一.高亮简介
大多数的搜索应用都存在类似的情况,那就是搜索结果显示的屏幕空间有限。如果文档很短并可以在结果列表中显示全部内容,对屏幕空间显示就不会构成太大的问题。但大多数情况下都只能显示每个结果文档的一小部分。这就提出了一个问题:如何决定结果文档中显示哪一部分?理想情况下,应该是基于各片段与用户查询的匹配程度来决定。为查询结果选择最佳片段进行显示,这是Solr高亮框架提供的核心功能。
二.高亮工作原理
1.基本高亮

请注意,Solr返回的高亮片段在一个单独的元素中:<lst name="highlighting">。因此,客户端应用程序必须处理这些信息,才能对其进行显示。
2.每个结果生成多个高亮片段
在某些情况下,每个结果高亮显示一个片段,这可能还不足以为用户提供足够的上下文信息,让用户判断这个结果是否值得进一步研究。使用hl.snippets参数在该文档和结果中的其他文档中梳理出更多的上下文。hl.snippets=2代表允许每个文档最多高亮显示两个片段的显示结果。

正如搜索结果的其他高亮效果那样,设置hl.snippets=2并不能保证每个文档总能生成两个高亮片段。若结果中只有一个满足搜索条件,则只返回一个高亮片段。参数hl.snippets的值应被视为每个结果返回高亮片段的数量上限。
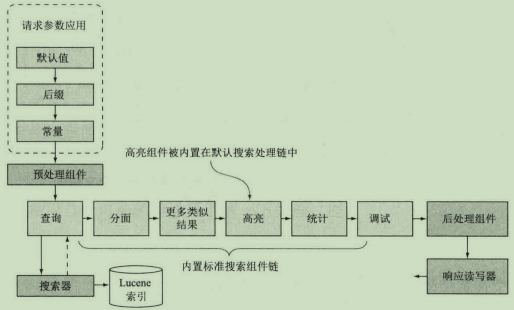
三.查询全流程分析
四.高亮内核分析
solrconfig.xml文件中定义了一个名为highlight的搜索组件,给出了高亮搜索组件的简要定义。
<!-- Highlighting Component http://wiki.apache.org/solr/HighlightingParameters --> <searchComponent class="solr.HighlightComponent" name="highlight"> <highlighting> <!-- Configure the standard fragmenter --> <!-- This could most likely be commented out in the "default" case --> <fragmenter name="gap" default="true" class="solr.highlight.GapFragmenter"> <lst name="defaults"> <int name="hl.fragsize">100</int> </lst> </fragmenter> <!-- A regular-expression-based fragmenter (for sentence extraction) --> <fragmenter name="regex" class="solr.highlight.RegexFragmenter"> <lst name="defaults"> <!-- slightly smaller fragsizes work better because of slop --> <int name="hl.fragsize">70</int> <!-- allow 50% slop on fragment sizes --> <float name="hl.regex.slop">0.5</float> <!-- a basic sentence pattern --> <str name="hl.regex.pattern">[-w ,/ "']{20,200}</str> </lst> </fragmenter> <!-- Configure the standard formatter --> <formatter name="html" default="true" class="solr.highlight.HtmlFormatter"> <lst name="defaults"> <str name="hl.simple.pre"><![CDATA[<em>]]></str> <str name="hl.simple.post"><![CDATA[</em>]]></str> </lst> </formatter> <!-- Configure the standard encoder --> <encoder name="html" class="solr.highlight.HtmlEncoder" /> <!-- Configure the standard fragListBuilder --> <fragListBuilder name="simple" class="solr.highlight.SimpleFragListBuilder"/> <!-- Configure the single fragListBuilder --> <fragListBuilder name="single" class="solr.highlight.SingleFragListBuilder"/> <!-- Configure the weighted fragListBuilder --> <fragListBuilder name="weighted" default="true" class="solr.highlight.WeightedFragListBuilder"/> <!-- default tag FragmentsBuilder --> <fragmentsBuilder name="default" default="true" class="solr.highlight.ScoreOrderFragmentsBuilder"> <!-- <lst name="defaults"> <str name="hl.multiValuedSeparatorChar">/</str> </lst> --> </fragmentsBuilder> <!-- multi-colored tag FragmentsBuilder --> <fragmentsBuilder name="colored" class="solr.highlight.ScoreOrderFragmentsBuilder"> <lst name="defaults"> <str name="hl.tag.pre"><![CDATA[ <b style="background:yellow">,<b style="background:lawgreen">, <b style="background:aquamarine">,<b style="background:magenta">, <b style="background:palegreen">,<b style="background:coral">, <b style="background:wheat">,<b style="background:khaki">, <b style="background:lime">,<b style="background:deepskyblue">]]></str> <str name="hl.tag.post"><![CDATA[</b>]]></str> </lst> </fragmentsBuilder> <boundaryScanner name="default" default="true" class="solr.highlight.SimpleBoundaryScanner"> <lst name="defaults"> <str name="hl.bs.maxScan">10</str> <str name="hl.bs.chars">.,!? 	 </str> </lst> </boundaryScanner> <boundaryScanner name="breakIterator" class="solr.highlight.BreakIteratorBoundaryScanner"> <lst name="defaults"> <!-- type should be one of CHARACTER, WORD(default), LINE and SENTENCE --> <str name="hl.bs.type">WORD</str> <!-- language and country are used when constructing Locale object. --> <!-- And the Locale object will be used when getting instance of BreakIterator --> <str name="hl.bs.language">en</str> <str name="hl.bs.country">US</str> </lst> </boundaryScanner> </highlighting> </searchComponent>
高亮组件位于查询处理链的下游,因此,高亮组件每次只能对一页搜索结果进行高亮处理。如果页面较大,比如1000,那么每次请求中高亮组件的处理量很大,这会对查询响应时间造成负面影响。
当需要使用多字段时,例如,数据包含title和body两个字段,并且打算在这两个字段上高亮显示查询词项。在这种情况下,需要设定hl.fl=title,body,这样就能在title和body字段上都进行高亮显示。
对于hl.fl列表的每个字段,高亮组件将根据hl.snippets参数来决定生成多少个高亮片段,该参数的默认值为1。Solr高亮组件的主要组成如下:
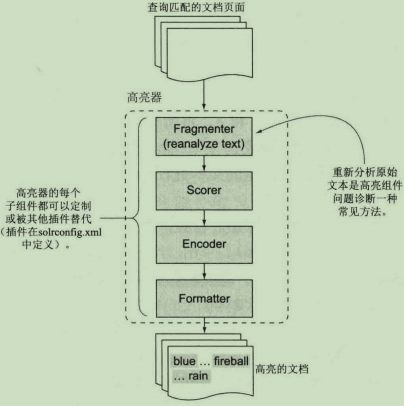
1.文本分析
在Solr高亮显示结果之前,它需要访问原始文本并将其存储起来。当Solr得到该字段的原始文本之后,它需要使用配置好的索引阶段分析器进行重新分析。对文档的原始文本重新进行分析主要有两个原因。首先,片段中的词项必须能与查询词项相比较。其次,Solr需要知道原始文本中词项的位置偏移量,以便它在片段中高亮显示词项。我们不希望Solr生成的高亮片段漏掉raining的结尾ing。因此,Solr需要知道原始文本中raining开始和结束的位置。位置偏移量很重要,通过它Solr才能知道什么时候该高亮显示一个短语,而不是短语的一部分。词项分析器如下:
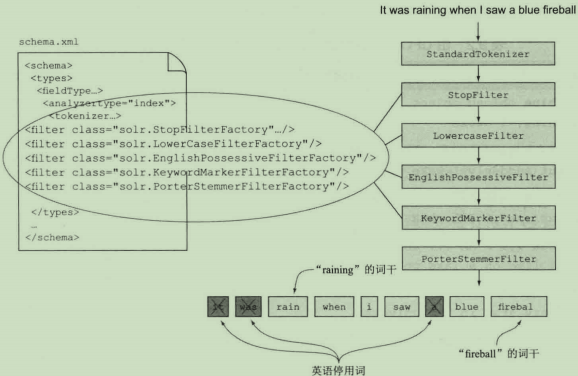
2.分段
分段是选择文本字段中零个或多个子片段进行高亮显示的过程。基于这一点,使用片段表示已排名和格式化的片段,这些片段得分足够高,在结果中得以返回。Solr把文本分隔成片段,每个片段产生一个分数,得分最高的前N个片段作为高亮显示片段被返回,这里的N由参数hl.snippets设定。
Solr有两个基本方法来实现分段,分别是GapFragmenter和RegexFragmenter。默认方式是GapFragmenter,它基于一个目标长度来选择片段。默认情况下,目标片段长度为100,也可以使用hl.fragsize参数进行修改。RegexFragmenter不会拆分分词来产生固定长度的片段,而GapFragmenter会在分词边界上创建片段。GapFragmenter得名于,它避免了在跨越较大位置间隔上创建片段。例如,在schema.xml文件中字段定义的positionIncrementGap属性上设置多值字段不同值之间的间隔。
RegexFragmenter通过正则表达式在文本中选择片段。
3.评分
分段组件使用了评分组件的子组件为片段评分。默认评分组件的实现方法【QueryScorer】会计算每个分段中出现了多少个查询词项。
4.编码与格式
hl.formatter参数指定了一个格式化组件,用来对词项进行高亮显示。默认格式化组件【hl.formatter=simple】将每个词项包含在任意一段文本中。这种方法适用于HTML标签来高亮显示查询词项。默认情况下,simple格式化组件将词项放在<em>标签中,也可以使用hl.simple.pre和hl.simple.post参数覆盖默认值。例如,如果想要使用层叠样式表对高亮词项进行格式化,在查询中添加一下参数即可:
hl.simple.pre=<span class="foo">&
hl.simple.post=</span>
在每个片段传递给格式化组件之前,编码组件需要对特殊字符进行编码。当生成一个HTML高亮片段时,HTML编码器将特殊字符转义为HTML字符实体引用。
五.优化高亮显示结果
1.与分面一起使用
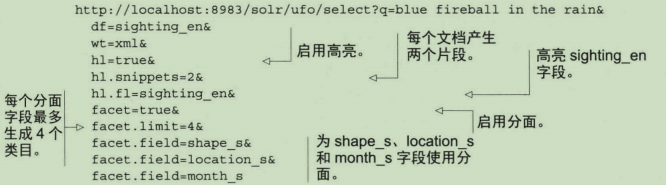
2.高亮显示短语
在后台,hl.usePhraseHighlighter参数控制这个行为,默认情况下它是启用状态。如果设置hl.usePhraseHighlighter=false,那么Solr可能返回单独高亮显示词项blue或fireball的片段。关键之处在于,Solr在高亮显示查询短语时处理得当。
3.高亮显示多值字段
略
4.高亮参数小结


5.字段级覆写
很多高亮组件的参数都可以进行字段级覆写。例如,搜索应用有title和body两个字段。标题总是很短,因而只要求产生一个片段;但是若想在较长的body字段上生成三个片段,只需要设置f.body.hl.snippets=3来覆写body字段的默认值1即可。一般情况下,在参数前添加f.fieldname对任意参数应用字段级覆写。