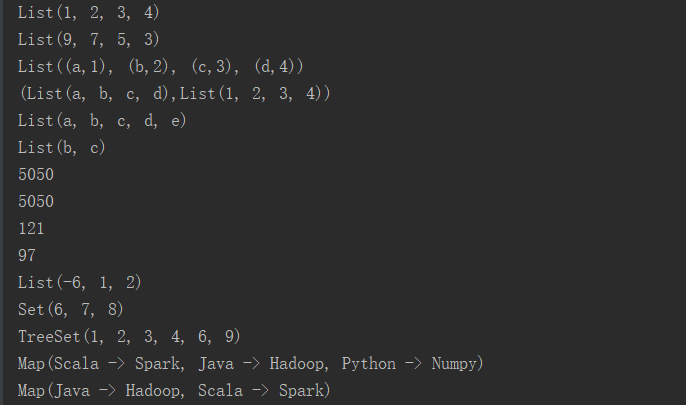
1 package big.data.analyse.dataSet 2 3 import scala.collection.immutable.{TreeMap, TreeSet} 4 import scala.collection.mutable._ 5 /** 6 * Created by zhen on 2018/11/18. 7 */ 8 object List_Set_Map { 9 def main(args: Array[String]) { 10 /** 11 * List基本操作 12 */ 13 println(List.range(1, 5)) 14 println(List.range(9, 1, -2)) 15 16 val zipped = "abcde".toList zip List(1, 2, 3, 4) 17 println(zipped) 18 println(zipped.unzip) 19 20 println(List(List('a', 'b'), List('c'), List('d', 'e')).flatten) 21 println(List.concat(List(), List('b'), List('c'))) 22 23 println((1 to 100).foldLeft(0)(_+_)) // 计算从1加到100 24 println((0 /: (1 to 100))(_+_))// 同上 25 26 println((1 to 6).foldRight(100)(_+_)) //倒序运算 27 println(((1 to 6):100)(_-_)) 28 29 println(List(1, -6, 2) sortWith(_<_)) //自定义排序 30 /** 31 * Set基本添加,删除操作 32 */ 33 val set = Set.empty[Int] 34 set ++= List(1, 2, 6, 8) // 添加多条数据 35 set += 7 // 添加单条数据 36 set --= Set(1, 2) // 删除多条数据 37 println(set) 38 /** 39 * TreeSet基本操作,自带排序 40 */ 41 val treeSet = TreeSet(6, 2, 1, 4, 9, 3) 42 println(treeSet) 43 /** 44 * Map基本添加,删除操作 45 */ 46 val map = Map.empty[String, String] 47 val add = Map.empty[String, String] 48 add("Java") = "Hadoop" 49 add("Python") = "Numpy" 50 map("Scala") = "Spark" // 添加单条数据 51 map ++= add // 添加多条数据 52 println(map) 53 /** 54 * TreeMap,自带排序 55 */ 56 val treeMap = TreeMap("Scala" -> "Spark", "Java" -> "Hadoop") 57 println(treeMap) 58 } 59 }
结果: