一.Flink新特性
1.支持Scala2.12
2.对SQL功能进行完善
a.Streaming SQL新增Temporal Tables【时态表】
时态表:时态表记录了数据改变的历史状态,该表可以返回特定时间点的表的内容。
b.Streaming SQL支持模式匹配
模式匹配:Flink CEP是Flink的复杂事件处理库。它允许在流上定义一系列的模式,最终使得可以方便的抽取自己需要的重要事件。
c.Streaming SQL支持更多特例,例如:REPLACE,REPEAT,LTRIM等函数
3.完善Kafka的最新连接器
二.Blink简介
阿里巴巴内部Flink版本Blink已经于2019年1月正式开源。Blink最显著的特点就是强大的SQL能力。
1.强大的流计算引擎
a.阿里云实时流计算提供Flink SQL,支持各种Fail场景的自动恢复、保证故障情况下数据处理的准确性。
b.支持多种内置函数,包括:字符串函数、日期函数、聚合函数等
c.精确的计算资源控制,高度保证公共云用户作业的隔离性。
2.关键性能指标为开源Flink的3~4倍,数据计算延迟优化到秒级甚至亚秒级。单个作业吞吐量可做到百万级别。单集群规模为数千台。
3.深度整合各类云数据存储。
三.Flink的编程模型和核心概念
1.基本概念
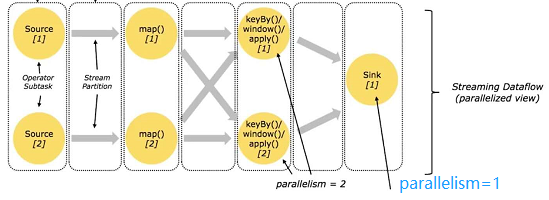
a.Dlink程序的基础构建模块是流【streams】与转换【transformations】。
b.每一个数据流起始于一个或多个source,并终止于一个或多个sink。

图解1,单并行度:

图解2,多并行度:
2.窗口window
a.流上的聚合需要由窗口来划定范围。比如:“计算最近五分钟”。
b.窗口通常被区分为不同的类型,比如:滚动窗口【没有重叠】、滑动窗口【有重叠】、以及会话窗口【有不活动的间隔所打断】。
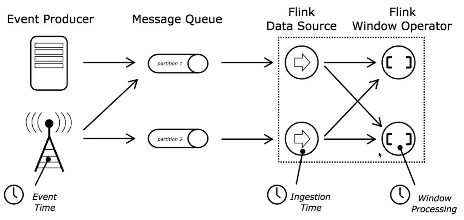
3.时间time
a.事件时间,指事件创建的时间。它通常由事件的时间戳描述,例如kafka消息中生成的时间戳。
b.摄入时间,是事件进入Flink数据流运算符的时间。
c.处理时间,是每一个执行时间操作的运算符的本地时间。
图解:
4.并行度
Flink程序由多个任务组成【source、transformation和sink】。一个任务由多个并行的实例【线程】来执行,一个任务的并行实例【线程】数目被称为该任务的并行度。
并行度级别:
a.算子级别,设置flink的编程API设置。
b.运行环境级别,设置executionEnvironment的方式设置并行度。
c.客户端级别,通过设置$FLINK_HOME/bin/flink的-p参数设置。
d.系统级别,设置$FLINK_HOME/conf/flink-conf.yaml文件。
并行度优先级:
算子级别>运算环境级别>客户端级别>系统级别
备注:并行度不能大于slot的个数!
四.Flink SQL代码实战
1.代码
package cn.sql import org.apache.flink.api.java.utils.ParameterTool import org.apache.flink.api.scala._ import org.apache.flink.table.api.TableEnvironment import org.apache.flink.types.Row // 样例类 case class Word(word : String, frequency : Int) /** * Created by Administrator on 2020/1/22. */ object WordCount { def main(args: Array[String]) { val params : ParameterTool = ParameterTool.fromArgs(args) // 设置execution执行环境 val env = ExecutionEnvironment.getExecutionEnvironment // 设置web界面有效参数 env.getConfig.setGlobalJobParameters(params) val tableEnv = TableEnvironment.getTableEnvironment(env) val text = "Apache Flink apache spark apache solr hbase hive flink kafka redis tachyon redis" val words = text.toLowerCase.split(" ").map(row => Word(row, 1)) val input = env.fromCollection(words) input.count() //val tableData = tableEnv.fromDataSet(input) //tableEnv.registerTable("WordCount", tableData) // 注册表 tableEnv.registerDataSet("WordCount", input) // 注册表 val table = tableEnv.sqlQuery( "SELECT word, SUM(frequency) as frequency FROM WordCount GROUP BY word") .filter("frequency > 1") // 过滤长度大于1 table.printSchema() val result = tableEnv.toDataSet[Row](table) // table转dataset。备注:必须添加[Row],否则报错 result.print() } }
2.执行结果
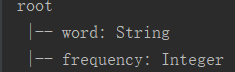
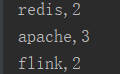
3.备注
table转dataset时一定要指定[Row],不然会报错,如下:
