Spark内容
1.Spark的内存模型 2.Spark的执行过程 3.SparkSQL的执行过程
本次主要整理内存模型相关内容
Spark的内存模型
1.Spark2.0采用的是统一内存管理方式 unified Memory Manager
01.特点是: 存储内存和计算内存在同一空间,并且可以动态的使用彼此的空闲区域
02.构成: 内存分为堆内内存和堆外内存
001.堆外内存式由Spark控制,直接在工作节点的系统内存中开辟空间,即对于大内存,Spark自行和内存打交道
堆外内存只区分 Execution 内存和 Storage 内存
这部分用户代码无法直接操作。 堆外内存部分主要用于JVM自身,如字符串、NIO Buffer等开销,
另外还有部分堆外内存由spark.memory.offHeap.enabled及spark.memory.offHeap.size控制的堆外内存,这部分也归offheap,
但主要是供统一内存管理使用的。
002.堆内内存依赖JVM,
– Execution Memory Execution 内存 主要用于存放 Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据
– Storage Memory Storage 内存 主要用于存储 spark 的 cache 数据,例如RDD的缓存、unroll数据
– User Memory 用户内存(User Memory) 主要用于存储 RDD 转换操作所需要的数据,例如 RDD 依赖等信息
– Reserved Memory 预留内存(Reserved Memory) 系统预留内存,会用来存储Spark内部对象
动态占用-- 存储内存和计算内存 一般我们使用的Spark.driver.memory 和 spark.executor.memory
Spark在一个Executor中的内存分为三块,一块是execution内存,一块是storage内存,一块是other内存
storage memory 和 Executor memory
Executor memory: 主要存储Shuffle、Join、Sort、Aggregation等计算过程中的临时数据;
2. 驱动器和执行器功能
Driver和Executor都是JVM进程,内存由MemoryManager统一管理
Driver的功能
1)一个Spark作业运行时包括一个Driver进程,也是作业的主进程,具有main函数,
并且有SparkContext的实例,是程序的人口点;
2)功能:负责向集群申请资源,向master注册信息,负责了作业的调度,
负责作业的解析、生成Stage并调度Task到Executor上。包括DAGScheduler,TaskScheduler
Executor
01.Executor 的内存管理建立在 JVM 的内存管理之上
Executor 内运行的并发任务共享 JVM 堆内内存,这些内存被规划为 存储(Storage)内存 和 执行(Execution)内存
一块儿是专门用来给RDD的cache、persist操作进行RDD数据缓存用的;
另外一块儿,用来给spark算子函数的运行使用的,存放函数中自己创建的对象
02. Executor 堆外内存
3.内存溢出有两点:
1. Driver 内存不够 2. Executor 内存不够
Driver 内存不够: 1. 读取数据太大
2. 数据回传
Executor 内存不够: 1. map 类操作产生大量数据,包括 map、flatMap、filter、mapPartitions 等
2. shuffle 后产生数据倾斜
Driver内存溢出的解决方式:
读取数据太大 增加 Driver 内存,具体做法为设置参数 --driver-memory
collect 大量数据回传 Driver,造成内存溢出:解决思路是 分区输出
Executor内存溢出解决方式
map 过程产生大量对象
解决思路是 减少每个 task 的大小,从而减少每个 task 的输出;
具体做法是在 会产生大量对象的 map 操作前 添加 repartition(重新分区) 方法,分区成更小的块传入 map
解决思路: 用 mapPartitions 替代多个 map,减少 Executor 内存压力
shuffle:
broadcast join
缓存 RDD 既可以节省内存,也可以提高性
DataFrame 代替 RDD
Reduce
增加 reduce 并行度其实就是增加 reduce 端 task 的数量, 这样每个 task 处理的数据量减少,避免 oom
4.数据倾斜
常见的问题解决方式: 发现-- 定位 --确认 --解决
1.数据倾斜
01.什么现象看出有数据倾斜 -发现倾斜 -会看日志
表现一:某个stage运行时间过长
表现二:shuffle read的数据量和shuffle write的数据量相差巨大
表现三:点进stage运行长的,查看task的运行情况 task运行时间过长,读写数据量相差巨大
表现四: 某个executor上运行时间过长
02.哪里出现了倾斜--定位倾斜
哪段代码造成了倾斜,数据倾斜发生在哪一个stage之后,接着我们就需要根据stage划分原理,
推算出来发生倾斜的那个stage对应代码中的哪一部分,这部分代码中肯定会有一个shuffle类算子
(注: 需要了解最基本的stage划分的原理,以及stage划分后shuffle操作是如何在两个stage的边界处执行)
通过DAG图查看
还可以看看 异常栈信息就可以定位到你的代码中哪一行发生了内存溢出。然后在那行代码附近找找
03.怎么解决倾斜-解决倾斜
分析一下那个执行了shuffle操作并且导致了数据倾斜的RDD/Hive表,查看一下其中key的分布情况
数据倾斜: 1. 过滤导致倾斜的 key 2. 使用随机 key 进行双重聚合
3.两阶段聚合(局部聚合+全局聚合)
4.提高shuffle操作的并行度
sample 采样对倾斜 key 单独进行 join
2.资源调优-诊断内存的消耗,针对内存调优
对多次使用的RDD进行持久化或Checkpoint
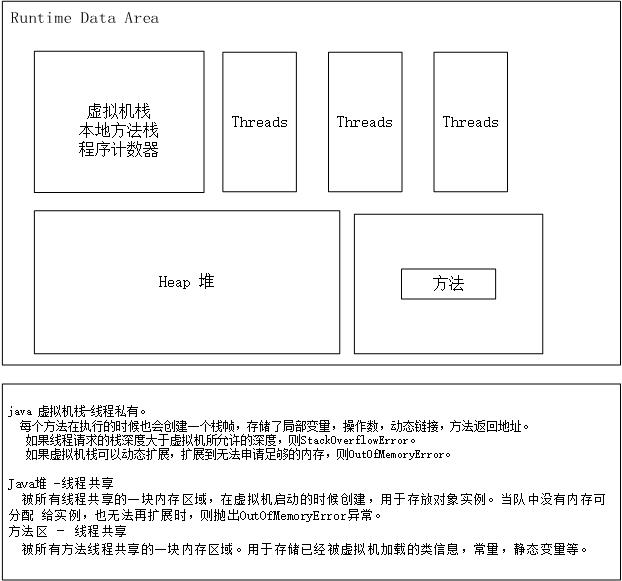
5.Java内存
主要的图例:
参考:
Spark数据倾斜之发现篇 https://blog.csdn.net/dpengwang/article/details/83213825
Spark性能优化指南——高级篇 (很详细) https://blog.csdn.net/lukabruce/article/details/81504220