Boosting
是一种从一些弱分类器中创建一个强分类器的集成技术(提升算法)。
它先由训练数据构建一个模型,然后创建第二个模型来尝试纠正第一个模型的错误。不断添加模型,直到训练集完美预测或已经添加到数量上限。
Bagging与Boosting的区别:取样方式不同。Bagging采用均匀取样,而Boosting根据错误率取样。Bagging的各个预测函数没有权重,而Boosting是由权重的,Bagging的各个预测函数可以并行生成,而Boosing的哥哥预测函数只能顺序生成。
AdaBoost算法的全称是自适应boosting(Adaptive Boosting),是一种用于二分类问题的算法,它用弱分类器的线性组合来构造强分类器。弱分类器的性能不用太好,仅比随机猜测强,依靠它们可以构造出一个非常准确的强分类器。
AdaBoost是为二分类开发的第一个真正成功的Boosting算法,同时也是理解Boosting的最佳起点。目前基于AdaBoost而构建的算法中最著名的就是随机梯度boosting。
AdaBoost
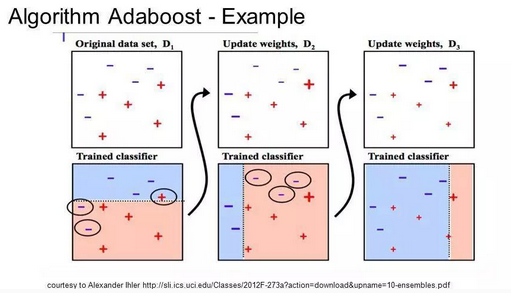
Adaboost(Adaptive Boosting, R.Scharpire1996)是一种迭代算法。
核心思想:针对同一个训练集训练不同的分类器(弱分类器),然后集合弱分类器构成更强的最终分类器(强分类器)。 Adaboost算法本身通过改变数据分布实现,根据每次训练集中每个样本是否分类正确以及上次总体分类的准确率来确定每个样本的权值。将修改过的权值的新数据送给下层分类器训练,最后将每次得到的分类器融合起来,作为最后的决策分类器。
常与短决策树一起使用。在创建第一棵树之后,每个训练实例在树上的性能都决定了下一棵树需要在这个训练实例上投入多少关注。
难以预测的训练数据会被赋予更多的权重,而易于预测的实例被赋予更少的权重。
模型按顺序依次创建,每个模型的更新都会影响序列中下一棵树的学习效果。
在建完所有树之后,算法对新数据进行预测,并且通过训练数据的准确程度来加权每棵树的性能。
因为算法极为注重错误纠正,所以一个没有异常值的整洁数据十分重要。
AdaBoost的实现是一个渐进的过程,从一个最基础的分类器开始,每次寻找一个最能解决当前错误样本的分类器。用加权取和(weighted sum)的方式把这个新分类器结合进已有的分类器中。
它的好处是自带了特征选择(feature selection),只使用在训练集中发现有效的特征(feature)。这样就降低了分类时需要计算的特征数量,也在一定程度上解决了高维数据难以理解的问题。
最经典的AdaBoost实现中,它的每一个弱分类器其实就是一个决策树。这就是之前为什么说决策树是各种算法的基石。
集成学习
AdaBoost算法是一种集成学习(ensemble learning)方法。集成学习是机器学习中的一类方法,它对多个机器学习模型进行组合形成一个精度更高的模型,参与组合的模型称为弱学习器(weak learner)。在预测时使用这些弱学习器模型联合起来进行预测;训练时需要用训练样本集依次训练出这些弱学习器。典型的集成学习算法是随机森林和boosting算法,而AdaBoost算法是boosting算法的一种实现版本。