尝试设计一套特质,灵活的改动整数队列。队列有两种操作:put把整数放入队列,get从尾部取出它们。队列是先进先出的,get应该依照入队列的顺序取数据。提示:可以用mutable.ArrayBuffer 模拟队列在报告中体现出类的线性化特性,要求扩展类实现如下三个功能1.Doubling 把放到队列中的数字翻倍;2.Incrementing 把放到队列的数据增加1;3.过滤掉队列中的负数
1 abstract class Queue2 { 2 println("查看调用顺序Queue") 3 def get:Int 4 def put(num:Int) 5 } 6 trait Doubling extends Queue2 { 7 println("查看调用顺序Doubling") 8 abstract override def put(x: Int) { super.put(2*x) } 9 } 10 trait Incrementing extends Queue2 { 11 println("查看调用顺序Incrementing") 12 abstract override def put(x: Int) { super.put(x+1) } 13 } 14 trait Filtering extends Queue2 { 15 println("查看调用顺序Filtering") 16 abstract override def put(x: Int){ 17 if(x >= 0) super.put(x) 18 } 19 } 20 class NewQueue extends Queue2{ 21 println("查看调用顺序NewQueue") 22 private val numArrayBuffer = new ArrayBuffer[Int] 23 def get() = numArrayBuffer.remove(0) 24 def put(x: Int) = { 25 numArrayBuffer += x 26 } 27 } 28 object test5{ 29 def main(args: Array[String]): Unit = { 30 val queue = new NewQueue with Doubling 31 queue.put(1) 32 println(queue.get()) 33 34 val queue2 = new NewQueue with Doubling with Incrementing 35 queue2.put(10) 36 println(queue2.get()) 37 38 } 39 }
首先我们知道特质构造器的调用顺序是:
1.调用超类的构造器;
2.特质构造器在超类构造器之后、类构造器之前执行;
3.特质由左到右被构造;
4.每个特质当中,父特质先被构造;
5.如果多个特质共有一个父特质,父特质不会被重复构造
6.所有特质被构造完毕,子类被构造。
混入的顺序很重要,越靠近右侧的特质越先起作用。当你调用带混入的类的方法时,最右侧特质的方法首先被调用。如果那个方法调用了super,它调用其左侧特质的方法,以此类推。
这里很神奇的一点是,输入10,输出居然是22而不是21。貌似是Incrementing的put首先被调用,然后Doubing的put第二个被调用。但为什么在显示语句中,我们发现先显示的是“查看调用顺序Doubling”呢?
我们来看看类的线性化的含义:
特质是一种继承多个类似于类的结构的方式,但是它与多重继承有很重要的区别。其中一个尤为重要:super的解释。
对于多重继承来说,super调用导致的方法调用可以在调用发生的地方明确决定;对于特质来说,方法调用是由类和混入到类的特质的线性化(linearization)所决定的。这种差别使得上面的特质的堆叠成为可能。
在多重继承的语言中,调用相同的方法,编译规则会决定哪个超类最终胜出,而调用该超类的指定方法。
而在Scala中,当你使用new实例化一个类的时候,Scala把这个类和所有它继承的类还有他的特质以线性的次序放在一起。然后,当你在其中的一个类中调用super,被调用的方法就是方法链的下一节。除了最后一个调用super之外的方法,其净结果就是可堆叠的行为。
所以,在这里我们看到调用顺序的确是先Doubling后Incrementing,但是在线性的过程中,先执行的是最后一层,即越靠近右侧的特质越先起作用。先+1,再*2,最后put。
举例:
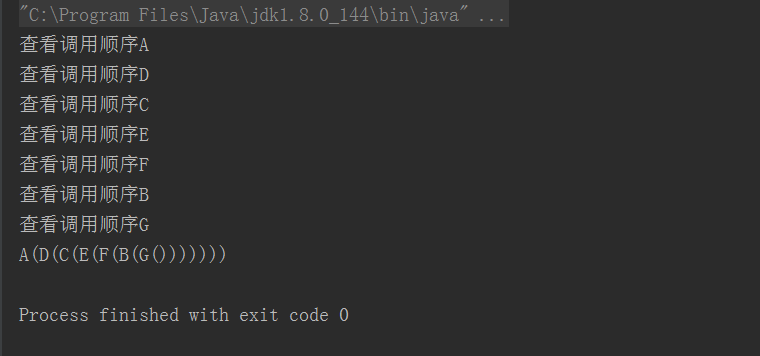
1 class A{ 2 println("查看调用顺序A") 3 def m(s:String) = println(s"A($s)") 4 } 5 trait B extends A{ 6 println("查看调用顺序B") 7 override def m(s:String) = super.m(s"B($s)") 8 } 9 trait C extends A{ 10 println("查看调用顺序C") 11 override def m(s:String) = super.m(s"C($s)") 12 } 13 trait D extends A{ 14 println("查看调用顺序D") 15 override def m(s:String) = super.m(s"D($s)") 16 } 17 trait E extends C{ 18 println("查看调用顺序E") 19 override def m(s:String) = super.m(s"E($s)") 20 } 21 trait F extends C{ 22 println("查看调用顺序F") 23 override def m(s:String) = super.m(s"F($s)") 24 } 25 class G extends D with E with F with B{ 26 println("查看调用顺序G") 27 override def m(s:String) = super.m(s"G($s)") 28 } 29 object t{ 30 def main(args: Array[String]): Unit = { 31 val x = new G 32 x.m("") 33 } 34 }
这段代码最后的输出结果是:
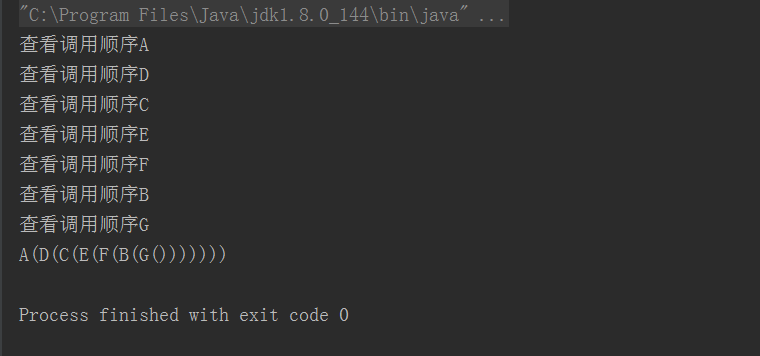
为什么呢?
G extends D with E with F with B
D extends A
E extends C,C extends A
F extends C,C extends A
B extends A
1.从左往右,选择离G的trait最近的进行放置在左边,他的父类放在右边
2.依次将剩下的trait的也从左边开始放置,如果其父类已经出现在右边,则跳过
3.在最右加入AnyRef和Any,完成构建
1.GDA
2.GECDA
3.GFECDA
4.GBFECDA