一、引言
异常总是不可避免的,就算我们自身的代码足够优秀,但却不能保证用户都按照我们想法进行输入,就算用户按照我们的想法进行输入,我们也不能保证操作系统稳定,另外还有网络环境等,不可控因素太多,异常也不可避免。
但我们可以通过异常处理机制让程序有更好的容错性和兼容性,当程序出现异常时,系统自动生成Exception对象通知系统,从而将业务功能实现代码和错误处理代码分离。
异常处理已经成为衡量一门语言是否成熟的标志之一,增加了异常处理机制后程序有更好的健壮性和容错性。
二、
try{ //业务代码 } catch(IOException ex){ //错误处理 } catch(Exception ex){ //错误处理代码 }
当try块代码出错时,系统生成一个异常对象,并将对象抛给运行环境,这个过程叫做抛出异常,运行环境接收到异常对象是,会寻找处理该异常对象的catch代码块,找到合适的catch块,就将对象给其处理,如果找不到,则运行环境终止,程序也将退出。
2.2 异常类继承体系
Java提供了丰富的异常类,这些异常类有严格的继承关系
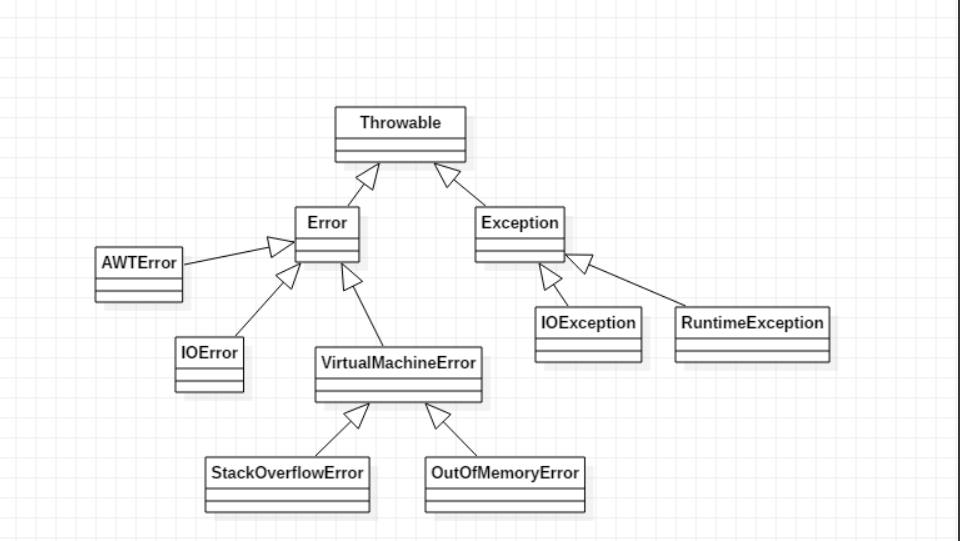
从这个图可以看出异常主要分为两类,Error与Exception,Error错误一般是指与虚拟机相关的问题,如系统崩溃、虚拟机错误,这些错误无法恢复或不可能捕获,将导致应用程序崩溃,这些不需要我们去捕获。
在捕获异常时我们通常把Exception类放在最后,因为按照异常捕获的机制,从上至下判断该异常对象是否是catch中的异常类或其异常子类,一旦比较成功则用此catch进行处理。如果将Exception类放在前面,那么就会进行直接进入其中,因为Exception类是所有异常类的父类,那排在它后面的异常类将永远得不到执行的机会,这种机制我们称为先小后大。
2.3 多异常捕获
Java 7 开始,一个catch块中可以捕获多种类型的异常:
public static void main(String[] args) { try { Integer a = Integer.parseInt(args[0]); Integer b = Integer.parseInt(args[1]); Integer c = a / b; System.out.println(c); } catch (IndexOutOfBoundsException | NumberFormatException | ArithmeticException ie) { //异常变量默认final,不能重新赋值 ie = new ArithmeticException("text"); } catch (Exception ex) { } }
多个异常之间用竖线(|)隔开,并且异常变量默认final,不能重新赋值。
2.4 获取异常信息
异常捕获后我们想要查看异常信息,可以通过catch后的异常形参来获得,常用的方法如下:
-
getMessage():返回异常的详细描述字符串。
-
getStackTrace():返回异常跟踪栈信息。
-
printStackTrace():将异常跟踪栈信息按照标准格式输出。
-
printStackTrace(PrintStream p):将异常跟踪栈信息输出到指定输出流。
try{ //业务代码 }catch(XXXException xx){ //异常处理 }catch(XXXException xx){ }finally{ //资源回收 }
在异常处理中,try是必须的,没有try块,后面的catch和finally没有意义,catch和finally必须出现一个,finally块必须是最后。
如果try块中有return语句,则会先执行finally,然后再执行return语句,如果try块中有exit语句,则不会执行finally,都直接退出虚拟机了当然不会再去执行。
2.
try ( BufferedReader bufferedReader = new BufferedReader(new FileReader("")) ) { bufferedReader.read(); }
三、
Java的异常分为两大类:Checked(可检查)异常和Runtime(运行时)异常,所有的RuntimeException类及其子类的实例就是Runtime异常,其他的都是Checked异常。
对于Checked异常处理方式有两种,一种是明确知道如何处理该异常,用try catch来捕获异常,然后在catch中修复异常,一种是不知道如何处理,在定义方法时申明抛出异常。
Runtime异常无需显示申明抛出,需要捕获异常,就用try catch来实现。
使用throws声明的思路是:当前方法不知道如何处理这种类型的异常,则由上一级调用者处理,如果main方法也不知道如何处理,也可以使用throws抛给JVM,JVM的处理是,打印异常的跟踪栈信息,并终止程序。
throws声明抛出只能在方法签名中使用,可以声明抛出多个异常类,多个异常类用逗号隔开,如:
public static void main(String[] args) throws IOException { FileInputStream fileInputStream = new FileInputStream(""); }
申明了throws就不需要再使用try catch来捕获异常了。
如果某段代码中调用了一个带throws声明的方法,那么必须用try catch来处理或者也带throws声明,如下例子:
public static void main(String[] args) { try { test(); } catch (IOException e) { e.printStackTrace(); } } public static void test () throws IOException{ FileInputStream fileInputStream = new FileInputStream(""); }
这个时候要注意,子类方法声明抛出的异常应该是父类方法声明抛出异常的子类活相同,不允许比父类声明抛出的异常多。
程序出现错误,系统会抛出异常,有时候我们也想自行抛出异常,比如用户未登录,我们可能就直接抛出错误,这种自行抛出的异常一般都与业务相关,因为业务数据与既定不符,但是这种异常并不是一种错误,系统不会捕捉,就需要我们自行抛出。
使用throw语句进行异常抛出,抛出的不是一个异常类,而是一个异常实例,而且每次只能抛出一个:
if (user== null) { throw new Exception("用户不存在"); }
这里我们又要区分Checked异常与运行时异常,运行时异常申明非常简单,直接抛出即可,而Checked异常又要像之前一样,要么使用try catch,要么声明throws
public static void main(String[] args) { try { //检查时异常需要写try catch test1(); } catch (Exception e) { e.printStackTrace(); } //运行时异常直接调用即可 test2(); } public static void test1() throws Exception { if (1 > 0) { throw new Exception("用户不存在"); } } public static void test2() { if (1 > 0) { throw new RuntimeException("用户不存在"); } }
public class GlobalException extends RuntimeException { //无参构造器 public GlobalException() { } //带有错误描述信息的构造器 public GlobalException(String msg) { super(msg); } }
在实际开发中,我们一般会分层开发,比较常用的是三层,表现出、业务逻辑层、数据库访问层,我们不会抛出数据库异常给用户,因为这些异常中有堆栈信息,很不安全,也非常的不友好。
通常,我们捕获原始异常(可以写入日志),然后再抛出一个业务异常(通常是自定义的异常),这个业务异常可以提示用户异常的原因:
public void update() throws GlobalException{ try{ //执行sql } catch (SQLException ex){ //记录日志 ... //抛出自定义错误 throw new GlobalException("数据库报错"); } catch (Exception ex){ //记录日志 ... throw new GlobalException("未知错误!"); } }
这种捕获一个异常然后抛出另一个异常,并将原始信息保存起来的是一种典型的链式处理(责任链模式)。
五、
异常给系统带来了健壮性和容错性,但是使用异常处理并非如此简单,我们还要注意性能和结构的优化,有些规则我们必须了解,而这些规则的主要目标是:
-
程序代码混乱最小化。
-
捕获并保留诊断信息。
-
通知合适的人员
-
采用合适的方式结束异常。
5.1 不要过度使用异常
什么叫过度使用异常呢?有两种情况,一是把异常和普通错误放在一起,使用异常来代替错误,什么意思呢?就是对一些我们已知或可控的错误进行异常处理,如一些业务逻辑判断,用户的输入等,并不是只有直接抛出异常这种选择,我们可以直接通过业务处理进行错误返回,而不是抛出错误,抛出错误的效率要低一些,只有对外部的、不能确定和预知的运行时错误使用异常。
二就是使用异常来代替流程控制,异常处理机制的初衷是将不可以预期的错误和正常的业务代码分离,不应该用异常来进行流程控制。
5.2 不要使用过大的try块
不要把大量的业务代码放在try中,大量的业务代码意味着错误可能性也增大,也意味着一旦出错,分析错误的复杂度也增加,而且try中包含大量业务,可能后面紧跟的catch块也很多,我们会使用多个catch来捕获错误,这样代码也很臃肿,应该尽量细分try,去分别捕获并处理。
5.3 不要忽略捕获到的异常
不要忽略异常,当我们捕获到异常时,我们不要去忽略它,如果在catch中什么也不做,那是一种恐怖的做法,因为这意味着出现了错误我们并不知道(极特殊的情况例外,比如:一些可重试的业务处理),最起码的做法是打印错误日志,更进一步看是否可以修复错误,或者向上抛出错误。