初学siameseNet网络,希望可以用于信号的识别分类应用。此文为不间断更新的笔记。
siameseNet简介
全连接孪生网络(siamese network)是一种相似性度量方法,适用于类别数目多但是每类的样本数少的分类问题。
Siamese Network 是一种神经网络的框架,而不是具体的某种网络,就像seq2seq一样,具体实现上可以使用RNN也可以使用CNN。
简单的说,Siamese Network用于评估两个输入样本的相似度。网络框架:
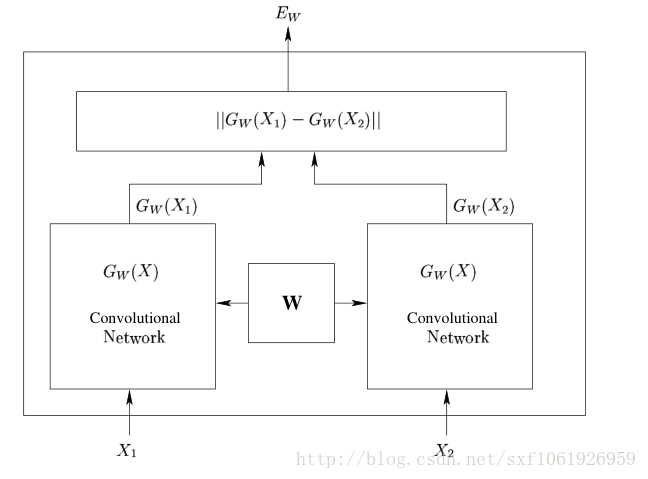
Siamese Network有两个结构相同,且共享权值的子网络。分别接收两个输入X1 与X2 ,将其转换为向量Gw(X1) 与Gw(X2) ,再通过某种距离度量的方式计算两个输出向量的距离Ew 。
训练Siamese Network采用的训练样本是一个tuple (X1,X2,y) ,标签y=0 表示X1 与X2 属于不同类型(不相似、不重复、根据应用场景而定)。y=1 则表示X2 与X2 属于相同类型(相似)。
LOSS函数的设计应该是:
1. 当两个输入样本不相似(y=0
)时,距离Ew
越大,损失越小,即关于Ew
的单调递减函数。
2. 当两个输入样本相似(y=1
)时,距离Ew
越大,损失越大,即关于Ew
的单调递增函数。
Loss函数怎么定义,其实就是Logistic Regression的Loss函数,这里值得注意的是最后一层的激活函数要用Sigmoid Function。Loss函数如下:
![]()
用L+(X1,X2) 表示y=1 时的LOSS, L−(X1,X2) 表示y=0 时的LOSS,则LOSS函数可以写成如下形式
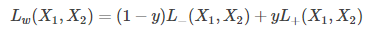
总结下来:
1、输入不再是单个样本,而是一对样本,不再给单个的样本确切的标签,而且给定一对样本是否来自同一个类的标签,是就是0,不是就是1
2、设计了两个一模一样的网络,网络共享权值W,对输出进行了距离度量,可以说l1、l2等。
3、针对输入的样本对是否来自同一个类别设计了损失函数,损失函数形式有点类似交叉熵损失。
最后使用获得的损失函数,使用梯度反传去更新两个网络共享的权值W。
这个网络主要的优点是淡化了标签,使得网络具有很好的扩展性,可以对那些没有训练过的类别进行分类,这点是优于很多算法的。而且这个算法对一些小数据量的数据集也适用,变相的增加了整个数据集的大小,使得数据量相对较小的数据集也能用深度网络训练出不错的效果。
实验的时候要注意,输入数据最好打乱,由于这样去设计数据集后,相同类的样本对肯定比不相同的样本对数量少,在进行训练的时候最后将两者的数据量设置成相同数量。
参考
https://blog.csdn.net/thriving_fcl/article/details/73730552
https://github.com/ardiya/siamesenetwork-tensorflow
https://blog.csdn.net/sxf1061926959/article/details/54836696
https://www.jianshu.com/p/1df484d9eba9?utm_source=oschina-app