摘要
这篇论文提出一种用于目标检测的Fast R-CNN算法。Fast R-CNN建立在之前的研究工作,使用深度卷积网络来高效的分类目标提案。相比于之前的工作,Fast R-CNN采用了一些创新来提高训练和测试的速度,同时也提高了检测的准确率。Fast R-CNN训练深度VGG16网络比训练R-CNN快9倍,在测试时快213倍,并且在PASCAL VOC 2012数据集上获得了一个更高的平均平均准确率(mAP)。和SPPnet相比,Fast R-CNN训练VGG16比它快3倍,测试时快10倍,并且更加准确,Fast R-CNN采用python和C++(Cafe)实现,开源代码。
1 引言
目前,深度卷积网络已经明显的提高了图像分类和目标检测的准确率。相比于图像分类,目标检测则是一项更具挑战性的任务,它需要更加复杂的方法来解决。由于这种复杂性,目前多级管道中所获得的模型速度缓慢而且粗糙。
复杂性的产生是由于检测需要对目标进行精确的定位,这就产生了两个主要的挑战。第一,必须处理大量的候选目标位置(通常称为“提案”);第二,这些候选目标位置仅提供一个粗略的定位,这就必须对其进行改进以提供更加精确的定位。解决这些问题往往会影响速度、准确性和简单性。
在本文中,我们简化了最先进的基于卷积神经网络的目标检测器的训练过程,我们提出了一种单级的训练算法,这种算法同时学习分类目标的候选方案和改进他们的空间位置。
由此产生的方法可训练一个非常深的检测网络(VGG16),该网络比R-CNN快9倍,比SPPnet快3倍。在运行时,该检测网络处理一幅图像耗时3s(不包括目标方案生成时间),并且在PASCAL VOC 2012数据集上取得最好的准确率66%mAP(R-CNN:62%)
1.1 R-CNN与SPPnet
R-CNN使用深度卷积网络来分类目标提案获得了非常好的目标检测准确率,但是,R-CNN有一些明显的缺点:
- 1.多阶段训练过程 R-CNN首先采用log损失在目标提案上微调卷积神经网络,然后,训练适合卷积网络特征的SVM,这些SMV作为目标检测器,使用微调来代替softmax分类器。在第三阶段,进行边界框回归。
- 2.训练空间和时间消耗大 对于SVM和边界框回归的训练,特征是从每一幅图像的每一个目标提案提取出来并写入磁盘中的。使用深度网络,例如:VGG16,对于VOC 2007 训练集的5K图像来说,这个过程要使用GPU训练两天半,这些特征需要数百GB的存储空间来存储。
- 3.目标检测速度慢 在测试时,特征是从每一幅测试图像的每一个目标提案中提取出来的,采用VGG16的检测器处理一幅图像需要47s(在GPU上)。
R-CNN速度慢是因为每一个目标提案都会通过卷积神经网络进行前向计算,而不共享计算。空间金字塔池化网络(SPPnet)通过共享计算加速了R-CNN。SPPnet方法为整个输入图像计算一个卷积特征映射,然后使用从共享特征映射中提取的特征向量对每个目标提案进行分类。通过最大池化提案内部的部分特征映射来形成一个固定大小的输出(例如:6x6)达到特征提取的目的。多种大小的输出汇集在一起,然后连接成空间金字塔池化(SPP)。在测试时,SPPnet加速了R-CNN10到100倍,在训练时,由于更快的提案特征提取过程,也加速了3倍。
SPPnet也有一些明显的缺点。像R-CNN一样,它的训练过程也是一个多阶段过程,这个过程围绕特征提取、采用log损失对网络进行微调、训练SVM和最后的拟合边界框回归展开。特征也要写入磁盘,但是,在[11]中提出微调算法不更新SPP之前的卷积层参数。不出所料,这些限制限制了深度网络的准确率。
1.2 贡献
我们提出了一种新的算法来弥补R-CNN和SPPnet的不足,同时提升了它们的速度和准确率。我们称这种方法为Fast R-CNN,因为在训练和测试时相对较快。Fast R-CNN有如下优点:
- 1.比R-CNN和SPPnet更高的检测质量;
- 2.采用多任务损失,训练过程为单阶段;
- 3.训练可以更新所有网络层;
- 4.特征缓存不需要磁盘存储。
Fast R-CNN采用Python和C++(Cafe)实现,开源代码。
输入到一个全卷积网络,每一个RoI都被池化为一个固定大小的特征映射,然后通过全连接网络映射到特征向量。该网络对于每一个RoI都有两个输出向量:softmax概率和每一类的边界框回归补偿。这种结构是采用多任务损失训练的端到端结构。")
图1 Fast R-CNN结构 一幅输入图像和多个感兴趣区域(RoI)输入到一个全卷积网络,每一个RoI都被池化为一个固定大小的特征映射,然后通过全连接网络映射到特征向量。该网络对于每一个RoI都有两个输出向量:softmax概率和每一类的边界框回归补偿。这种结构是采用多任务损失训练的端到端结构。
2 Fast R-CNN结构和训练
图1展示了Fast R-CNN的结构。Fast R-CNN网络将一幅完整的图像和一系列目标提案作为输入。该网络首先采用一些卷积层和最大池化层生成卷积特征映射来处理整个图像。然后,对于每一个目标提案,感兴趣区域(RoI)池化层从特征映射中提取出一个固定长度的特征向量。每一个特征向量被送到一系列的全连接层(fc)最终分支到两个同级输出层:一层是在所有K个目标类加上一个全方位的背景类产生softmax概率估计;另一层则对每个K类目标输出4个真实数字,每一组的4个值编码了一个K类目标的精确的边界框位置。
2.1 RoI池化层
RoI池化层采用最大池化将任何有效的RoI内部特征转换为具有HxW固定空间范围的小的特征映射,H和W为层超参数,它们独立于任何的RoI。在本文中,每一个RoI都被定义为一个四元(r,c,h,w)组,这个四元组指定了RoI左上角的位置(r,c)和它的高度和宽度(h,w)。
RoI最大池化的工作是将h x w的RoI窗口划分为一个H x W的网格,其子窗口近似大小为h/H x w/W。然后,将每个子窗口中的值合并到相应的输出网格单元中。池化被独立的应用到每一个特征映射通道,作为标准的最大池化。RoI层就是应用在SPPnet中的空间金字塔池化层的简单应用,在这里它只有一层金字塔等级。我们使用[11]中给出的池子窗口计算。
2.2 从预训练网络初始化
我们使用三个ImageNet 预训练网络进行试验,每个网络都有5个最大池化层和5到13个卷积层。当一个预训练的网络初始化一个Fast R-CNN网络时,它会经历三个转换。
首先,用一个RoI池化层替换最后一个最大池化层,它通过设置H和W来与网络的第一个全连接层相适应(例如:VGG16的H和W为7)。
然后,网络的最后一个全连接层和softmax(训练用于1000类ImageNet图像分类)用之前所描述的两个同级输出层(一个全连接层和K+1类的softmax和类特定的边界框回归)替换。
最后,该网络被修改为接受两个数据输入:一系列图像和一系列图像的RoI。
2.3 检测微调
采用反向传播计算所有网络权重是Fast R-CNN的一项非常重要的能力,让我来解释一下为什么SPPnet在空间金字塔池化层下不能更新权重。
根本原因是当来自于不同图像的训练样本通过SPP层时,它所使用的反向传播算法的效率是非常低的,这是由SPPnet和R-CNN的训练方式所决定的。这种低效源于这样一个事实,那就是每一个RoI有一个非常大的感受野,通常包含整个图像。由于前向传播必须处理整个感受野,而训练输入又很大(通常是整幅图像)。
我们提出了一种更加有效的训练方式,那就是在训练时利用特征共享的优点。在Fast R-CNN的训练中,随机梯度下降(SGD)的小批采用分层次采样,首先采样N幅图像,然后从每幅图像中采样R/N个RoI。关键的是,来自同一图像的RoI在前向和后向过程中共享计算和内存。使用N的小批量减少小批量的计算量。例如当N等于2,R等于128时,这个训练过程要比从128幅不同的图像中采样一个RoI(即R-CNN和SPPnet的策略)快64倍。
这一策略的一个担忧就是,这可能会导致训练收敛缓慢,因为同一幅图像中的RoI是具有相关性的。我们将N和R分别设置为2和128,并且使用比R-CNN更少的SGD迭代次数,我们取得了一个不错的结果,使得这种担忧没有成为一个实际问题。
除了分层抽样之外,Fast R-CNN使用了具有一个微调阶段的流线型训练过程,这个微调阶段联合优化了一个softmax分类器和边界框回归,而不是训练一个softmax分类器、SVM和三个独立阶段的回归。这个过程的组成部分(损失、小批量采样策略、RoI池化层的反向传播、SGD超参数)在下面进行讲述。
-
多任务损失 一个Fast R-CNN网络具有两个同级输出层。第一个输出是所有K+1类的一个离散概率分布(每一个RoI),
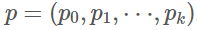 。和往常一样,p由全连接层的K+1个输出上的softmax计算。第二个同级层输出边界框回归补偿,
。和往常一样,p由全连接层的K+1个输出上的softmax计算。第二个同级层输出边界框回归补偿,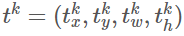 对每一个K目标类采用k进行索引。我们采用了在[9]中提出的参数化方法参数化tktk,tktk表示一个尺度不变的变换和log空间的高宽相对于目标提案的偏移。
对每一个K目标类采用k进行索引。我们采用了在[9]中提出的参数化方法参数化tktk,tktk表示一个尺度不变的变换和log空间的高宽相对于目标提案的偏移。每一个训练RoI都被标记为一个真实类u和一个真实边界框回归目标v。对分类和边界框回归,我们在被标记的RoI上使用多任务损失L来训练:
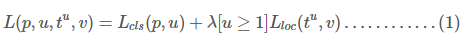
其中
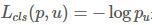 是对真实类u的log损失。
是对真实类u的log损失。第二个任务损失,即LlocLloc,由类u的一组真实边界框回归目标
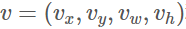 和类u的预测元组
和类u的预测元组