
- Synchronized Map
//Hashtable Map<String, String> hashtable = new Hashtable<>(); //synchronizedMap Map<String, String> synchronizedHashMap = Collections.synchronizedMap(new HashMap<String, String>()); //ConcurrentHashMap Map<String, String> concurrentHashMap = new ConcurrentHashMap<>();
Hashtable (deprecate)
Hashtable 源码中是使用 synchronized 来保证线程安全的,比如下面的 get 方法和 put 方法:
public synchronized V get(Object key) {...} public synchronized V put(K key, V value) {...}
所以当一个线程访问 HashTable 的同步方法时,其他线程如果也要访问同步方法,会被阻塞住。因此Hashtable效率很低,基本被废弃。
ConcurrentHashMap
ConcurrentHashMap沿用了与它同时期的HashMap版本的思想,底层依然由“数组”+链表+红黑树的方式思想,但是为了做到并发,又增加了很多辅助的类,例如TreeBin,Traverser等对象内部类。
且与hashtable不同的是:
ConcurrentHashMap没有对整个hash表进行锁定,而是采用了分离锁(segment)的方式进行局部锁定。具体体现在,它在代码中维护着一个segment数组。
/** For serialization compatibility. */ private static final ObjectStreamField[] serialPersistentFields = { new ObjectStreamField("segments", Segment[].class), new ObjectStreamField("segmentMask", Integer.TYPE), new ObjectStreamField("segmentShift", Integer.TYPE) };
它增加了一个的属性——sizeCtl:
hash表初始化或扩容时的一个控制位标识量。
负数代表正在进行初始化或扩容操作
-1代表正在初始化
-N 表示有N-1个线程正在进行扩容操作
正数或0代表hash表还没有被初始化,这个数值表示初始化或下一次进行扩容的大小
/** * Table initialization and resizing control. When negative, the * table is being initialized or resized: -1 for initialization, * else -(1 + the number of active resizing threads). Otherwise, * when table is null, holds the initial table size to use upon * creation, or 0 for default. After initialization, holds the * next element count value upon which to resize the table. */ private transient volatile int sizeCtl; static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; volatile V val; volatile Node<K,V> next; public final V setValue(V value) { throw new UnsupportedOperationException(); } } /** * Virtualized support for map.get(); overridden in subclasses. */ Node<K,V> find(int h, Object k) { Node<K,V> e = this; if (k != null) { do { K ek; if (e.hash == h && ((ek = e.key) == k || (ek != null && k.equals(ek)))) return e; } while ((e = e.next) != null); } return null; }
在ConcurrentHashMap的Node内部类中,它对val和next属性设置了volatile同步锁,不允许调用setValue方法直接改变Node的value域,增加了find方法辅助map.get()方法。
SynchronizedMap
SynchronizedMap是Collectionis的内部类。
private static class SynchronizedMap<K,V> implements Map<K,V>, Serializable { private final Map<K,V> m; // Backing Map final Object mutex; // Object on which to synchronize public int size() { synchronized (mutex) {return m.size();} } public boolean isEmpty() { synchronized (mutex) {return m.isEmpty();} } public boolean containsKey(Object key) { synchronized (mutex) {return m.containsKey(key);} } public boolean containsValue(Object value) { synchronized (mutex) {return m.containsValue(value);} } public V get(Object key) { synchronized (mutex) {return m.get(key);} } public V put(K key, V value) { synchronized (mutex) {return m.put(key, value);} } public V remove(Object key) { synchronized (mutex) {return m.remove(key);} } public void putAll(Map<? extends K, ? extends V> map) { synchronized (mutex) {m.putAll(map);} } public void clear() { synchronized (mutex) {m.clear();} } //... }
在 SynchronizedMap 类中使用了 synchronized 同步关键字来保证对 Map 的操作是线程安全的。
三者的效率对比:
分别通过三种方式创建 Map 对象,使用
ExecutorService 来并发运行5个线程,每个线程添加/获取500K个元素,比较其用时多少。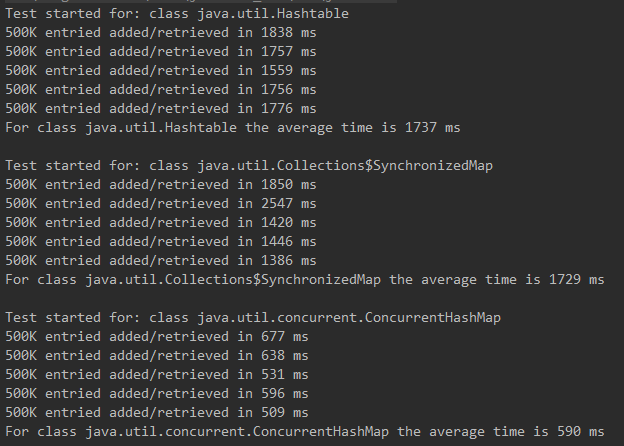
代码就不贴了,详见这里
ConcurrentHashMap明显优于Hashtable和SynchronizedMap 。