文章[1]主要针对的是语句长度不定,含有不相关信号的说话人识别。
深度网络设计的关键在于主干(帧级)网络的类型【the type of trunk (frame level) network】和有时间序列属性的聚合方法【the method of temporal aggregation】。
文中提出了一个强大的说话人识别深度网络,使用了一个“thin-ResNet” 网络结构,以及一个基于字典的NetVLAD[2]或者GhostVLAD层去在时间轴上聚合特征,这个可端到端训练。
文中实验在VoxCeleb1测试集上进行,证明该方法只需要更少的参数,并且SR(speaker recognition)性能优越。同时,调研了语句长度对网络性能的影响,得到结论:对于in the wild数据,a longer length is beneficial.
算法
对于SR,理想的模型应该有以下特性:1)处理任意长度的输入,得到一个定长的utterance-level descriptor;2)输出的descriptor应该是compat的,即低维表述,所需资源少,便于有效存储和恢复;3)输出descriptor应该是discriminative,例如不同说话人的descriptor之间的距离应该比同一说话人的大。
为了满足上述条件,本文采用modified ResNet以全卷积方式来对输入的2-D声谱图进行编码,再使用一个NetVLAD/GhostVLAD层,沿时间轴进行特征聚合。这会产生定长的输出描述符。直观上,VLAD层可以被认为可训练的判别聚类:每一个帧级别的描述符都会被softly分配到不同的clusters,剩下的会被编码成为output features。为了有效验证(低内存、相似度快速计算),文章进一步加了一个全连接层用于降维。因为整个网络是端到端进行SR的,所以可以产生discriminative representations。网络具体见图1。
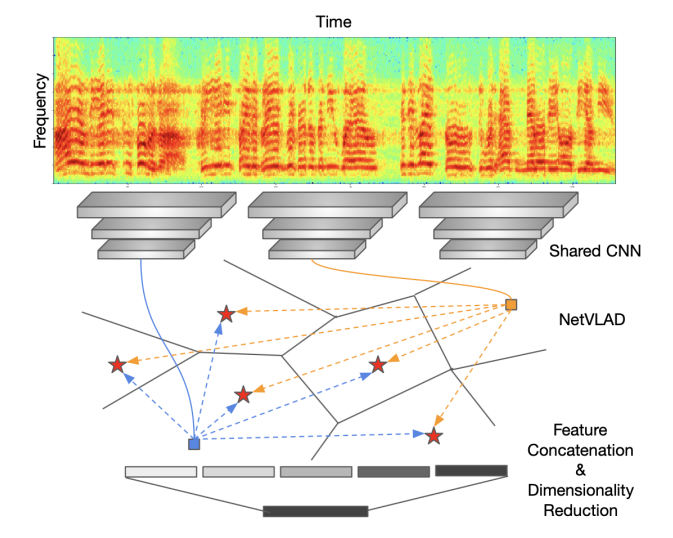
图1:文中的网络结构。由两部分构成:特征提取(a shared CNN用于对spectrogram进行编码)+聚合(aggregates all the local descriptors into a single compact representation of arbitrary length)
博客[3]中简单总结了该网络:
| 输入:每帧257维向量,256维的频率量+1维的DC量 |
| 主干网络:Thin-ResNet,提取frame-level特征 |
| NetVLAD或GhostVLAD层:将frame-level的特征转换成utterance-level特征。大多数算法是采用Average pooling层直接对帧维度进行平均,这样做的缺点是每帧的weight是一样的,但是实际上每帧对结果的contribution肯定是不一样的,比如有说话的帧肯定比没说话帧的contribution高,本文采用的方法其实是自动学习给予每帧不同的权重。 |
| trainning loss:标准的softmax loss和additive margin softmax(AM-Softmax) |
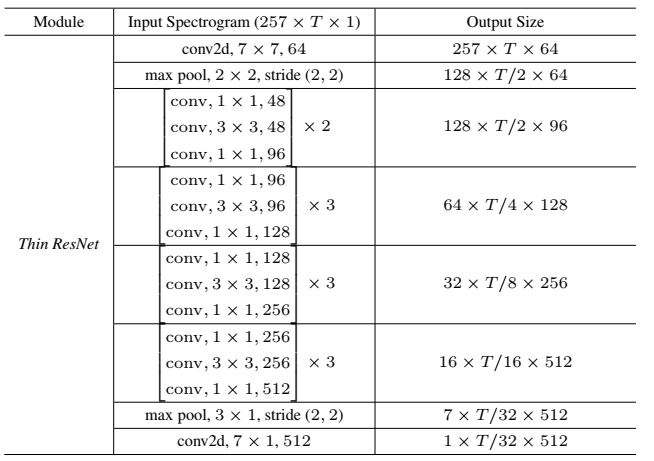
表1:用于帧级别特征提取的thin-ResNet。并未展示ReLU和batch-norm layers。每一行表示卷积滤波器的数目、尺寸、以及滤波器数目。这个结构只有3 million参数,而标准的ResNet-34有22 million个参数。
特征提取
第一步就是从声谱图中提取特征。当然任意网络都可以用于本文的learning framework,作者选择了a modified ResNet-34。和之前使用的标准ResNet比较,我们减少了每个residual block的通道数目,得到一个thin ResNet-34(见表1)。
NetVLAD
网络的第二部分使用NetVLAD[2]来将帧级别的descriptors聚合为一个句子级别的向量。本小节简单介绍了NetVLAD。上述thin-ResNet将输入的声谱图![]() 映射为帧级别的descriptors,尺寸为
映射为帧级别的descriptors,尺寸为![]() 。然后NetVLAD层将dense descriptors作为输入,并生成一个K*D维的矩阵V,其中K是chosen cluster的数目,D是每个cluster的维度。具体来说,descriptors矩阵V通过下式计算得到:
。然后NetVLAD层将dense descriptors作为输入,并生成一个K*D维的矩阵V,其中K是chosen cluster的数目,D是每个cluster的维度。具体来说,descriptors矩阵V通过下式计算得到:
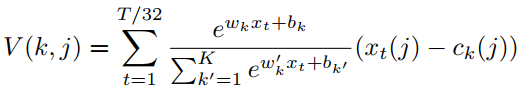 (1)
(1) ![]()
第一项对应于簇k的输入向量xi的软赋值权,第二项计算向量与簇中心之间的残差。最终输出是通过L2规范化和级联得到的。为了保持较低的计算和内存,通过全连接(FC)层降维,选择输出维数为512。
我们还对最近提出的GhostVLAD层进行了实验,其中some clusters没有包含在最终级联中,因此不参与最终表达,这些集群称为“ghost clusters”(我们在实现中使用了两个)。因此,在聚合帧级特征时,语音段中噪声和非目标部分对正常VLAD clusters的贡献实际上是down-weight的,因为它们的大部分权重都分配给了“ghost集群”。
实验
数据集
文章在数据集VoxCeleb2(仅在“dev”分区上,其中包含5994位发言者的讲话)上训练了一个端到端的模型用于验证,在VoxCeleb1的验证测试集上进行测试。注意,VoxCeleb2的开发集与VoxCeleb1数据集是不相交的(即没有共同的说话人)。
训练损失函数
除了标准的softmax损失外,我们还在训练时进行了additive margin softmax(AM-Softmax)分类损失的实验,这种损失是通过在角空间中引入margin来提高验证性能,计算方式如下:
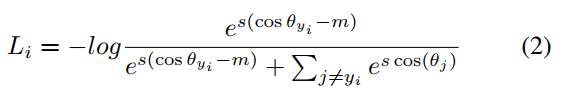
其中Li指的是样本被分类到正确类的成本,θy = arccos (wTx) 是指样本特征(x)和决策超平面(w)之间的角度,这两个向量都已经被L2正则化。目的是通过使cos(θyi)−m尽可能大,来最小化这个角。其中m指的 angular margin。超参数s控制着softmax loss的“temperature”,对分离得好的样本,产生更高的梯度(并进一步缩小类内方差)。文章采用默认值m=0.4和s=30。
训练细节
训练过程中,文章使用一个固定尺寸的spectrogram对应一个2.5秒的时间片,这个时间片从每个语句中随机抽取。
spectrograms由一个滑动的汉明窗(窗长25ms,步长10ms)生成。文章采用512点FFT,得到256个频谱分量,再加上每帧的直流分量,则每2.5秒的数据就会得到257×250(频率×时间)的短时傅里叶变换(STFT)。
spectrogram通过在每个时间步长去均值并除以标准差进行归一化的(数据变成均值为0,方差为1)。不需要VAD或者自动移除静音段。
文章使用初始学习率为10-3的Adam 优化器,每36个epochs后学习率除以10?直到收敛。
结果及分析
首先对比了使用不同loss训练的NetVLAD和GhostVLAD架构的性能,然后研究语句的长度对于性能的影响。
VoxCeleb1上的验证
从VoxCeleb1数据集中选取三个不同的测试列表对训练后的网络进行评估:(1)原始的VoxCeleb1测试集,包含40个说话者;(2)扩展的VoxCeleb1- E列表,使用整个VoxCeleb1(训练和测试分割)进行评估;(3)具有挑战性的VoxCeleb1-H列表,其中,测试对来自具有相同性别和国籍的身份。
此外,文章发现VoxCeleb1-E和VoxCeleb1-H列表中有少量错误,因此也对这两个列表的清理版本进行了评估,并公开发布。该网络在测试语句段的整个长度上进行测试。测试时间增加,可能会导致性能的轻微提高,但文章未使用任何的测试时间增量。
表2比较了文中模型与当前先进算法在原始VoxCeleb1测试集的性能,实验表明文中算法性能最优。采用标准的softmax loss和NetVLAD聚合层,性能显著优于原始的基于Resnet的架构(EER为3.57% vs. 4.19%),同时所需的参数要少得多(1000万 ?vs. 2600万)。将标准softmax loss替换为additive margin softmax (AM-Softmax),进一步提高了性能(EER=3.32%)。GhostVLAD层将无关信息排除在聚合之外,再次提升了性能(EER=3.22%)。
VoxCeleb1-H这个测试集非常有挑战性,文章中的方法比原来ResNet-based架构也好了很多(EER,5.17% vs 7.33%)。与文中网络最相似的架构是基于字典的方法,文中方法的性能也超过了它(3.22% vs 4.48%)。
文章发现,基于temporal average pooling(TAP)特征的softmax loss训练的结果非常差(EER为10.48%)。推测是因为从TAP得到的特征通常在优化类内差异方面表现比较好(即分开不同的说话人),但不擅长降低类内变化(即,使相同说话人的特征更加紧凑)。因此,如TAP所示,contrastive loss with online hard sample mining 导致了显著的性能提升。这也有可能提高NetVLAD/GhostVLAD池化的性能。
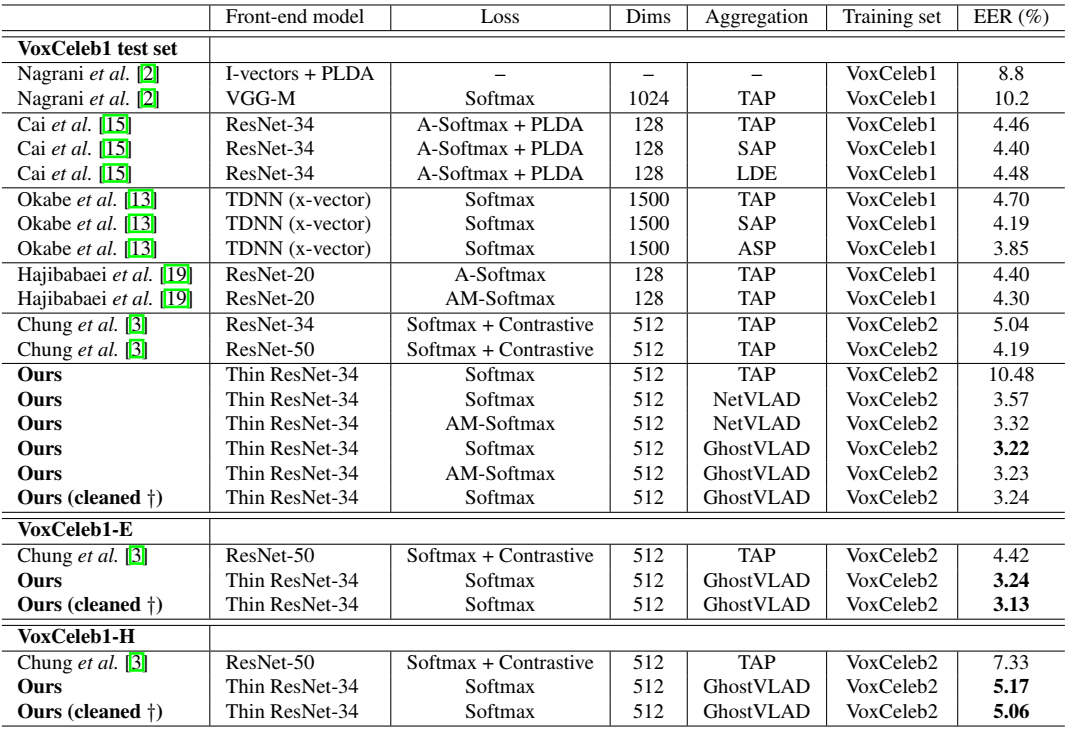
表2:原始VoxCeleb1测试集、VoxCeleb-E和VoxCeleb-H的验证结果。其中TAP表示时序平均池化;SAP表示自关注池化层。
关于GhostVLAD的实验
表3研究了GhostVLAD层的clusters数目的影响。证明了VLAD聚合非常鲁棒(对于clusters数目以及两个不同的loss函数而言) 。
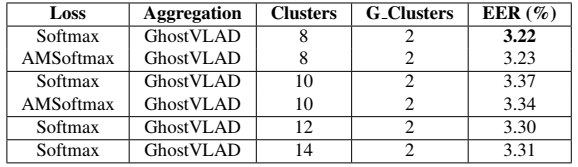
表3:在原始VoxCeleb1测试集上的验证结果。所有模型都采用了相同的Thin Resnet-34结构,并且变化VLAD clusters数目和loss函数。
数据长度的性能测试
表4展示了不同测试数据段长度对SR性能的影响。为了对最长6秒的长度进行充分比较,文章中将测试数据集(VoxCeleb1)限制为6秒或更长(87,010个片段,占总数据集的56.7%)。为了生成验证对,对于VoxCeleb1数据集中的每个说话者(总共1251个说话者),随机抽取100个正对和100个负对,得到25,020个验证对?测试期间,每个验证对,随机裁剪出长度为2s、3s、4s、5s和6s的片段。实验重复三次,并且计算均值和标准差。
 表4:不同长度语句下的算法性能
表4:不同长度语句下的算法性能
如表4所示,验证集的性能与序列长度确实存在很强的相关性。对于in the wild 序列来说,有的数据有可能是noise、静音、或者非目标人语音,并且一个短序列有可能很不幸地被这些不相关的信息占据主要。 随着时间长度的增加,也更有可能从目标说话人那里捕获相关语音信息。
结论
本文提出了一个强大的说话人识别网络,使用一个“thin-Resnet”主干架构,以及一个基于字典的NetVLAD和GhostVLAD层来跨时间聚合,可以进行端到端训练。该网络在VoxCeleb1测试集上实现了最优的说话人识别性能,同时比以前的方法需要更少的参数。文章还研究了语句长度对性能的影响,并得出结论,对于in the wild数据,更长的长度是有益的。
参考
[1] Xie W , Nagrani A , Chung J S , et al. Utterance-level Aggregation For Speaker Recognition In The Wild[J]. 2019.
[2] Arandjelovic R , Gronat P , Torii A , et al. NetVLAD: CNN architecture for weakly supervised place recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.