runxinzhi.com
首页
百度搜索
python爬取中国卫生健康委员会疫情报表
中国卫生健康委员会网站具有反爬取功能,并需加入请求头,并且cookie每隔很短时间就会刷新一次,因此每次爬取都需要更换一下cookie
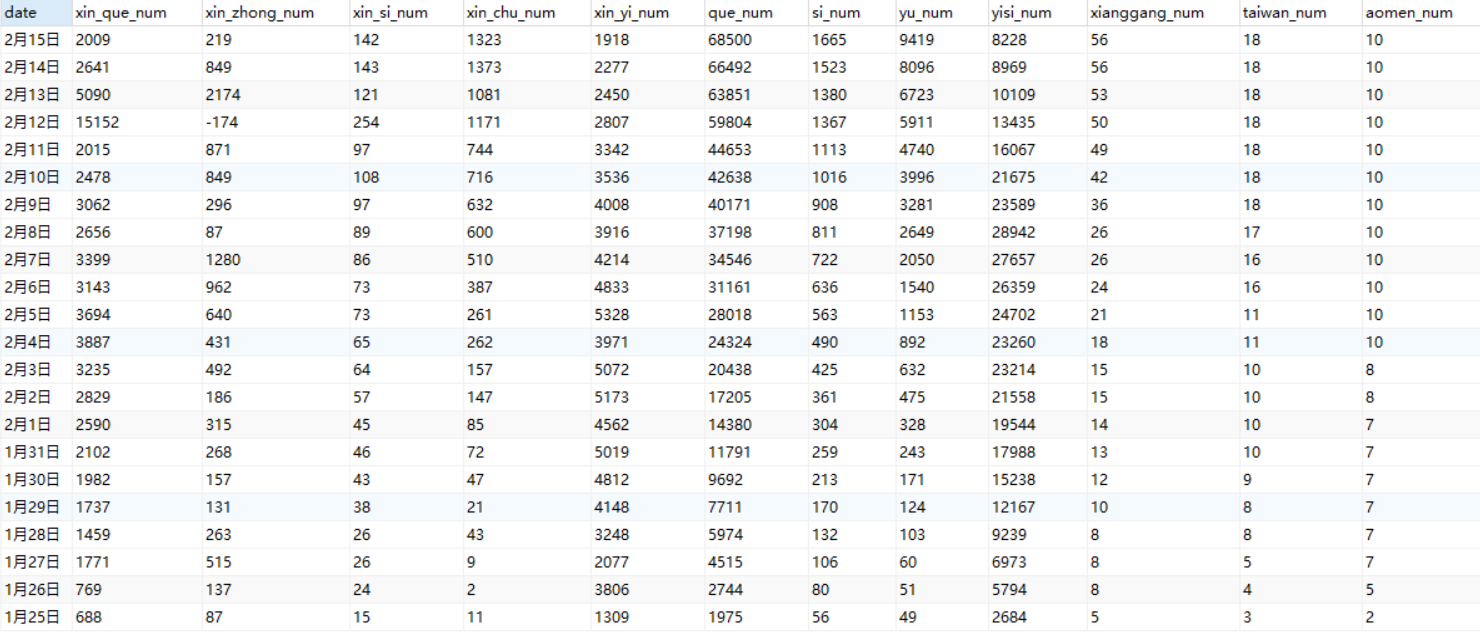
爬取数据如下:
相关阅读:
puppeteer 模拟登录淘宝
基于Istio构建微服务安全加固平台的探索
试着给VuePress添加全局禁止爬取支持,基于vuepress-plugin-robots
关于Word转Markdown的工具Typora安装及使用
关于基于Nexus3和Docker搭建私有Nuget服务的探索
关于Kubernetes(简称K8S)的开启及基本使用,基于Docker Desktop & WSL2
关于WLS2中Ubuntu启用SSH远程登录功能,基于Xshell登录,支持Root
关于Ubuntu开启ifConfig和Ping命令的支持,查看本机Ip地址和检查外部连接
关于.Net Core使用Elasticsearch(俗称ES)、Kibana的研究说明
关于使用Draw.io画数据库E-R图的说明
原文地址:https://www.cnblogs.com/yuanxiaochou/p/12318473.html
最新文章
iWebExcel 协同数据填报和在线分析平台
企业表格技术与风险指标补录系统
SpreadJS 纯前端表格控件应用案例:畅捷通财务T-UFO报表
SpreadJS 纯前端表格控件应用案例:金融业数据智能分析平台
SpreadJS 纯前端表格控件应用案例:Teammark知识管理库
SpreadJS 纯前端表格控件应用案例:雨诺订单管理系统(雨诺OMS)
SpreadJS 纯前端表格控件应用案例:MHT-CP数据填报采集平台
SpreadJS 纯前端表格控件应用案例:表格数据管理平台
Spring Boot之kaptcha图形验证码
49.在visual studio中安装opencv方法
热门文章
48.linux下安装pycharm2020方法详解
Pormise
http状态
npm下载慢
常用sql整理
puppeteer 无头浏览器防检测
node使用mysql
nodejs定时启动程序
puppeteer 植入原生js
puppeteer 使用
Copyright © 2020-2023
润新知