一、什么是ik分词器
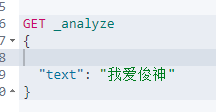
分词∶即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱俊神"”会被分为"我"、"爱"、"俊"、"神"这显然是不符合要求的,所以我们需要安装中文分词器永来解决这个问题,
IK提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,k_max_word为最细粒度划分!一会我们测试!
比如
二、ik分词器安装
2.1、下载地址
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases 下载7.6.1版
2.2、安装
(1)创建一个文件夹为ik,将其解压到ik文件夹中
(2)将ik文件夹拷贝到elasticsearch/plugins 目录下。
(3)重新启动,即可加载IK分词器

三、ik分词器测试
3.1、测试


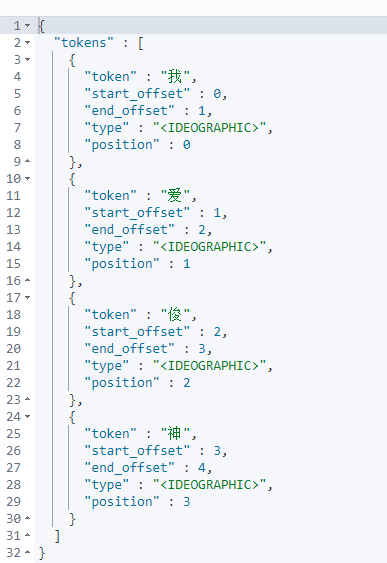
#输入 GET _analyze { "analyzer": "ik_smart", "text": "我爱中国五星红旗" } #输出 { "tokens" : [ { "token" : "我", "start_offset" : 0, "end_offset" : 1, "type" : "CN_CHAR", "position" : 0 }, { "token" : "爱", "start_offset" : 1, "end_offset" : 2, "type" : "CN_CHAR", "position" : 1 }, { "token" : "中国", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 2 }, { "token" : "五星红旗", "start_offset" : 4, "end_offset" : 8, "type" : "CN_WORD", "position" : 3 } ] }
#输入 GET _analyze { "analyzer": "ik_max_word", "text": "我爱中国五星红旗" } #输出 { "tokens" : [ { "token" : "我", "start_offset" : 0, "end_offset" : 1, "type" : "CN_CHAR", "position" : 0 }, { "token" : "爱", "start_offset" : 1, "end_offset" : 2, "type" : "CN_CHAR", "position" : 1 }, { "token" : "中国", "start_offset" : 2, "end_offset" : 4, "type" : "CN_WORD", "position" : 2 }, { "token" : "五星红旗", "start_offset" : 4, "end_offset" : 8, "type" : "CN_WORD", "position" : 3 }, { "token" : "五星", "start_offset" : 4, "end_offset" : 6, "type" : "CN_WORD", "position" : 4 }, { "token" : "五", "start_offset" : 4, "end_offset" : 5, "type" : "TYPE_CNUM", "position" : 5 }, { "token" : "星", "start_offset" : 5, "end_offset" : 6, "type" : "CN_CHAR", "position" : 6 }, { "token" : "红旗", "start_offset" : 6, "end_offset" : 8, "type" : "CN_WORD", "position" : 7 } ] }
3.2、发现问题
有些我们想自己需要的词但是被拆开了,这就不符合我们所需要的


3.3、解决
我们需要在ik配置中增加我们自己想要的dict
目录- ik/config/IKAnalyzer.cfg.xml 中增加自己配置的文件
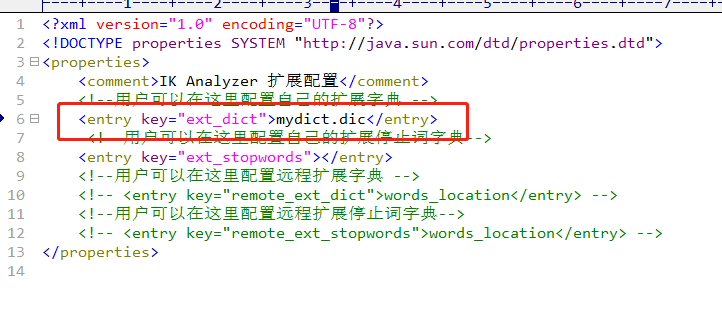
mydict.dic

配置完之后重启,证明加载ok
