最近一直在学习爬虫方面的知识,时不时遇到字符编码的错误,每次都很头疼,现在我就来总结一下字符编码和数据传输的相关知识。(部分内容来自我在OneNote做的笔记)
一、字符编码类型
1.ASCII
美国(国家)信息交换标准(代)码,一种使用7个或8个二进制位进行编码的方案,最多可以给256个个字符(包括字母、数字、标点符号、控制字符及其他符号)分配(或指定)数值。
很不错,但是表示不了中文啊。于是

2.ANSI
为了扩充ASCII编码,以用于显示本国的语言,不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。
但是由于ANSI在个个操作系统下不兼容,在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码。同一个编码值,在不同的编码体系里代表着不同的字。
容易造成混乱。因此unicode(万国码应运而生)。
3.Unicode
Unicode码其中每个语言下的ANSI编码,都有一套一对一的编码转换器,Unicode变成所有编码转换的中间介质。所有的编码都有一个转换器可以转换到Unicode,而Unicode也可以转换到其他所有的编码。
Unicode固然统一了编码方式,但是它的效率不高,比如UCS-4(Unicode的标准之一)规定用4个字节存储一个符号,那么每个英文字母前都必然有三个字节是0,这对存储和传输来说都很耗资源。
于是,我们熟知的utf-8就出来了。
4.UTF-8
为了提高Unicode的编码效率,于是就出现了UTF-8编码。UTF-8可以根据不同的符号自动选择编码的长短。比如英文字母可以只用1个字节就够了。
5.GB2312和GBK
二者都是中文编码,GBK编码包括GBK2312,它还包括人名、古汉语等方面出现的罕用字。
注意,在windows下默认文件字符编码是GB2312!!!
二、数据传输
在写爬虫时,我们都是模拟浏览器对服务器发起请求,服务器接受到我们的请求时会给我们传输数据。
下面是web服务器处理http压缩的过程(摘取部分,原文链接在下面)
1. Web服务器接收到浏览器的HTTP请求后,检查浏览器是否支持HTTP压缩(Accept-Encoding 信息);
2. 如果浏览器支持HTTP压缩,Web服务器检查请求文件的后缀名;
3. 如果请求文件是HTML、CSS等静态文件,Web服务器到压缩缓冲目录中检查是否已经存在请求文件的最新压缩文件;
4. 如果请求文件的压缩文件不存在,Web服务器向浏览器返回未压缩的请求文件,并在压缩缓冲目录中存放请求文件的压缩文件;
5. 如果请求文件的最新压缩文件已经存在,则直接返回请求文件的压缩文件;
6. 如果请求文件是动态文件,Web服务器动态压缩内容并返回浏览器,压缩内容不存放到压缩缓存目录中。
原文:https://blog.csdn.net/clerk0324/article/details/51672933
1)当没有指定 Accept-Encoding 或者指定为'Accept-Encoding': 'deflate'时,服务器返回的时GB2312编码的文件,如下图:

查看网页源代码可以发现它的编码就是GB2312。
2)当指定为'Accept-Encoding': 'gzip'时,服务器返回的时NONE编码的文件,如下图:

此时下载下来的页面是乱码。将'Accept-Encoding': 'gzip'注释掉或者将’gzip‘改为'deflate'即可。
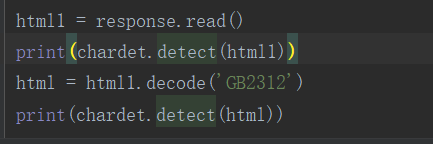
3)当我试着把读取到的'gb2312'文件解码后再用chardet.detect()方法查看当前文件的编码时,报错了!
代码:
报错:
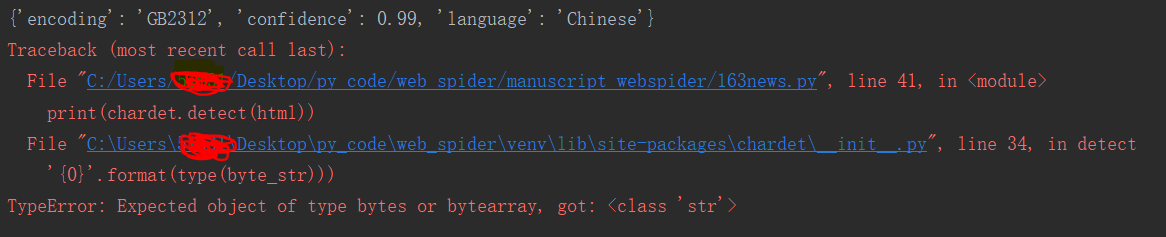
这说明编码的操作对象是字符,编码就是将字符规律地转化为字节或是字节数组,便于在网络中传输。
我这里一开始已经将html1解码了,得到的是字符串,因此后面的解码操作会报错。
因此,我们在进行文件操作时需要注意编码格式统一。
三、一些常见的报错及原因
1.UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd1 in position 429: invalid continuation byte
utf-8 的解码错了,查看网页源代码看看它的编码方式,改成它即可,或者下载网页后不要解码,直接wb写入即可。
2.下载成功了,但是打开会出现乱码
这就是因为当指定为'Accept-Encoding': 'gzip'时,服务器返回的时NONE编码的文件。注释掉'Accept-Encoding': 'gzip'即可。