计划真的赶不上变化,时间过得真快。废话不多说了,今天主要记录之前有同事遇到的一些坑分享出来。
一、封装类的应用会引起NPE异常
对于其他对象的应用,一般在使用之前会判断它是否为空,如果不为空才会使用它以及它里面的一些属性值。但是对于基本类型的封装类型,就有很多人漏掉对于它的判断。
就在前面几天有位同事问我说这段代码它怎么会报空指针呢? 先模拟下这个场景下的代码:
// 第三方的实体类对象 class Count{ Integer total; String name; String leavingNum; //... } public class DemoTest { public void fun() { Count count = new Count(); // 经过一系类对应值的获取之后 // 需要判断total是否为0,如果为0就进行其他的业务操作。 if (count.total == 0) { // 比方说打印日志。 } } @Test public void test() { fun(); } }
他给我看的代码就是类似fun()方法中的代码, 我一看这个代码就感觉不对劲,我说你这个Count类下的total属性是int吗?如果是int就可以这么用。他说为什么? “如果是Integer类型,那么它的初始值不是0而是null, 而你上面的这些逻辑又不能保证total 一定会获取到数值,那么它就还有可能是null,你这样使用的话就有可能包NPE的问题。所以针对对象的使用提前判空更有保障。” 我接着说。 在我说的过程中他反应还是很快的,立马查看了这个实体类中total字段的类型,于是就明白了。 如果没有养成提前使用判空的习惯(除非你能保证一定会有值),老手都容易会踩这样的坑。比方说针对Boolean类型的使用,有很多人会直接这样的哦(这样肯定会有问题的)。
Boolean flag = null; // 经过一系类操作处理 // 进行判断 if (flag) { //...... }
另外针对基本类型的封装类型使用还有些要注意的请看这篇文章:https://www.cnblogs.com/yuanfy008/p/8321217.html
二、subList带来的隐患
现在有很多都是基于分布式服务,那应该会存在这个域对应数据需要同步到其他域下,然后这种同步必然会产生差异,需要一种自检的job去检测差异。打个比方有些商家自己有官网售卖自己的产品,也还有可能会在天猫开旗舰店售卖。假如它分配在天猫的商品信息是通过它本地天猫数据库同步过去的,那么这种难免会产生差异,特别是库存,如果一边多一边少就可能会导致超卖的情况。 所以这种情况需要有个job对比两边的差异,下面先简单模拟下事发情况(注意下面的用法):
1 public class SubListTest { 2 3 @Test 4 public void test1() { 5 // 初始集合(有序) 6 List<Integer> list = new ArrayList<>(); 7 list.addAll(Arrays.asList(1, 2, 3, 4)); 8 9 // 业务场景:需要将list集合与很多场景下的数据进行对比,然后取出不同的。 10 // 对比的场景就不还原了,假设每次都是前面两个不同。 这里只列举四次对比,为了方便查看效果不使用for循环 11 12 // 第一次截取不同的数据 13 list = list.subList(0, 2); 14 // 查看list中有多少数据 15 System.out.println(list); 16 17 // 查询有新的数据,往list中添加 18 list.addAll(Arrays.asList(5, 6)); 19 //... 20 // 第二次截取 21 list = list.subList(0, 2); 22 System.out.println(list); 23 24 // 查询有新的数据,往list中添加 25 list.addAll(Arrays.asList(7, 8)); 26 //... 27 // 第三次截取 28 list = list.subList(0, 2); 29 System.out.println(list); 30 31 // 查询有新的数据,往list中添加 32 list.addAll(Arrays.asList(9, 10)); 33 //... 34 // 第四次截取 35 list = list.subList(0, 2); 36 System.out.println(list); 37 38 } 39 }
看到上面代码其实很简单,输出结果大家也都知道。下面先一步一步的分析,然后再介绍在大量数据的情况下这会产生结果。
第一步:查看下list的内存分配地址,后面会有需要。
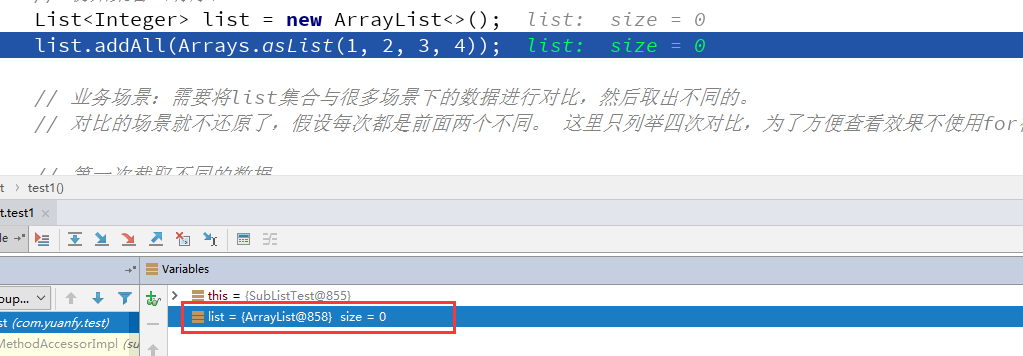
第二步:跳到第一次截取之后,看list有什么变化? 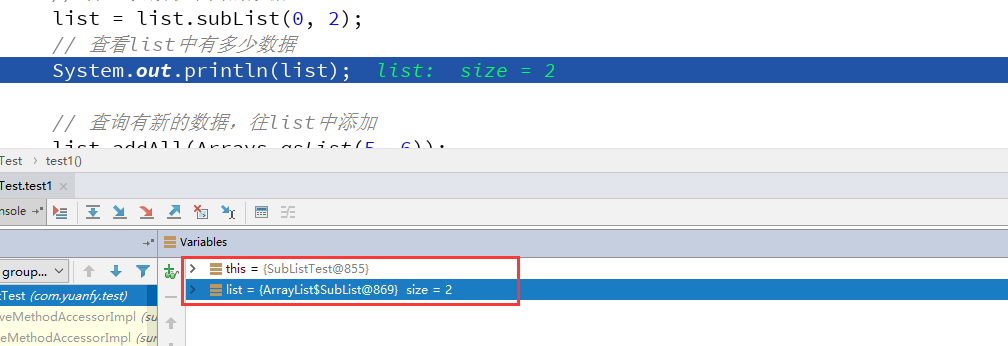
它的内存地址变了,也就说每次subList都会产生一个新对象,那么得查看下这subList的源码,而源码中确实是会产生一个新对象。但是请仔细SubList的构造函数,其中会存放它的父级对象。那么这会产生什么影响呢?请接着往下看。
public List<E> subList(int fromIndex, int toIndex) { subListRangeCheck(fromIndex, toIndex, size); return new SubList(this, 0, fromIndex, toIndex); } private class SubList extends AbstractList<E> implements RandomAccess { private final AbstractList<E> parent; private final int parentOffset; private final int offset; int size; SubList(AbstractList<E> parent, int offset, int fromIndex, int toIndex) { this.parent = parent; this.parentOffset = fromIndex; this.offset = offset + fromIndex; this.size = toIndex - fromIndex; this.modCount = ArrayList.this.modCount; } // 后面方法省略 }
第三步:在第三次截取之前直接在源码中SubList构造函数中打断点,然后跳转进来,看看对应对象的属性值:
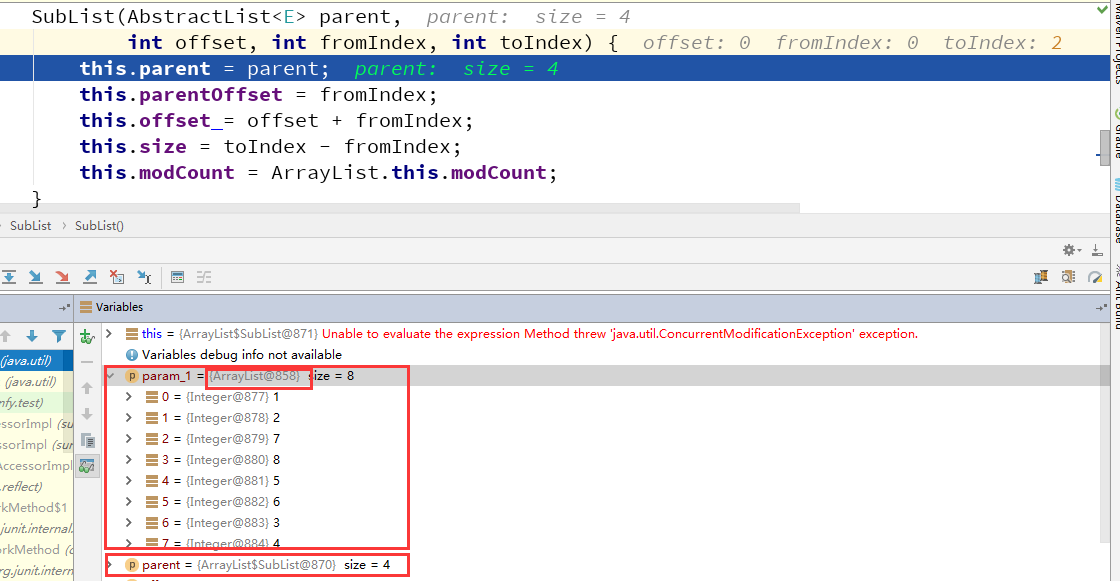
咋一看,这里面怎么param_1怎么来的?通过第二步查看SubList的源码再加上第一步的需要你留意list原生的的对象内存地址,你就知道param_1对应是这个list的根对象,它一直保留子对象新增的对象。那么大家想下,这种做法当遇到海量数据对比差异时会产生什么影响呢?
如果刚才看懂了上面所说的,那么肯定会明白这个list的根对象累积到后面肯定会变成大对象,这样会导致平凡的fullGc而且你还回收不掉。因为它一直在使用,直至这个程序运行结束。
那么像上面这种场景怎么优化解决呢? 可以这样考虑, 每次对比时候都弄一个新的list去获取差异,然后再把这个有差异的list添加至总的差异结果集中。(其实我们平时也不会用一个list去反反复复的subList)。如果大家有更好的优化,请留言探讨。