分类和决策树(DT)。
决策树是预测建模机器学习的一种重要算法。
决策树模型的表示是二叉树。就是算法和数据结构中的二叉树,没什么特别的。每个节点表示一个单独的输入变量(x)和该变量上的左右孩子(假设变量为数值)。
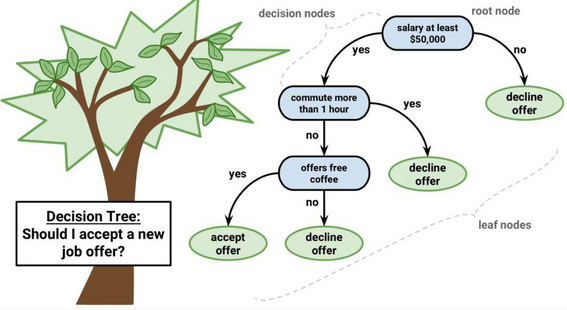
树的叶节点包含一个输出变量(y),用于进行预测。通过遍历树,直到到达叶节点并输出叶节点的类值,就可以做出预测。
树的学习速度很快,预测的速度也很快。它们通常也适用于广泛的问题,不需要对数据进行任何特别的准备。
决策树有很高的方差,并且可以在使用时产生更准确的预测。
特点及应用
决策树的特点是它总是在沿着特征做切分。随着层层递进,这个划分会越来越细。
虽然生成的树不容易给用户看,但是数据分析的时候,通过观察树的上层结构,能够对分类器的核心思路有一个直观的感受。
举个简单的例子,当我们预测一个孩子的身高的时候,决策树的第一层可能是这个孩子的性别。男生走左边的树进行进一步预测,女生则走右边的树。这就说明性别对身高有很强的影响。
因为DT能够生成清晰的基于特征(feature)选择不同预测结果的树状结构,数据分析师希望更好的理解手上的数据的时候往往可以使用决策树。
同时它也是相对容易被攻击的分类器。这里的攻击是指人为的改变一些特征,使得分类器判断错误。常见于垃圾邮件躲避检测中。因为决策树最终在底层判断是基于单个条件的,攻击者往往只需要改变很少的特征就可以逃过监测。
受限于它的简单性,决策树更大的用处是作为一些更有用的算法的基石。
优点:
1.概念简单,计算复杂度不高,可解释性强,输出结果易于理解;
2.数据的准备工作简单, 能够同时处理数据型和常规型属性,其他的技术往往要求数据属性的单一。
3.对中间值得确实不敏感,比较适合处理有缺失属性值的样本,能够处理不相关的特征;
4.应用范围广,可以对很多属性的数据集构造决策树,可扩展性强。决策树可以用于不熟悉的数据集合,并从中提取出一些列规则 这一点强于KNN。
缺点:
1.容易出现过拟合;
2.对于那些各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征。
3. 信息缺失时处理起来比较困难。 忽略数据集中属性之间的相关性。