为什么要有索引?
如果一张数据库表只有区区几千,几百条记录,那不必创建索引,因为索引也会占用内存空间,但是,当一张表有百万条记录时,当需要查询一个数据时(而且实际情况是对于一张数据库表的大部分操作都是查询),
如果没有索引,就需要一条一条数据进行比较,耗费大量时间。比如查字典的是时候我们一般都不会直接查,而是利用目录进行快速定位,索引也是这个意思。
索引的数据结构:
索引的数据结构是一颗b+tree,树中的非叶子结点存的是一条记录中的某个字段,叶子结点存放记录值(不一定是一整条记录),
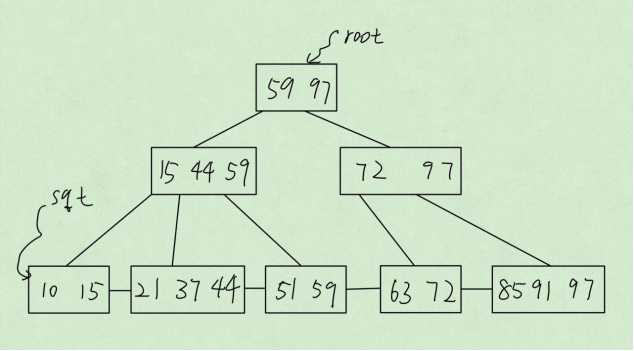
如图,若要查询的数据是21,先从根节点出发,根节点作为一个磁盘块,一次性加载到内存中,如何对其中的数据进行二分查找,因为21<59,所以向左继续查找,之后同理查询,知道叶子结点。
在这个过程中,将叶子节点加载到内存中是最耗费时间的(磁盘IO操作),在内存中进行的二分查找节点中的值可以忽略不计。因此,b+树的查询效率取决于树的高度。
如何能将b+tree的高度降低?
b+tree的每一个节点(磁盘块)的大小是固定的,因此同样的数据量想要用更矮的b+tree存储,就得想办法减小存入的每一个数据的大小,是的每一个节点能存下更多的字段,
然而存入叶子节点字段的大小不能改变,就想办法减小存入非叶子节点的字段的大小,因此索引字段一般为int。
还得尽量选择区分度高的字段做索引,若区分度太低,如性别,b+树将会退化为线性的树。
若选用自增的字段作为索引字段,还可以减少因重构b+tree所消耗的资源(时间资源,CPU资源)
索引分类:
1.聚集索引:由主键作为索引字段的b+tree,叶子结点存放了每一个字段所对应的一整条记录信息
2.辅助索引:非主键作为索引字段的b+tree,叶子结点只存放了索引字段和其对应的主键信息,查询一条记录的信息,先在使用辅助索引查询到对应主键信息,之后再使用聚集索引进行查询;
若需要查询的信息就是主键,则只需要是使用辅助索引进行查询,无需再次使用聚集索引查询。
MySQL中常见索引:
普通索引INDEX:加速查找
唯一索引:
-主键索引PRIMARY KEY:加速查找+约束(不为空、不能重复)
-唯一索引UNIQUE:加速查找+约束(不能重复)
联合索引:
-PRIMARY KEY(id,name):联合主键索引
-UNIQUE(id,name):联合唯一索引
-INDEX(id,name):联合普通索引
优秀文章:
https://www.cnblogs.com/fengqiang626/archive/2019/09/04/11459434.html