一.简介
Solr的搜索主要由两个操作组成:找到与请求参数相匹配的文档;对这些文档进行排序,返回最相关的匹配文档。默认情况下,文档根据相关度进行排序。这意味着,找到匹配的文档集之后,需要另一个操作来计算每个匹配文档的相关度得分。
二.fq和q参数
为有效地查找匹配的文档和计算文档的相关度得分,Solr会用到两个参数:fq和q。fq参数表示过滤器查询,q参数表示查询。初看这两个参数可能不太好区分,因为相同的查询语法传递到这两个参数中会返回相同数量的文档。因此,许多搜索请求中只使用单个q参数。但是理解这两个参数之间的差异,可以更高效地进行搜索。
相关度影响
fq:对匹配的文档进行查询限定。
q:1.对匹配的文档进行查询限定;2.提供相关度算法以及用于相关度评分的词项列表;
因此,q参数可以被视为一个特殊的过滤器,告诉Solr在相关度计算时应考虑哪些词项。鉴于这种差异,Solr使用者倾向于将用户输入的关键词放入q参数中,将机器生成的过滤器放入fq参数中。
缓存和执行速度
从主查询中分离出过滤器查询有两种用途。首先,过滤器查询通常可以在不包含任何关键词的搜索之间重复使用。因此,可以考虑将过滤器查询的结果缓存在过滤器缓存中。其次,由于相关度评分操作必须对文档匹配的查询q中每个词项进行计算,那么将查询的一部分拆分成过滤器查询fq,fq参数这部分就无需进行额外的相关度计算。这样处理之后,查询中可作为过滤器的查询部分为相关评分计算节省了许多时间。
指定多个查询和过滤器
Solr请求中可以添加任意多个fq参数,但只能包含一个q参数。例如,两个Solr查询q=keywords:solr&fq=category:technology&fq=year:2020与q=keywords:solr&fq=category:technology AND year:2020会以同样的次序返回相同的结果文档。除了fq参数的缓存用途【每个fq参数可以独立缓存】,使用多个fq参数在功能上等价于将这些参数组合成一个fq参数。具体选择时要考虑相关度和缓存影响,根据实际情况选择使用哪一种参数和参数形式。
执行顺序
从技术角度:
1.在过滤器缓存中对每个fq参数进行查找。若存在,缓存的DocSet将被返回,以OpenBitSet的形式进行封装,其中索引里的每个文档对应一个二进制位【0或者1】,以表示该文档是否包含在过滤器中。
2.若没有在过滤器缓存中找到fq参数,但缓存已启用,那么该过滤器将对索引进行过滤,得到一个新的DocSet,这样就对其进行缓存。
3.所有过滤器的DocSet做交集【AND操作】,得到一个DocSet。
4.q参数与过滤器的DocSet一起传入,作为一个Lucene查询进行搜索。执行查询时,Lucene对查询与组合过滤器进行搭桥处理,将查询与过滤器对象统一成一个当前的内部ID【一个整数】。若查询结果和过滤器结果对象包含相同的ID,则收集该ID,处理过程包括为匹配的文档计算相关度得分。
5.如果文档包含任何后置过滤器,它们将作为收集过程的一部分,在查询与过滤器做了交集处理之后执行,仅作用于同时匹配组合查询和组合过滤器的文档。
所以,当缓存启用时,过滤器会先于主查询执行。查询和过滤器随后在收集过程中同时执行,后置过滤器作为一种特殊的过滤器,在查询和过滤器已经找到匹配的文档之后使用。查询和过滤器组合过程如下:
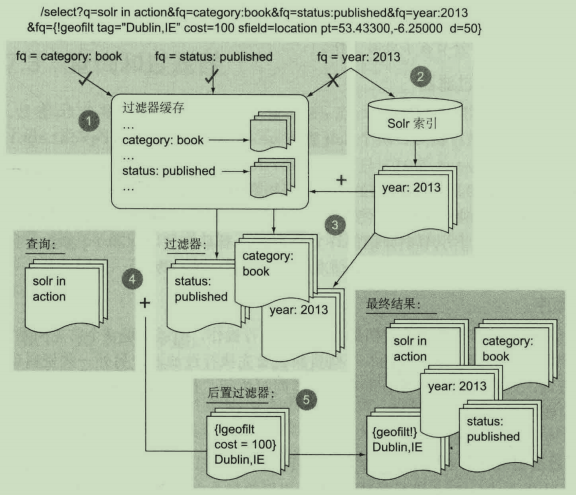
这看起来很复杂,其实确实如此。Solr很好地将这种复杂性隐藏了起来。不过,理解这个过程有助于对使用代价过高的过滤器进行性能优化。Solr提供了更为精细的控制,能够指定那些过滤器需要进行缓存,以及过滤器的执行顺序,包括在主查询之前、之后或同时进行。
三.处理代价过高的过滤器
对过滤器进行缓存和绕过查询中过滤器部分的相关度处理,这样可以大大节省处理时间。然而,并非所有的过滤器情况都一样。如果尝试对搜索结果进行指定经纬度的地理半径过滤,由于涉及数学计算,因此这个过滤器的计算成本可能很高。因此,如果要为数以万计的位置生成不同的过滤器的话,如此多的过滤器可能很难进行缓存。在某些应用中可能需要生成许多唯一过滤器,例如,对唯一ID进行过滤,造成过滤器缓存过载,导致常用的过滤器缓存被删除或搜索预热时间过长。对于这种情况,Solr能控制那些过滤器应该缓存,以及确定过滤器的执行顺序。
关闭过滤器缓存
在某些情况下,许多过滤器不需要进行缓存。由于过滤器数量存在上限,如果最常用的过滤器始终处于缓存状态,则Solr实例的性能最佳。为防止不重要的过滤器造成缓存过载,可以使用一下语法关闭某些过滤器缓存功能:
fq={!cache=false}id:123&...
改变过滤器执行顺序
如果搜索请求包含多个过滤器,它们的执行顺序会对查询速度产生显著影响。从一般逻辑上讲,能让结果集减少最多的过滤器应先执行,因为面对文档越少,过滤器执行速度越快。同样的道理,执行复杂计算的过滤器应考虑靠后执行。它们处理的文档越少,所消耗的计算资源也就相对越少。对于需要花费更多代价的过滤器,通过定义该过滤器相关的执行成本,Solr允许它们靠后执行。提供过滤器成本的语法如下:
fq={!cost=1}category:technology&...
执行成本不一定是连续的,彼此之间只是相对顺序。大于或等于100的执行成本会启用后置过滤!
后置过滤
在一些情况下,过滤器的执行成本会非常高,因此希望在所有其他查询和过滤器执行之后再执行它。Solr提供了一种特殊类型的过滤器,称为后置过滤器。此过滤器在查询和过滤相交处理之后使用。为过滤器定义cost参数,这是将一个过滤器转换为后置过滤器的一种方法。执行成本>=100的过滤器都被视为后置过滤器,使用后置过滤器接口执行。
Solr的后置过滤器不一定适用于所有类型的查询和过滤,它只适用于那些使用PostFilter接口的查询和过滤、FRange查询是具有后置过滤器功能的一种查询类型。另外,也可以编写插件来执行后置过滤器接口,在主查询和过滤器执行之后使用自定义的过滤器。