一.选择响应格式
XML是Solr的默认响应格式。从Solr的角度看,什么样的响应格式并不重要。Solr可以返回XML、JSON、Ruby、Python、PHP、二进制Java等,甚至是自定义格式。使用wt参数修改响应格式。Solr的wt参数的可用格式如下:

当需要更改Solr的响应格式时,需要在请求中将wt参数设置为你需要的类型。例如:
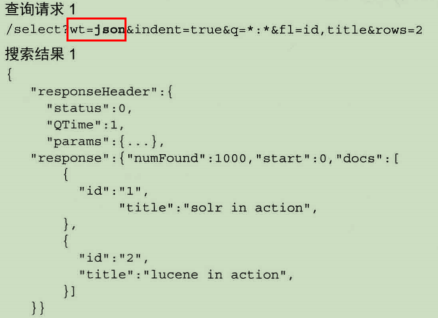
使用wt请求参数可以轻松地配置Solr的响应格式。如有需要,还可以为搜索应用编写专门的响应格式。为此,需要编写一个继承Solr的QueryResponseWriter的类。然后,在solrconfig.xml文件中注册该响应读写器。如下:

一般情况下没有必要专门开发一种响应格式,除非有特殊要求,例如需要对数据进行加密,或者需要对Solr返回的字段进行特别限制。
二.选择返回字段
1.返回存储字段
字段列表fl参数决定从Solr返回那些字段。字段列表定义了搜索结果中每个文档需要返回的字段,字段之间以逗号分隔,使用语法如下:

2.返回动态值
除了存储字段之外,文档还包含一种可以了解该文档的有用信息,即相关度得分。通过请求特殊的得分字段可以返回每个文档的相关度得分:
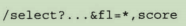 ————> score为伪列,即相关度得分
————> score为伪列,即相关度得分
3.文档转换
有时在最终文档写入Solr响应结果之前,获取文档的一些额外信息也是有帮助的。这些额外信息可能包含相关度得分如何计算的可读解释、分布式搜索中文档所在的分片,甚至是Lucene内部的文档编号。Solr使用文档转换器来返回此类信息。使用方法如下:

该请求调用了两个特殊字段:[explain]和[shard]。这些用方括号括起来的字段调用文档转换器会获得每个文档的一些元数据。Solr内置的常用文档转换器如下:

[docid]字段通常只用于需要与Lucene基础索引层面进行交互的情况中,这对大多数Solr用户来说是不常用的。
[shard]字段主要用于在分布式搜索中查找文档所在的Solr服务器和内核。
[explain]字段有助于理解文档相关度得分的计算原理。
[value]字段用于返回文档的静态值。
除了Solr内置的文档转换器,还可以通过继承org.apache.solr.response.transform.DocTransformer类,以插件方式编写自己的文档转换器,从而对整个文档进行操作与变换。要在Solr中使用自定义的文档转换器,需要创建一个工厂类来包装文档转换器,该工厂类继承自org.apache.solr.response.transform.TransformerFactory,使用时需要在solrconfig.xml中注册这个转换工厂类:

虽然文档转换器不是Solr最常用的功能,但它在搜索结果的文档返回之前,为文档操作提供了有用的扩展点。
4.返回字段的别名
除了通过动态生成值返回伪字段之外,在搜索结果的文档返回之前,Solr还提供了一种字段重命名方法。字段别名在实际字段名之前出现,使用冒号分隔,在搜索结果中使用一个新的字段来返回实际字段名【或动态生成值】的值,别名则作为新字段的名称,例如:

如果想要使用a_b_c【该文本字段既索引又存储】这样的动态字段来返回一个用户友好的字段名fleldname,字段别名方法在这里就能发挥作用。只需在字段列表中指定fieldname:a_b_c就可以了。另外,可以对任何字段以任何名称重命名【特殊名称除外】。
三.搜索结果分页
一个查询可能会匹配出大量文档,但是搜索结果通常以一页一页的方式显示给用户,每页包含一定数量的搜索结果。虽然Solr能够以毫秒级别对数百万或者数十亿文档进行高效地查询匹配,但它并没有对返回大量文档的处理方面进行优化。Solr返回数十个或数百个文档不在话下,但从千数量级开始,请求速度和吞吐速度会大幅降低。Solr的最佳实践是,首先只返回最相关的一页结果,然后允许用户继续获取后面的结果页面。这样做的话,Solr的每个请求都只返回有限数量的文档,避免了某个查询请求为了一次获取太多数据,占用资源并影响其他查询的执行速度的情况出现。
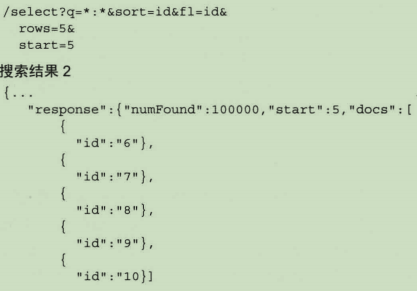
Solr的搜索结果分页需要使用两个请求参数:start和rows。start表示开始位置,从0开始。rows参数表示返回的文档数。例如:
四.搜索结果排序
搜索得到的结果按一定的次序返回。默认按关键词相关度得分进行排序,除此之外,日期、词项、数字以及函数等都可以作为排序依据。
1.按字段排序
执行关键词搜索,搜索结果默认按照文档的相关度得分以降序方式进行排序。对于相同得分的文档,根据搜索索引的Lucene内部文档编号以升序方式进行排序。如果没有相关度得分,则按Lucene内部文档编号进行排序。通过sort参数可以轻松地在搜索请求中修改默认排序。例如:

字段排序的语法是由字段和排序方向组成的列表,字段与排序方向之间使用空格分隔,各组字段排序之间使用逗号分隔。排序字段必须在schema.xml中标记为indexed=true,排序方向分asc和desc两种。
注意,字段不同语言的排序也不尽相同,Solr内置了针对特定语言排序的分词过滤器。如果字段使用这些分词过滤器,搜索结果的排序可能符合该语言规则,但与标准字符串字段的排序有所不同。
需要注意一点,由于排序使用了索引词项,如果修改了索引词项,而非字段的原始值,那么排序结果可能对用户而言没有意义。如果在Solr中进行词项替换,那么 最终的索引值【而非发送到Solr的原始值】将是排序的键。
对缺失值排序
还有一种特殊情况是,文档排序中sort字段缺少取值。由于Solr默认情况下不要求大多数字段都必备,因此很容易出现一个字段只有部分文档具备,在这种情况下,如果要对该字段进行排序,与查询相匹配但不包含该排序字段的文档应该出现在搜索结果列表中的前面还是后面?这个视情况而定,Solr提供了sortMissingLast和sortMissingFirst两个属性,用来选择合适的字段排序行为,这两个属性在schmea.xml中的定义如下:

solr 4.x及以前版本,设置麻烦且容易冲突
sortMissingLast属性设置为true,则不管排序方向如何,不包含该字段值的所有文档都会显示在搜索结果排序列表的末尾。sortMissingFirst与此类似。默认都为false。在默认设置下,缺少的文档会以升序显示在任何一种排序方式的开头,或以降序方式显示在任何一种排序方式的末尾。

solr 5.x及以后版本,默认为末尾。
排序的内存占用
排序是一个非常占用内存的过程。为了对文档进行排序,Solr使用Lucene的字段缓存,在首次请求排序时将字段的所有唯一值加载到内存中,可能也存在其他原因导致缓存已经被加载。这意味着,要对包含数百万个唯一词项的索引进行排序,每个排序字段都会消耗大量内存。首次请求字段排序时需要构建内存结构,这可能导致初始排序查询变慢。这里不是说不应该对文档进行排序,而是意识到,排序需要有足够的内存来执行排序。此外,可能需要预热Solr实例来实现缓存加载。
2.按函数排序
除了按字段排序,还可以根据函数查询的计算值进行排序。举例来说,根据距离某一点的地理位置【使用geodist函数】或文档的流行度与新旧程度【对流行度和日期字段使用数学函数】进行排序。甚至还可以将字段与函数排序结合起来,产生非常复杂的排序效果。
3.模糊排序
排序通常被认为是一个全有或全无的操作。事实上,通过Solr的相关度计算可以实现所谓的模糊排序。如果将相关度计算视为多因素的综合体,那么通过对其进行提升,可以区分出查询中每个因素的权重。
将一个查询元素的重要性相较于另一个查询元素提升数千倍,这是提升相关度得分的一种直接手段。这样做的话,首先会匹配第一个查询元素的文档,其次才会匹配第二个查询元素。如果将相关度得分之间的差异控制在一个范围内,则可以进行模糊排序。相关度得分的两部分通常一个高于另一个,有时候也会存在一些重合,导致得分较低的文档的相关度高于得分较低的文档。
模糊排序在大多数情况下更多的是一种相关度考虑,它有很多处理方法。在许多情况下,应该根据相关度进行排序,构造相应的查询,对返回文档以期望的次序进行排序,而不是使用字段硬排序技术。虽然有时两者都可以排序,但应该视搜索应用需求而定。
五.调试查询结果
如果你对搜索结果感到困惑。例如,查询解析问题导致产生多种搜索结果、相关度得分有时不显示、查询执行时间变长等。所幸,搜索处理器附带的特殊搜索组件DebugComponent可以帮助解决以上问题。
在Solr请求期间,要了解查询背后发生了什么,最简单的方法是开启调试选项,在请求中传入debug=true参数,激活DebugComponent,返回信息如下:
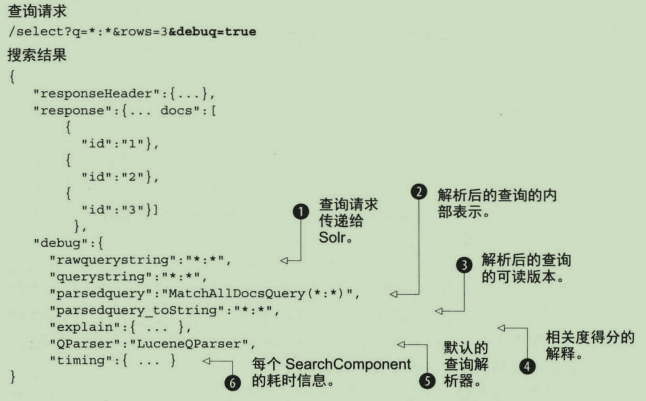
此外,在调试参数中还可以进一步指定返回的具体内容。与指定debug=true不同,如果指定debug=query,则只返回与查询解析器有关的部分调试信息。如果指定debug=results,则只返回相关度得分计算的解释内容。如果指定debug=timing,则只返回每个SearchComponent处理所花费的时间,这对调试执行较慢的请求很有帮助。