一.Solr请求概念
Solr最常见的请求类型是在Solr索引中查找相关文档的查询【query】。除此之外,Solr还可以处理许多不同类型的请求。所有的请求基本上都是通过请求处理器提交给Solr。搜索处理器【search handler】是查询处理的默认请求处理器,通过调用一个或多个搜索组件,每个组件处理搜索请求的一部分,从而满足查询各个阶段的要求。例如,通过搜索组件执行主查询,其中分面、搜索结果高亮和拼写检查都有各自的搜索组件。要让查询请求能够使用主搜索组件,需要通过一个或多个查询解析器对查询文本进行解析,其作用是理解查询语法,将其映射为适当的查询对象集,以便在Solr索引中找到相关文档集。
二.请求处理器
请求处理器【request handler】基本上是Solr所有请求的入口。它的作用是接受请求,执行某些功能,向客户端返回结果。Solr拥有许多请求处理器来完成完成各项任务。为简单起见,大多数请求处理器继承自RequestHandlerBase这个Java类,但这种做法并不是强制性的。SolrRequestHandler接口实现的任何类都可以作为一个请求处理器。虽然我们可以编写自己的请求处理器作为Solr的插件,实现SolrRequestHandler接口,但大多数Solr用户还是会使用Solr内置的请求处理器。如下图显示了大多数Solr内置请求处理器的继承关系:
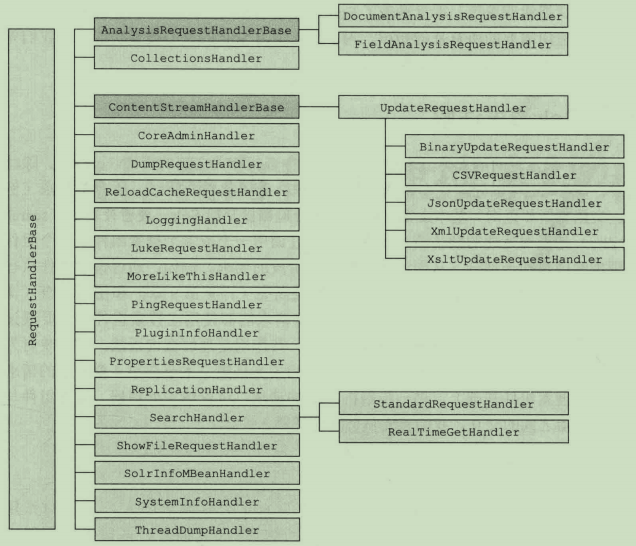
AnalysisRequestHandlerBase和ContentStreamHandlerBase是两个抽象类,所以不能直接引用。少数不是继承自RequestHandlerBase的内置请求器没有在这里列出。
SearchHandler作为Solr最常见的请求处理器,它是搜索请求处理的默认请求处理器。下图对每个请求处理器的常见用法做了简单介绍:




如下配置示例,启用了更新文档的UpdateRequestHandler,从一台服务器向另一台服务器复制文件的ReplicationHandler,以及几个用于搜索的SearchHandler实例:
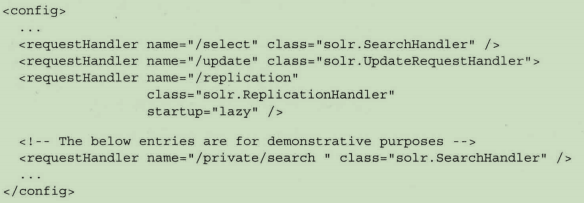
定义一个请求处理器时,需要指定两个属性:name和class。Solr维护了一个请求请求处理器查找列表,根据每个请求的指定要求,派发对应的请求处理器。class属性对应特定的Java类【SolrRequestHandler接口实现】,使用指定名称的请求处理器处理查询请求。
如果请求处理器的名称以反斜杠/开头【标准做法】,name就使用该请求处理器的相对URL。
三.搜索组件
SearchHandler是执行搜索的默认响应处理器,搜索默认会返回什么?是否只包含搜索结果?有没有匹配到的最相关类目,或是对匹配到的文档的部分文本进行高亮?如果只匹配到很少结果或没有结果,可供选择的拼写建议是否可以作为默认请求的一部分返回?
从上面的介绍可知,许多搜索功能可以通过发送单独的、可用的请求来调用多个请求处理器来实现。理想情况下,向Solr发送一个情况,就能得到所有预期的结果。这正是搜索组件存在的原因。
搜索组件是在搜索处理器生命周期内发生的可配置的处理步骤。搜索组件让搜索处理器将实现单个搜索请求的可重用的功能组合在一起。搜索组件在solrconfig.xml中进行配置。默认搜索组件如下:
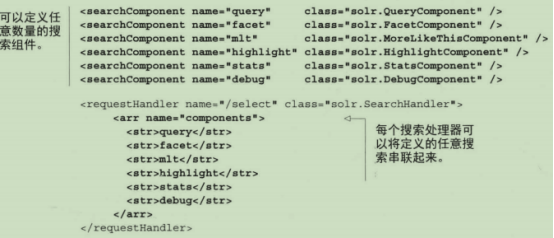
在第一个searchComponent标签中定义了两个属性,一个是name,另一个是class。name的值是query,class的值是solr.QueryComponent。该搜索组件只需定义一次,之后它可以被任意数量的请求处理器调用。在/select请求处理器中,会看到一个arr元素,其属性name为components。该元素包含了搜索处理器定义的搜索组件列表。components部分的每一行对应一个搜索组件名称,既可以是默认的搜索组件,也可以是solrconfig.xml中定义的其他搜索组件。
请求处理器和搜索组件的默认设置
请求处理器和搜索组件通常从以下两种来源接收请求设置:
- 在Solr的URL中传递代码以及查询字符串变量
- 在solrconfig.xml中配置一个请求处理器或搜索组件时,通过设置变量自动添加到每个请求,就像在Solr的URL中传递一样。配置如下:

搜索组件添加了两个部分:invariants部分和defaults部分。如果Solr的请求URL里没有重写值,defaults部分就是默认值。如果想要执行安全默认设置,查询搜索组件的q=*:*确保不会发生意外或者避免没有结果返回的情况,这种情况下defaults默认值就是有用的。
invariants部分与defaults部分类似,只不过Solr请求URL中常量参数无法被重写。关键词搜索的默认字段是df=content_field。
大多数搜索组件支持在它们的XML配置中设置相应的属性。即使默认搜索组件没有在solrconfig.xml中明确定义,它们也是默认存在的。还可以通过添加first-components和last-components来插入搜索组件,这两部分表示分别在搜索处理器执行的组件列表的开始或结束处插入附加组件。
在搜索处理器的所有搜索组件中,查询组件是最重要的。因为它负责查询的初始化执行和搜索结果的特定格式响应,而且随后的其他搜索组件需要在它的基础上执行。查询组件使用查询解析器对搜索处理器请求中的传入查询进行解析。Solr支持多种查询查询解析器。
四.查询解析器
查询解析器将lucene查询解释成搜索语法,以便查找所需的文档集。Solr支持多种查询解析器,还支持用户编写自己的查询解析器。如搜索组件专门用于单个请求处理器,查询解析器也是专门用于单个搜索组件的。如下:

Solr提供了许多查询解析器,每个查询解析器实现了一个QParserPlugin类。如果已有的查询解析器无法实现你需要的查询解析功能,可以自定义。Solr最常见的查询解析器是Lucene查询解析器【LuceneQParserPlugin】和eDisMax查询解析器【ExtendedDismaxQParserPlugin】。
查询解析器的使用
执行搜索时,QueryComponent根据查询解析器传递的值处理初始的用户查询,LuceneQParserPlugin是Solr的默认查询解析器。该默认查询解析器可以很容易地进行替换,也可以在同一个查询里与多个查询解析器组合使用。每个查询解析器执行各自的查询类型,支持对应的查询语法,对应不同的使用场景。
指定查询解析器
QueryComponent的默认查询解析器类型可以使用搜索请求中的defType参数进行修改,例如:
/select?defType=edismax&q=...
/select?defType=term&q=...
修改默认查询解析器类型会对处理参数q的查询解析器进行更改,从而导致查询结果的变化。除了修改默认查询解析器类型外,还可以使用Solr的特殊语法修改查询中使用的查询解析器,例如:
/select?q={!edismax}hello word
/select?q={!term}hello
/select?q={!edismax}hello word OR {!lucene}title:"ma title"
第三个查询调用两个不同的查询解析器【edismax和lucene】。与使用defType参数相比,这是查询中指定查询解析器的优势所在。{!查询解析器名称}语法通过行内定义查询解析器来调用Solr的某一功能,这称为局部参数。
局部参数
局部参数为特定上下文提供定制化请求参数。通常的做法是在URL里向Solr提交请求参数,但有时也可以在查询内的特定部分指定一些参数。在一个查询中,局部参数可以只为特定查询解析器传递请求参数,而不是全局传递所有请求参数。局部参数不仅可以修改查询解析器,还可以修改任何请求参数。
局部参数语法
局部参数是一组用来表示请求参数的键值对集合,只限于当前上下文有效。其语法如下:
{!param1=value1 param2=value2 ... paramN=valueN}
局部参数以{!开头,以}结尾,包含以空格分隔的键值对列表,其中键值由等号分隔。例如:
/select?q=hello word&defType=edismax&qf=title^10 text&q.op=AND
等价于
/select?q={!defType=edismax qf="title^10 text" q.op=AND}hello word
这两个查询的本质局部在于,第一个例子中所有请求参数都是全局的,因此它们可以用于请求中的任何位置。在局部参数的例子中,defType、qf和q.op参数只能在参数q范围内使用。如果需要在查询中多次使用不同配置的一个查询解析器,使用局部参数就可以实现。
我们可以在局部参数中指定defType参数,也可以使用type参数改写defType参数。从字面上看,defType表示默认类型,也就是说,它为所有查询指定了默认查询解析器类型。在局部参数中使用type参数可以修改特定上下文里的默认类型,例如:
/select?q={!type=edismax qf="title^10 text" q.op=AND}hello word
type参数仅在局部参数中使用,如果要在顶层定义一种类型作为默认类型,则必须使用defType参数。与之相对,defType参数既可以用于请求层次,又可以用于局部参数。由于一些局部参数值可能包含特定字符【空格、引号等】,所有需要用单引号或双引号将局部参数包括起来,或者需要对特殊字符进行转义。上面的例子中存在空格,所以使用双引号将其括起来。
在本节中,我们指定{!type=edismax...},之前我们使用了更简单的{!edismax...}。如果关键词搜索不指定字段的话,默认在默认字段上搜索,也有可能在局部参数中传递值,将它用于type默认局部参数的键。因为局部参数的语法较短,所以查询解析器的定义一般使用{!queryParserName}语法,其它局部参数则必须使用完整的{!key1=value1 key2=value2 ...}语法。
参数解引用
参数解引用提供了查询中任意变量的替换方法。这个功能类似于SQL的参数查询,可以不使用查询语法来单独定义查询输入。引用参数的语法如下:
/select?q={!edismax v=$userQuery}&userQuery="hello word"
在这个例子中,userQuery参数作为用户定义的查询字段变量传递给Solr,而Solr本身不能理解该参数。通过将eDisMax查询解析器的传入值指定为解引用参数$userQuery,该值可以放在请求的其他位置。初次使用可能觉得其发挥作用有限,但由于在solrconfig.xml中为每个请求处理器和查询组件使用默认值,追加值或常量定义了默认参数,可以为自己的搜索应用指定一组请求参数集替换预设配置。