本文原文链接:https://www.cnblogs.com/wt645631686/p/13189660.html 路漫漫其修远兮,吾将上下而求索
高并发代表着大流量,高并发系统设计的魅力就在于我们能够凭借自己的聪明才智设计巧妙的方案,从而抵抗巨大流量的冲击,带给用户更好的使用体验。这些方案好似能操纵流量,让流量更加平稳得被系统中的服务和组件处理。
而我们在应对高并发大流量时归纳起来共有三种方法。
-
Scale-out(横向扩展):分而治之是一种常见的高并发系统设计方法,采用分布式部署的方式把流量分流开,让每个服务器都承担一部分并发和流量。
-
缓存:使用缓存来提高系统的性能,抵抗高并发大流量的冲击。
-
异步:在某些场景下,未处理完成之前,我们可以让请求先返回,在数据准备好之后再通知请求方,这样可以在单位时间内处理更多的请求。
一、Scale-out
硬件上不断提升CPU性能的方案叫做Scale-up(纵向扩展),把类似CPU多核心的方案叫做Scale-out,这两种思路在实现方式上是完全不同的。
-
Scale-up,通过购买性能更好的硬件来提升系统的并发处理能力,比方说目前系统4核4G每秒可以处理200次请求,那么如果要处理400次请求呢?我们把机器的硬件提升到8核8G(硬件资源的提升可能不是线性的,这里仅为参考)。
-
Scale-out,则是另外一个思路,它通过将多个低性能的机器组成一个分布式集群来共同抵御高并发流量的冲击。沿用刚刚的例子,我们可以使用两台4核4G的机器来处理那400次请求。
那么什么时候选择Scale-up,什么时候选择Scale-out呢?一般来讲,在我们系统设计初期会考虑使用Scale-up的方式,因为这种方案足够简单,所谓能用堆砌硬件解决的问题就用硬件来解决,但是当系统并发超过了单机的极限时,我们就要使用Scale-out的方式。
Scale-out虽然能够突破单机的限制,但也会引入一些复杂问题。比如,如果某个节点出现故障如何保证整体可用性?当多个节点有状态需要同步时,如何保证状态信息在不同节点的一致性?如何做到使用方无感知的增加和删除节点?等等.....
二、缓存
缓存的读取速度快,我们通常使用以内存作为存储介质的缓存,以此提升性能。
三、异步
什么是同步,什么是异步呢?
以方法调用为例,同步调用代表调用方要阻塞等待被调用方法中的逻辑执行完成。这种方式下,当被调用方法响应时间较长时,会造成调用方长久的阻塞,在高并发下会造成整体系统性能下降甚至发生雪崩。
异步调用恰恰相反,调用方不需要等待方法逻辑执行完成就可以返回执行其他的逻辑,在被调用方法执行完毕后再通过回调、事件通知等方式将结果反馈给调用方。
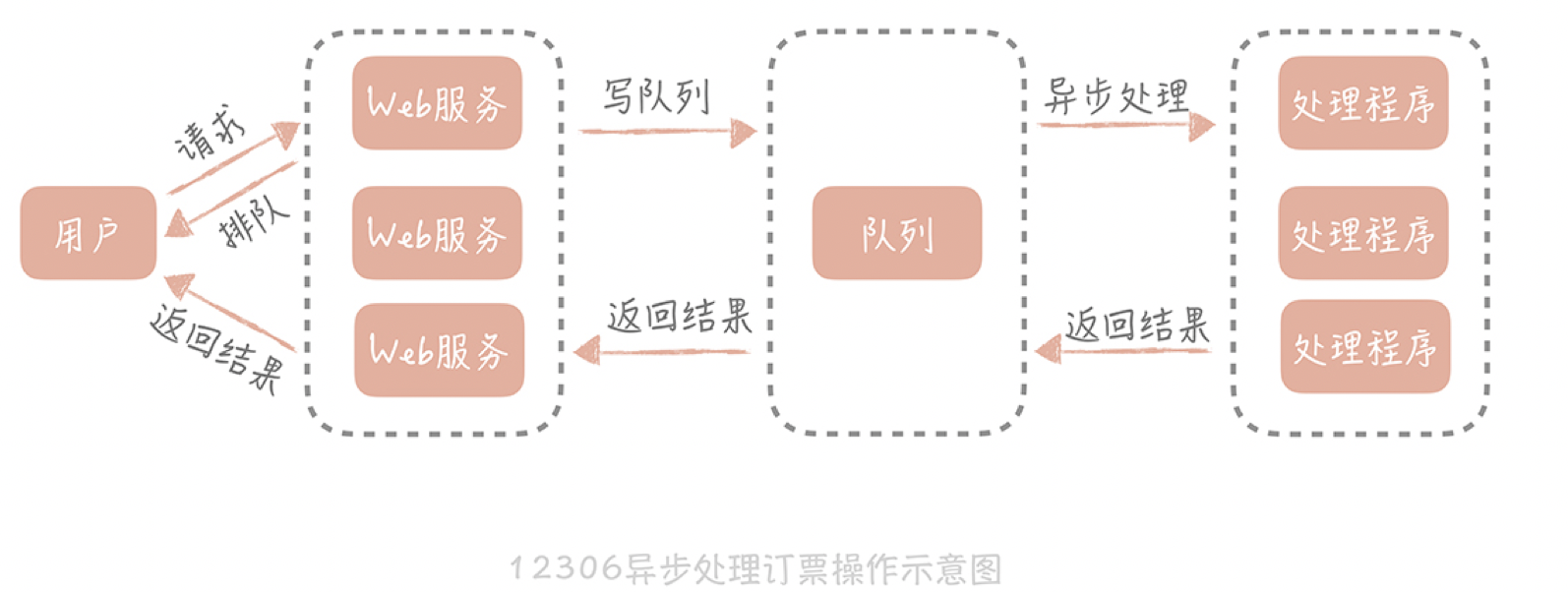
异步的方式,后端处理时会把请求丢到消息队列中,同时快速响应客户端,告诉用户我们正在排队处理,然后释放出资源来处理更多的请求。订票请求处理完之后,再通知客户端成功或者失败。
处理逻辑后移到异步处理程序中,Web服务的压力小了,资源占用的少了,自然就能接收更多的用户请求,系统承受高并发的能力也就提升了。
系统架构设计要灵活
一般系统的演进过程应该遵循下面的思路:
-
最简单的系统设计满足业务需求和流量现状,选择最熟悉的技术体系。
-
随着流量的增加和业务的变化,修正架构中存在问题的点,如单点问题,横向扩展问题,性能无法满足需求的组件。在这个过程中,选择社区成熟的、团队熟悉的组件帮助我们解决问题,在社区没有合适解决方案的前提下才会自己造轮子。
-
当对架构的小修小补无法满足需求时,考虑重构、重写等大的调整方式以解决现有的问题。
归根结底一句话:高并发系统的演进应该是循序渐进,以解决系统中存在的问题为目的和驱动力的。