一.缓存原理
缓存,带来急速性能体验!

Solr提供了一系列的内置缓存来优化查询性能。Solr的缓存原理主要涉及以下4个方面:
1.缓存大小及缓存置换法
从缓存大小的角度来看,不能将缓存设置的太大,否则它会消耗JVM大量的内存。Solr能将所有的缓存对象都保存到内存中,不会溢写到磁盘中。为了控制缓存大小,Solr要求为每一个缓存都设置一个缓存对象的数量上限。当达到上限时,Solr将会采用最久未使用【Least Recently Used, LRU】置换法或最近最少使用【Least Frequently Used, LFU】置换法回收一部分缓存空间。
最久未使用置换法在缓存大小达到阈值上限时,根据缓存对象最后一次被请求的时间来决定缓存对象被回收的次序。当缓存区达到上限,需要添加新的对象时,LRU置换法将置换缓存中最久未被使用的对象。LRU置换法是Solr的默认缓存置换算法。同时,Solr还提供了最近最少使用置换法LFU,该方法根据缓存对象被请求频率的高低决定缓存对象被回收的次序。这种置换法给与缓存中使用频率高的对象更高的优先级,而不是最近被请求的对象。Solr的过滤器缓存使用的是LFU置换法。因为过滤查询的创建和存储都是很耗费资源的,所以需要尽量降低过滤器缓存的存储大小,并且给予应用中频繁使用的过滤器更高的优先级。
在缓存大小这有一个常见的误区,就是内存空间越大,缓存就设置的越大。这样做存在的问题是,一旦某个缓存在一次提交操作之后失效了,JVM就需要做大量的垃圾回收工作。且关闭一个搜索器会使得该搜索器缓存的所有对象都失效。如果没有根据垃圾回收的实际情况对缓存大小进行合适的调整,就可能导致服务器因垃圾回收时间过长而导致长时间停止服务。因此,现阶段最重要的是避免定义过大的缓冲区,并且要对缓存对象进行周期性回收。
2.缓存命中率与缓存回收
缓存命中率是指应用程序的缓存命中的用户请求数量占所有用户请求数量的比例。缓存命中率表明了缓存对应用程序的性能优化所起到的作用。理想情况下,希望缓存命中率尽量接近1【100%】,低缓存命中率表明缓存对Solr的性能优化没有起到多大作用。
缓存回收数表明有多少缓存对象被缓存置换法回收了。如果回收量很大,则表明应用程序的缓存对象的最大值可能设置的太小。缓存回收数和缓存命中率是紧密相关的,低的缓存回收数往往代表一个较好的缓存命中率。
3.缓存对象失效
在大多数的缓存管理场景中,开发者需要考虑如何使一个缓存对象失效,这样应用程序才不会返回过时的数据。在Solr中完全不需要考虑这一点,因为所有的缓存中的对象都会链接到对应的搜索器实例,并且在搜索器关闭后立即失效。搜索器只是Lucene索引快照的一个只读视图,因此,所有的缓存对象在搜索器关闭之前都是有效的。
4.自动预热新缓存
Solr在每次提交请求之后都会创建一个新的搜索器,并且直到新搜索器完成预热,才会关闭旧搜索器。Solr利用即将被关闭的旧搜索器中的部分缓存构成新搜索器的缓存,这个过程称为自动预热。每一个Solr的缓存都支持autowarmCount属性,这个属性表示自动预热的旧缓存对象的最大数目或百分比。缓存对象自动预热策略取决于缓存的具体类型。
百度、谷歌搜索在缓存这一块也有类似的设计,像分页,延迟加载等,特别是在查询结果缓存、查询窗口缓存和查询结果最大缓存数方面更是如此。
二.过滤器缓存
在Solr中,过滤器将搜索结果限制在符合过滤条件的文档集中,但是它并不影响文档的评分。在执行过滤查询时,Solr会计算并缓存一个合适的数据结构,找到索引中符合过滤条件的文档。当其它查询用到了缓存的数据集时,查询效率会大幅提高,这就是Solr过滤缓存设计的初衷。而且,过滤器在不同查询语句中间是可以复用的。

自动预热过滤器缓存
过滤器查询是优化查询语句的强大工具,但是如果开发者对过滤器缓存管理不当,则会陷入麻烦中。如果索引中索引了大量的文档或者过滤条件非常复杂,那么创建和存储过滤器将会耗费大量的系统资源。如果一个简单的过滤查询能够被复用多次,那么这个过滤查询的缓存便是有意义的。
缓存中的每一个对象都有一个键,对于过滤缓存来说,这个键就是过滤查询语句。预热新的缓存时,一部分键将从旧的缓存中抽取出来,向新搜索器提交查询,形成新的过滤器。要利用新搜索器自动预热过滤器缓存,就需要Solr重新执行过滤查询。因此,自动预热过滤器缓存可能导致Solr在性能和资源利用方面出现问题。特别是Solr提交更改频繁的应用程序,因为后台并发预热的搜索器太多了。
建议开发者为过滤器缓存启用自动预热功能,但是给autowarmCount设一个较小值作为初始值。除此之外,LFU置换法更适合过滤器缓存,因为它能保证被请求频率高的过滤器赋予较高优先级,同时降低过滤器缓存的大小。推荐的过滤器缓存配置:

开发者需要在此配置的基础上,根据应用程序实际使用的过滤器数量和对索引提交更新的频率进行试验,以得到最佳配置。
从每个过滤器缓存的内存使用情况来看,根据匹配文档集合的大小,Solr有不同的过滤表示方法。至于最大阈值,可以设定为每个过滤匹配文档集合中的MaxDoc值。例如,如果索引文件索引了1000万份文档,那么一个过滤器缓存可能占用一千万比特的内存,及1.2M左右。
三.查询结果缓存
查询结果缓存会将查询结果集保存在缓存中。当重复执行相同查询时,后面的查询结果都是第一次查询结果的缓存,而不是重新对Lucene索引执行查询。对于需要消耗大量计算资源的查询来说,这是一种非常高效的解决方案。查询结果缓存的定义如下:
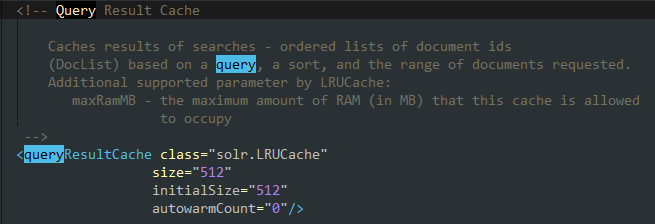
该方案背后的原理是将查询语句作为键,内部Lucene文档ID作为值,存储在查询结果缓存中。内部Lucene文档ID会随着搜索器的改变而改变,所以在预热查询结果缓存时,缓存的内部Lucene文档ID需要重新计算。同过滤器缓存一样,预热查询结果缓存Solr需要重新执行查询语句,这可能需要消耗大量的资源。因此建议将autowarmCount设为一个较小值。这样可以通过自动预热最近的查询语句缓存来提高应用程序的性能。
四.查询结果窗口大小
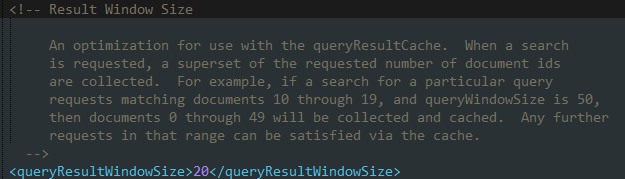
分页对提高Solr的查询性能有重要意义。<queryResultWindowSize>允许在执行查询请求时定义单次返回查询结果的数据条数。假设应用程序每页显示10份文档,用户都只浏览第一页和第二页。那么可以把此参数设置为20,这样可以避免用户在查看第二页时再次执行查询请求。一般情况下会将这个参数值设置为每页查询结果数量的二到三倍。如果用户很少查看除第一页之外的内容,最好将该参数设置为页数据大小,避免返回过多数据。
五.查询结果缓存的最大文档数
<queryResultMaxDocsCached>参数对查询结果缓存中的每一个缓存对象包含的文档数目做出了限制。在大多数搜索应用中,用户一般仅查看前几页的搜索结果,所以可以将这个值设为每页结果文档数目的二到三倍。

六.启用字段延迟加载
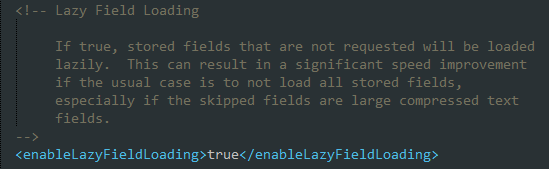
Solr中一种常见的设计模式是只返回用户查询请求中要求的字段,而不是返回所以的字段。如果采用这种设计模式,需要将参数<enableLazyFieldLoading>设置为true,这样就可以避免加载用户不需要的字段。在实际应用中,只返回用户需要的字段是一种高效的设计模式。
七.文档缓存
查询结果缓存只缓存了一组符合查询条件的文档的内部ID,所以即使查询结果被缓存了,Solr还是需要从磁盘上加载这些文档内容。文档缓存以文档的内部ID为键,将磁盘中的文档内容加载到缓存中。这样查询结果缓存可以直接从文档缓存中调用需要的文档内容。但文档缓存只在索引更新频率很低的情况下才适用,因为缓存文档需要耗费大量的内存,频繁的更新索引会导致频繁缓存文档,得不偿失。
八.字段值缓存
主要受Lucene控制,不是由Solr来管理。字段值缓存提供了通过内部文档ID快速访问存储的字段值的途径,主要在排序和从匹配文档中生成响应内容时使用。