一.索引存储
当文档提交到索引之后,directory目录组件会将它们写入到持久化存储器。Solr的目录组件具有以下重要特点:
1.隐藏持久存储的读写细节,例如,将文档写入到磁盘或通过JDBC在数据库中存储文档。
2.实现特定的存储锁定机制,防止索引出错。例如,在操作系统级别上基于文件系统的存储锁定。
3.将Solr从JVM和操作系统的专有性中解脱出来。
4.启用基础目录方案的扩展机制,以支持特定应用,如近实时搜索。
Solr提供了不同的目录方案,但没有所谓的适用于所有Solr装机情况的最佳目录方案。根据Solr应用的具体情况,思考如何确定最佳方案。实践中取决于操作系统本身、JVM类型及应用场景等。
二.默认存储配置
默认情况下,Solr为一个内核设置一个数据目录,将数据存储在本地文件系统中。默认情况下,将索引数据存储在conf配置目录同级的data目录下。在Solr4.x及之前的版本中,可以直接配置Solr core的一些基本信息,如下:
<core loadOnStartup="true" instanceDir="collection1/" transient="false" name="collection1" dataDir="/usr/local/solr-data/collection1" />
但是在之后版本就不建议这样配置,随着版本更新,新版本逐渐从之前的单机Solr转向SolrCloud集群,在集群模式中,索引数据的配置都是一直的,不需要单独指定。
首先要考虑,索引的数据目录是否有足够的存储容量。此外,数据目录支持快速读写也是非常重要的,其中对读性能要求更高【Solr的目的是快速查询而不是批量更新】。因此,在设置Solr时需要考虑一下问题:
1.每个内核不应与其他进程争夺磁盘空间。
2.如果同一台服务器上有多个内核,建议为每个索引单独设置独立的物理磁盘进行存储。
3.如果预算允许,考虑使用高质量、高速磁盘,如固态硬盘SSD。
4.考虑服务器RAID【磁盘阵列】策略对Solr的影响。
5.操作系统中用于缓存的内存容量也会对磁盘I/O需求产生不可小觑的影响。
三.选择一个目录方案
一旦解决了存储方面的问题,还需要考虑存储方案的最佳目录方案。Solr使用solr.NRTCachingDirectoryFactory启用默认目录,在solrconfig.xml中配置<directoryFactory>元素来指定此目录。
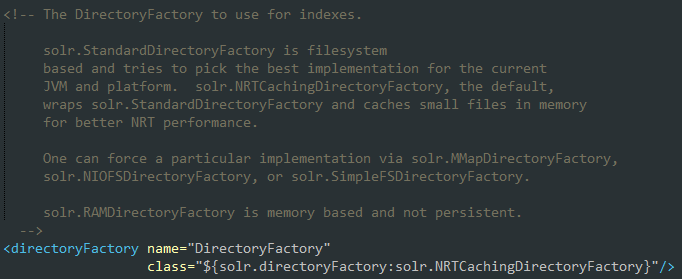
NRTCachingDirectoryFactory是solr.StandDirectoryFactory的一个封装类,用来添加对近实时搜索的支持。在运行时,StandardDirectoryFactory根据操作系统与JVM类型来选择一个具体的目录方案。
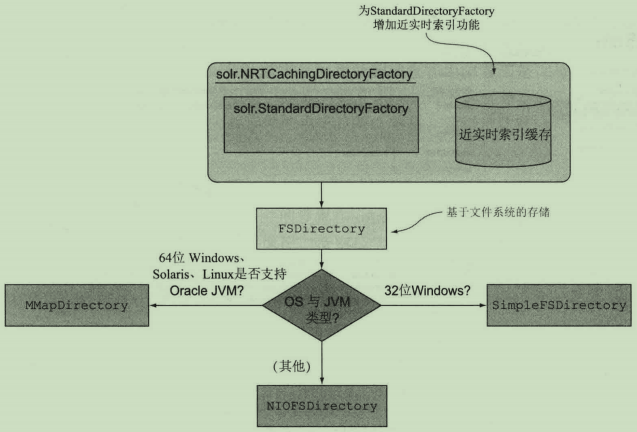
详解:
1.MMapDirectory:读取索引时使用内存映射I/O。这是安装了Oracle JVM的64位Windows、Solaris或Linux类操作系统的最佳选择。
2.SimpleFSDirectory:使用Java的RandomAccessFile方法。除非是32位Windows操作系统,否则应避免使用此方法。
3.NIOFSDirectory:通过java.nio进行优化,以避免同一个文件的同步读操作。这是JVM长期存在的一个问题,应避免在Windows上使用此方法。
通过Solr控制台的内核管理页,可以看见Solr服务器指定的数据目录【单机模式】:
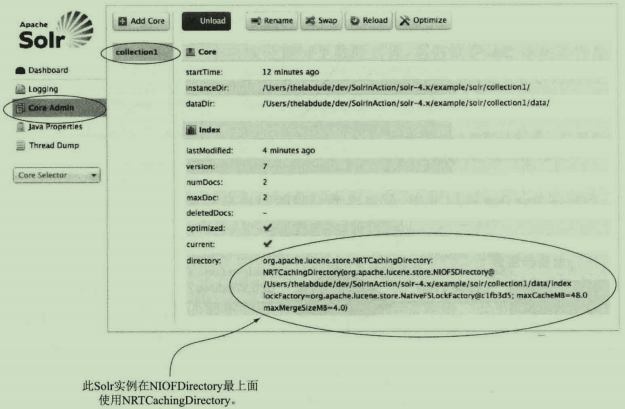
注意,在SolrCloud集群模式时是看不到这是设置的!
四.索引片段合并
索引片段是Lucene完整索引的子集,具有自包含和只读特点。索引片段写入持久存储器之后,它就无法再改变。向索引添加新文档时,它们被写入到一个索引片段中。因此,索引里可能存在许多活动的索引片段。每个查询必须读取了全部索引片段里面的数据,才能得到完整的搜索结果集。基于这一点考虑,过多的小片段会对查询性能产生负面的影响。因此,将小索引片段进行合并就是必然的举措,这种做法称为索引片段合并。
1.索引是否需要优化
优化要求Lucene将已有的索引片段合并成一定数量【默认值为1】的大索引片段。在Solr中,优化会对内存、CPU和磁盘I/O消耗很大,特别是对大索引而言。花费数小时对一个大索引进行全面优化,这是很常见的。
是否需要优化索引是Solr用户要考虑的问题。这可以理解,谁不想要一个优化好的索引?但是,Solr技术社区对此的建议和当前的看法是,与其对索引进行优化,不如微调Solr的索引合并策略。此外,优化过的索引并不能迅速提高查询速度。相反,未优化索引的查询性能也不是那么糟糕,因此,是否优化还要根据实际情况来定。
2.专家级索引片段合并设置
默认情况下,有关索引片段合并的设置在solrconfig.xml中被注释掉了。这样做的原因是,默认设置适用于大多数情况,特别是学习Solr的入门阶段。应该注意,每个元素都被标记为专家级别的设置。
solrconfig.xml具体参数配置如下:

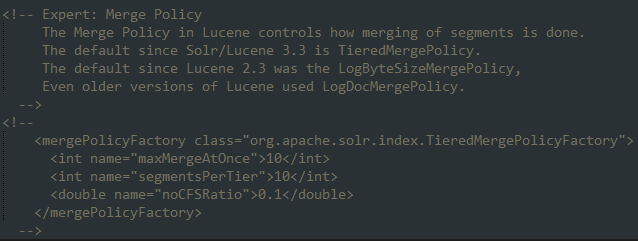
详细解释如下:

注意,在新版Solr【5.x之后】中mergePolicy改为mergePolicyFactory,mergeFactor被去掉!
这里需要明确,尽管这些专家级设置被注释掉了,但仍然能在后台进行索引片合并。当前的建议是,除非有充分理由去修改这些设置,否则跳过优化,直接使用索引片段合并的默认设置即可。当服务器该做索引片段合并时,很可能不作为就是最正确的选择。
3.删除处理
当索引片段写入持久存储器之后就不能更改了。那么,此处的删除并不是从已有的索引片段中删除文档。删除的文档不会从索引中消失,除非包含删除的索引片段被合并。简言之,Lucene将删除操作记录在一个单独的数据结构中,合并时执行这些删除操作。大多数情况下无需担心合并过程。