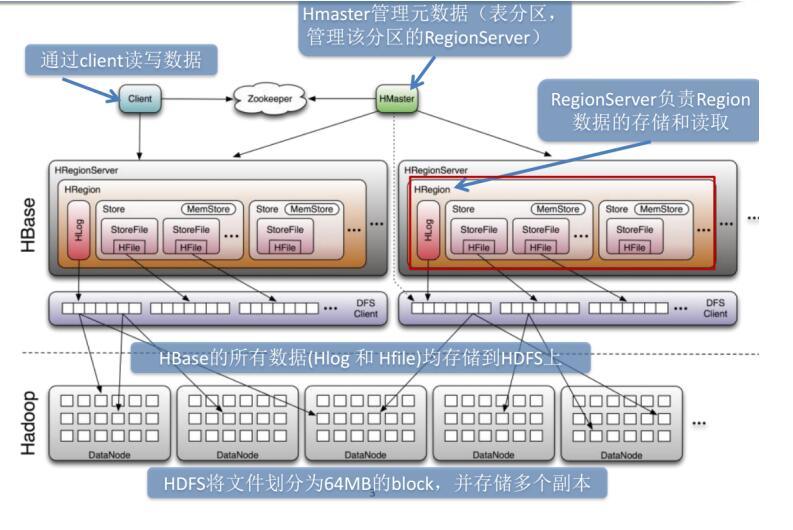
Hbase系统架构图
1、数据热点问题
产生数据热点问题的原因:
(1)Hbase的数据是按照字典排序的,当大量连续的rowkey集中写到个别的region,各个region之间实际分布不均衡;
(2)创建表时没有提前预分区,创建的表默认只有一个region,大量的数据写入当前region;
(3)创建表已经提前预分区,但是设计的rowkey没有规律可循。
热点问题的解决方案:
(1)随机数+业务主键,如果更好的让最近的数据get到,可以加上时间戳;
(2)Rowkey设计越短越好,不要超过10-100个字节;
(3)映射regionNo,这样既可以让数据均匀分布到各个region中,同时可以根据startkey和endkey可以个get到同一批数据。
2、描述hbase的rowkey的设计原理
三大设计原则:
(1)唯一性原则
rowkey在设计上保证其唯一性。rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
(2)长度原则
rowkey是一个二进制码流,可以是任意字符串,最大长度 64kb ,实际应用中一般为10-100bytes,以byte[] 形式保存,一般设计成定长。建议越短越好,不要超过16个字节,原因如下:数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性。
(3)散列原则
加盐:如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率加盐:这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点
哈希:哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据
反转:第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。反转rowkey的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题
时间戳反转:一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为rowkey的一部分对这个问题十分有用,可以用Long.Max_Value - timestamp 追加到key的末尾,例如key ,[key] 的最新值可以通过scan [key]获得[key]的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据。比如需要保存一个用户的操作记录,按照操作时间倒序排序,在设计rowkey的时候,可以这样设计userId反转,在查询用户的所有操作记录数据的时候,直接指定反转后的userId,startRow是userId反转,stopRow是userId反转如果需要查询某段时间的操作记录,startRow是user反转,stopRow是userId反转
3、hbase中compact的用途
在HBase中,每当memstore的数据flush到磁盘后,就形成一个storefile,当storefile的数量越来越大时,会严重影响HBase的读性能 ,HBase内部的compact处理流程是为了解决MemStore Flush之后,文件数目太多,导致读数据性能大大下降的一种自我调节手段,它会将文件按照某种策略进行合并,大大提升HBase的数据读性能。
主要起到如下几个作用:
(1)合并文件
(2)清除删除、过期、多余版本的数据
(3)提高读写数据的效率
这两种compaction方式的区别是:
1、Minor操作只用来做部分文件的合并操作以及包括minVersion=0并且设置ttl的过期版本清理,不做任何删除数据、多版本数据的清理工作。
2、Major操作是对Region下的HStore下的所有StoreFile执行合并操作,最终的结果是整理合并出一个文件。
compaction触发时机:
(1)Memstore刷写后,判断是否compaction
(2)CompactionChecker线程,周期轮询
4、Hbase中regionserver挂了 如何恢复数据
引起RegionServer宕机的原因各种各样,有因为Full GC导致、网络异常导致、官方Bug导致(close wait端口未关闭)以及DataNode异常导致等等
HBase检测宕机是通过Zookeeper实现的, 正常情况下RegionServer会周期性向Zookeeper发送心跳,一旦发生宕机,心跳就会停止,超过一定时间(SessionTimeout)Zookeeper就会认为RegionServer宕机离线,并将该消息通知给Master
一旦RegionServer发生宕机,HBase都会马上检测到这种宕机,并且在检测到宕机之后会将宕机RegionServer上的所有Region重新分配到集群中其他正常RegionServer上去,再根据HLog进行丢失数据恢复,恢复完成之后就可以对外提供服务,整个过程都是自动完成的,并不需要人工介入.

5、简单介绍Hbase的二级索引
默认情况下,Hbase只支持rowkey的查询,对于多条件的组合查询的应用场景,不够给力。
如果将多条件组合查询的字段都拼接在RowKey中显然又不太可能
全表扫描再结合过滤器筛选出目标数据(太低效),所以通过设计HBase的二级索引来解决这个问题。
所谓的二级索引其实就是创建新的表,并建立各列值(family:column)与行键(rowkey)之间的映射关系。这种方式需要额外的存储空间,属于一种以空间换时间的方式
6、Hbase的优化
内存优化
垃圾回收优化:CMS, G1(Region)
JVM启动:-Xms(1/64) –Xmx(1/4)
Region优化
预分区
禁用major合并,手动合并
客户端优化
批处理
7、Hbase和mysql的区别
数据存储方式:
mysql面向行存储数据;
hbase面向列存储数据,有利于压缩和统计
数据之间的联系:
mysql存储关系型数据,结构化数据
Hbase存储的非关系型数据,存储结构化和非结构化数据
事务处理:
mysql数据库存在事务,欣慰着重于计算
hbase数据库侧重于海量数据存储,所以没有事务概念
8、hbase如何导入数据
通过HBase API进行批量写入数据; 使用Sqoop工具批量导数到HBase集群; 使用MapReduce批量导入; HBase BulkLoad的方式。
9、Hbase 和 hive 区别
共同点:
hbase与hive都是架构在hadoop之上的。都是用hadoop作为底层存储。
区别:
Hive是建立在Hadoop之上为了减少MapReducejobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目 。
想象你在操作RMDB数据库,如果是全表扫描,就用Hive+Hadoop,如果是索引访问,就用HBase+Hadoop;
Hive query就是MapReduce jobs可以从5分钟到数小时不止,HBase是非常高效的,肯定比Hive高效的多; Hive本身不存储和计算数据,它完全依赖于 HDFS 和 MapReduce,Hive中的表纯逻辑; hive借用hadoop的MapReduce来完成一些hive中的命令的执行; hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作; hbase是列存储;hdfs 作为底层存储,hdfs 是存放文件的系统,而 Hbase 负责组织文件; hive 需要用到 hdfs 存储文件,需要用到 MapReduce 计算框架。
9、hbase 实时查询的原理
实时查询,可以认为是从内存中查询,一般响应时间在 1 秒内。HBase 的机制是数据先写入到内存中,当数据量达到一定的量(如 128M),再写入磁盘中, 在内存中,是不进行数据的更新或合并操作的,只增加数据,这使得用户的写操作只要进入内存中就可以立即返回,保证了 HBase I/O 的高性能。
10、Hbase中scan和get的功能以及实现的异同
HBase的查询实现只提供两种方式:
1、按指定RowKey 获取唯一一条记录,get方法(org.apache.hadoop.hbase.client.Get) Get 的方法处理分两种 : 设置了ClosestRowBefore 和没有设置的rowlock .主要是用来保证行的事务性,即每个get 是以一个row 来标记的.一个row中可以有很多family 和column.
2、按指定的条件获取一批记录,scan方法(org.apache.Hadoop.hbase.client.Scan)实现条件查询功能使用的就是scan 方式.
(1)scan 可以通过setCaching 与setBatch 方法提高速度(以空间换时间);
(2)scan 可以通过setStartRow 与setEndRow 来限定范围([start,end)start 是闭区间, end 是开区间)。范围越小,性能越高。
(3)scan 可以通过setFilter 方法添加过滤器,这也是分页、多条件查询的基础。